This blog explains scrapy Agent related knowledge points in .
Programmers who write crawler code , Never get around is to use a proxy , During coding , You will encounter the following situations :
The test site still uses http://httpbin.org/, By visiting http://httpbin.org/ip Can get the current request IP Address .
HttpProxyMiddleware Middleware is enabled by default , You can view its source code, focusing on process_request() Method .
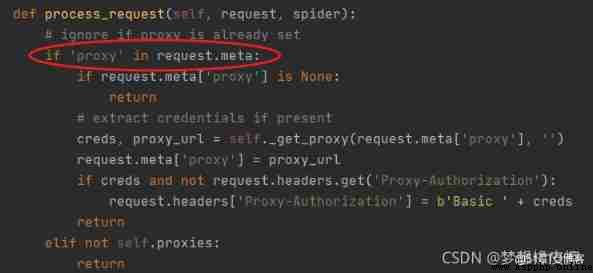
The way to modify the proxy is very simple , Only need Requests When requesting creation , increase meta Parameters can be .
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/ip']
def start_requests(self):
yield scrapy.Request(url=self.start_urls[0], meta={'proxy': 'http://202.5.116.49:8080'})
def parse(self, response):
print(response.text)
Next, by getting https://www.kuaidaili.com/free/ The agent of the website IP, And test whether its agent is available .
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/']
def parse(self, response):
IP = response.xpath('//td[@data-title="IP"]/text()').getall()
PORT = response.xpath('//td[@data-title="PORT"]/text()').getall()
url = 'http://httpbin.org/ip'
for ip, port in zip(IP, PORT):
proxy = f"http://{ip}:{port}"
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
}
yield scrapy.Request(url=url, callback=self.check_proxy, meta=meta, dont_filter=True)
def check_proxy(self, response):
print(response.text)
Next, the available agents IP Save to JSON In file .
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/']
def parse(self, response):
IP = response.xpath('//td[@data-title="IP"]/text()').getall()
PORT = response.xpath('//td[@data-title="PORT"]/text()').getall()
url = 'http://httpbin.org/ip'
for ip, port in zip(IP, PORT):
proxy = f"http://{ip}:{port}"
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
'_proxy': proxy
}
yield scrapy.Request(url=url, callback=self.check_proxy, meta=meta, dont_filter=True)
def check_proxy(self, response):
proxy_ip = response.json()['origin']
if proxy_ip is not None:
yield {
'proxy': response.meta['_proxy']
}
At the same time to modify start_requests Method , obtain 10 Page proxy .
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
url_format = 'https://www.kuaidaili.com/free/inha/{}/'
def start_requests(self):
for page in range(1, 11):
yield scrapy.Request(url=self.url_format.format(page))
It is also easier to implement a custom proxy middleware , There are two ways , The first kind of inheritance HttpProxyMiddleware, Write the following code :
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from collections import defaultdict
import random
class RandomProxyMiddleware(HttpProxyMiddleware):
def __init__(self, auth_encoding='latin-1'):
self.auth_encoding = auth_encoding
self.proxies = defaultdict(list)
with open('./proxy.csv') as f:
proxy_list = f.readlines()
for proxy in proxy_list:
scheme = 'http'
url = proxy.strip()
self.proxies[scheme].append(self._get_proxy(url, scheme))
def _set_proxy(self, request, scheme):
creds, proxy = random.choice(self.proxies[scheme])
request.meta['proxy'] = proxy
if creds:
request.headers['Proxy-Authorization'] = b'Basic ' + creds
The code core rewrites __init__ Construction method , Rewrite the _set_proxy Method , Random proxy acquisition is implemented .
Synchronous modification settings.py Code in file .
DOWNLOADER_MIDDLEWARES = {
'proxy_text.middlewares.RandomProxyMiddleware': 543,
}
Create a new proxy middleware class
class NRandomProxyMiddleware(object):
def __init__(self, settings):
# from settings Read the agent configuration in PROXIES
self.proxies = settings.getlist("PROXIES")
def process_request(self, request, spider):
request.meta["proxy"] = random.choice(self.proxies)
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.getbool("HTTPPROXY_ENABLED"):
raise NotConfigured
return cls(crawler.settings)
You can see this class from settings.py In the document PROXIES Reading configuration , Therefore, modify the corresponding configuration as follows :
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
'proxy_text.middlewares.NRandomProxyMiddleware': 543,
}
# The code is the result of the previous code collection
PROXIES = ['http://140.249.48.241:6969',
'http://47.96.16.149:80',
'http://140.249.48.241:6969',
'http://47.100.14.22:9006',
'http://47.100.14.22:9006']
If you want to test reptiles , Can write a random return request agent function , Use it on any crawler code , Complete the task of this blog .
I collected this blog 400, Update the next one now
Today is the first day of continuous writing <font color=red>261</font> / 200 God .
Sure <font color=#04a9f4> Focus on </font> I ,<font color=#04a9f4> give the thumbs-up </font> I 、<font color=#04a9f4> Comment on </font> I 、<font color=#04a9f4> Collection </font> It's me .