(https://github.com/MLEveryday/100-Days-Of-ML-Code.git)
說明:文章中的python代碼大部分來自於github(少數是學習時測試添加),所附筆記為學習時注。
導入需要的庫–>導入數據集–>處理丟失數據–>解析分類數據–>拆分數據集為測試集合和訓練集合–>特征縮放
#Day1:Data Prepocessing
#2019.1.26-27,2019.2.9
#coding=utf-8
import warnings
warnings.filterwarnings("ignore")
#Step 1:Importing the libraries
import numpy as np
import pandas as pd
#Step 2:Importing dataset
dataset = pd.read_csv('C:/Users/Ymy/Desktop/100-Days-Of-ML-Code/datasets/Data.csv')
#測試
#loc['a']--通過 行標簽 索引行數據 選擇范圍是——閉區間
X = dataset.loc[0:1]
print(X)
print("-----------")
#iloc['number']--通過 行號(從0開始) 索引行數據 選擇范圍是——前閉後開區間
#如果[]內為具體數字,則選擇行號為此數的一行
X = dataset.iloc[0:1]
print(X)
print("-----------")
#iloc[:,a:b]/loc[:,a:b] 表示索引列數據,用法同行索引
#如果a省略不寫,默認為0
X = dataset.iloc[:,:2]
print(X)
print("-----------")
#.values 表示取值
X = dataset.iloc[:,:-1].values
print(X)
print("-----------")
#正式導入X,Y
X = dataset.iloc[:,:-1].values
Y = dataset.iloc[:,3].values
print("Step 2: Importing dataset")
print("X")
print(X)
print("Y")
print(Y)
#Step 3:Handling the missing data
#scikit-learn模型中都是假設輸入的數據是數值型的,
#並且都是有意義的,如果有缺失數據是通過NAN,或者空值表示的話,
#就無法識別與計算了
#Imputer類可以用於彌補缺失值,並且只能彌補數值型的缺失數據
''' Imputer類的說明: strategy : string, optional (default="mean") The imputation strategy. 均值策略- If "mean", then replace missing values using the mean along the axis. 中位數 - If "median", then replace missing values using the median along the axis. 眾數 - If "most_frequent", then replace missing using the most frequent value along the axis. '''
from sklearn.preprocessing import Imputer
#axis=0,表示對每一列進行這個操作;
#axis=1,表示對每一行進行這個操作;
#對數據中的空值("NaN")彌補
imputer = Imputer(missing_values = "NaN",strategy = "mean",axis = 0)
#對X中的1、2列處理
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
#此時的輸出中的nan值被數據彌補
print("---------------------")
print("Step 3: Handling the missing data")
print("X")
print(X)
#Step 4:Encoding categorical data
print("---------------------")
print("Step 4: Encoding categorical data")
#LabelEncoder:標簽編碼 從0開始編碼,n個取值,編碼為0~(n—1)
''' OneHotEncoder:獨熱編碼 將離散型特征使用one-hot編碼, 會讓特征之間的距離計算更加合理。對於離散的特征基本 就是按照one-hot(獨熱)編碼,該離散特征有多少取值, 就用多少維來表示該特征 2個取值: [1,0]:0/[0,1]:1 3個取值:[1,0,0]:0/[0,1,0]:1/[0,0,1]:2 4個取值:[1,0,0,0]:0/[0,1,0,0]:1/[0,0,1,0]:2/[0,0,0,1]:3 以此類推...(此處的數字0、1、2、3等均表示種類) '''
#導入sklearn 中的Imputer 類,在sklearn 的 preprocessing 包下
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
labelencoder_X = LabelEncoder()
#對X的第一列進行標簽編碼,一共3個取值:0,1,2
X[:,0] = labelencoder_X.fit_transform(X[:,0])
print("X的第一列進行標簽編碼")
print(X)
#dummy variables:虛擬變量,也叫啞變量和離散特征編碼,
#可用來表示分類變量、非數量因素可能產生的影響
#Creating a dummy variable
''' categorical_features表示對哪些特征進行編碼 通過索引或bool值來確定 如 OneHotEncoder(categorical_features = [0,2]) 等價於 [True, False, True] 即對0、2兩列進行編碼 ps:如果原數據包含三列,選中0、2列進行編碼時,輸出數據每一項會把沒有編碼“1”列數據 放在最後 '''
#選擇第一列進行編碼
onehotencoder = OneHotEncoder(categorical_features = [0])
#將X的第一列,包含3個國家的取值,使用三維向量表示
X = onehotencoder.fit_transform(X).toarray()
#對Y進行標簽編碼(NO:0;Yes:1)
#下面兩句可以簡寫成: Y = LabelEncoder().fit_transform(Y)
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
print("X")
print(X)
print("Y")
print(Y)
print("---------------------")
print("test")
#測試
a = OneHotEncoder(categorical_features = [0,2])
b = a.fit([[1,2,3],[2,3,4],[3,4,5]])
c = b.transform([[1,3,5]]).toarray()
#d = a.fit_transform([[1,2,3],[2,3,4],[3,4,5]]).toarray()
print(c)
#print(d)
#Step 5:Splitting the datasets into training sets and Test sets
print("---------------------")
print('Step 5: Splitting the datasets into training sets and Test sets')
from sklearn.model_selection import train_test_split
#X_train,X_test, y_train, y_test =
#cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
''' 參數解釋: train_data:所要劃分的樣本特征集 train_target:所要劃分的樣本結果 test_size:樣本占比,如果是整數的話就是樣本的數量 random_state:是隨機數的種子 cross_validatio為交叉驗證 '''
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2,random_state = 0)
''' 解釋: 此方法將X,Y分別劃分成X(Y)_train, X(Y)_test 兩部分 其中,X_test占X總數的20%,X_train占剩余的80% 此例中,X_test包含X中的2組數據,X_train包含剩余的8組 Y同理 '''
print("X_train")
print(X_train)
print("X_test")
print(X_test)
print("Y_train")
print(Y_train)
print("Y_test")
print(Y_test)
Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license()" for more information.
>>>
RESTART: C:\Users\Ymy\Desktop\100-Days-Of-ML-Code\Code\Day 1_Data_Preprocessing.py
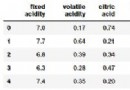
Step 2: Importing dataset
X
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 nan]
['France' 35.0 58000.0]
['Spain' nan 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]
Y
['No' 'Yes' 'No' 'No' 'Yes' 'Yes' 'No' 'Yes' 'No' 'Yes']
Warning (from warnings module):
File "D:\python\lib\site-packages\sklearn\utils\deprecation.py", line 58
warnings.warn(msg, category=DeprecationWarning)
DeprecationWarning: Class Imputer is deprecated; Imputer was deprecated in version 0.20 and will be removed in 0.22. Import impute.SimpleImputer from sklearn instead.
---------------------
Step 3: Handling the missing data
step2
X
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 63777.77777777778]
['France' 35.0 58000.0]
['Spain' 38.77777777777778 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]
Warning (from warnings module):
File "D:\python\lib\site-packages\sklearn\preprocessing\_encoders.py", line 368
warnings.warn(msg, FutureWarning)
FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values.
If you want the future behaviour and silence this warning, you can specify "categories='auto'".
In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly.
Warning (from warnings module):
File "D:\python\lib\site-packages\sklearn\preprocessing\_encoders.py", line 390
"use the ColumnTransformer instead.", DeprecationWarning)
DeprecationWarning: The 'categorical_features' keyword is deprecated in version 0.20 and will be removed in 0.22. You can use the ColumnTransformer instead.
---------------------
Step 4: Encoding categorical data
X
[[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.40000000e+01
7.20000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 2.70000000e+01
4.80000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 3.00000000e+01
5.40000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.80000000e+01
6.10000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 4.00000000e+01
6.37777778e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.50000000e+01
5.80000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.87777778e+01
5.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.80000000e+01
7.90000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 5.00000000e+01
8.30000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.70000000e+01
6.70000000e+04]]
Y
[0 1 0 0 1 1 0 1 0 1]
---------------------
Step 5: Splitting the datasets into training sets and Test sets
X_train
[[0.00000000e+00 1.00000000e+00 0.00000000e+00 4.00000000e+01
6.37777778e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.70000000e+01
6.70000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 2.70000000e+01
4.80000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.87777778e+01
5.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.80000000e+01
7.90000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.80000000e+01
6.10000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.40000000e+01
7.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.50000000e+01
5.80000000e+04]]
X_test
[[0.0e+00 1.0e+00 0.0e+00 3.0e+01 5.4e+04]
[0.0e+00 1.0e+00 0.0e+00 5.0e+01 8.3e+04]]
Y_train
[1 1 1 0 1 0 0 1]
Y_test
[0 0]
---------------------
Step 6: Feature Scaling
X_train
[[-1. 2.64575131 -0.77459667 0.26306757 0.12381479]
[ 1. -0.37796447 -0.77459667 -0.25350148 0.46175632]
[-1. -0.37796447 1.29099445 -1.97539832 -1.53093341]
[-1. -0.37796447 1.29099445 0.05261351 -1.11141978]
[ 1. -0.37796447 -0.77459667 1.64058505 1.7202972 ]
[-1. -0.37796447 1.29099445 -0.0813118 -0.16751412]
[ 1. -0.37796447 -0.77459667 0.95182631 0.98614835]
[ 1. -0.37796447 -0.77459667 -0.59788085 -0.48214934]]
X_test
[[-1. 2.64575131 -0.77459667 -1.45882927 -0.90166297]
[-1. 2.64575131 -0.77459667 1.98496442 2.13981082]]
>>>
注:
由於python版本變化,原代碼中Step 4:Encoding categorical data 部分中獨熱編碼的函數用法發生變化,在2月9號測試時已經無法正常使用,文中的運行輸出結果為函數庫變化前的運行結果。此外,運行結果中含有的部分warning大多為版本變化後部分函數聲明或是使用上發生變化產生的警告。