Following yesterday's article Windows Download installation configuration SQL Server、SSMS, Use Python Connect to read and write data , We've installed and configured sqlserver, Also successfully tested how to use Python Connect 、 Read and write data to the database .
Today we officially begin to meet the demand : There's a lot of Excel, It needs batch processing , Then store it in different data tables .
1) excel What data needs to be modified ?
DocketDate yes excel Short time value , Need to change to the normal format ; eg. 44567 --> 2022/1/6SOID Carry out repeated processing , according to DocketDate Keep recent data ;Mainly involves : Date format processing 、 Data De reprocessing
2) every last Excel Do they all correspond to a different data table ? The name of the table and Excel Whether the attachment names are consistent ?
Mainly involves : Data consolidation processing
pip3 install sqlalchemy pymssql pandas xlrd xlwt
Import package :
import pandas as pd from datetime import date, timedelta, datetime import time import os from sqlalchemy import create_engine import pymssql
Reading data is relatively simple , Call directly pandas Of read_excel Function , If the file has any special format , Like coding , You can also customize settings .
# Read excel data def get_excel_data(filepath): data = pd.read_excel(filepath) return data
“1) Date days are shortened ”
This is difficult ,excel It's easy to turn directly in , Directly select the data to be transferred , And then at the beginning - Select a short date in the data format column .
At that time, I didn't know the transformation law at first sight , Searched for a long time , No similar problems or explanations were found , First of all, it's definitely not a timestamp , It always feels a little related , Finally, it was found that the number of days , To calculate the Day calculation start date You can solve other data transformation problems .
First, we need to judge the null value , Set the start date... And then calculate the start date , utilize datetime Modular timedelta The function converts the number of days of time into a time difference , Then directly calculate with the start date to get the date it represents .
# Date days are shortened def days_to_date(days): # Handle nan value if pd.isna(days): return # 44567 2022/1/6 # Extrapolate excel Days are shortened It's from 1899.12.30 Start calculating start = date(1899,12,30) # take days convert to timedelta type , It can be calculated directly with the date delta = timedelta(days) # Start date + Time difference Get the corresponding short date offset = start + delta return offset
What's hard to think about here is Day calculation start date , But after you figure it out , Actually, it's good , from excel In, we can directly convert the date days into short dates , The equation already exists , There is only one unknown x, We only need to formulate a univariate equation to solve the unknowns x.
from datetime import date, timedelta date_days = 44567 # Convert days to date type interval delta = timedelta(date_days) # Result date result = date(2022,1,6) # Calculate unknown start date x = result - delta print(x) ''' Output :1899-12-30 '''
“2) Turn the English of the date into numbers ”
At first I wanted to use regular matching , Take out the month, year and day , Then turn the English month into a number , Later, it was found that the English month can be directly recognized in the date .
The code is as follows , First, convert the string into date type data in format , The original data is 06/Jan/2022 12:27( Digital day / English month / Digital year Digital hours : Digital minutes ), Format the symbol according to the date and replace the corresponding relationship in the explanation table .
# Convert official date format to common format def date_to_common(time): # Handle nan value if pd.isna(time): return # 06/Jan/2022 12:27 2022-1-6 # test print(time,':', type(time)) # Convert string to date time_format = datetime.strptime(time,'%d/%b/%Y %H:%M') # Convert to specified date format common_date = datetime.strftime(time_format, '%Y-%m-%d') return common_date
Date formatting symbol interpretation table @CSDN- The messenger of rowing
“3) By order number SOID duplicate removal ”
To repeat here, in addition to removing the duplicate according to the specified column , You also need to keep the latest data by date .
My idea is , First call pandas Of sort_values The function sorts all data in ascending order according to the date column , then , call drop_duplicates The function specifies to press SOID Train for de duplication , And designate keep The value is last, Indicates that the last row of data is retained in the duplicate data .
The code is as follows :
# Remove duplicate values SOID repeat Remove the earliest data by date def delete_repeat(data): # Start by date Docket Rec.Date & Time Sort Default descending Make sure the date left is the latest data.sort_values(by=['Docket Rec.Date & Time'], inplace=True) # Press SOID Delete duplicate lines data.drop_duplicates(subset=['SOID #'], keep='last', inplace=True) return data
“ Multiple Excel The data corresponds to a database table ”
You can write a dictionary , To store database tables and corresponding data Excel Data name , Then store them one by one in the corresponding database table ( Or after processing the data in advance , Re merger ).
# Merge data with the same table Incoming merge excel list def merge_excel(elist, files_path): data_list = [get_excel_data(files_path+i) for i in elist] data = pd.concat(data_list) return data
The same type is passed in here Excel List of filenames (elist) And data storage folders / Relative paths (files_path) that will do , Absolutely... Through the file / Relative paths +Excel You can get the file name Excel Absolute of data table file / Relative paths , Call again get_excel_data Function to read and fetch data .
Traversal read Excel Table data uses list derivation , The use of pandas Of concat Function to merge the corresponding data .
# Initialize the database connection engine
# create_engine(" Database type + Database driven :// Database user name : Database password @IP Address : port / database ", The other parameters )
engine = create_engine("mssql+pymssql://sa:[email protected]/study?charset=GBK")
# Store the data
def data_to_sql(data, table_naem, columns):
# A little more processing of the data , Select the specified column and save it into the database
data1 = data[columns]
# The first parameter : Table name
# The second parameter : Database connection engine
# The third parameter : Whether to store index
# Fourth parameter : If the table exists Just append data
t1 = time.time() # Time stamp Unit second
print(' Data insertion start time :{0}'.format(t1))
data1.to_sql(table_naem, engine, index=False, if_exists='append')
t2 = time.time() # Time stamp Unit second
print(' Data insertion end time :{0}'.format(t2))
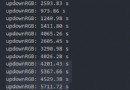
print(' Successfully inserted data %d strip ,'%len(data1), ' Time consuming :%.5f second .'%(t2-t1))
sqlalchemy+pymssql Connect sqlserver Pay attention to the pit : To specify the database code ,slqserver The default database created is GBK code , About sqlserver After installation, you can view the article Windows Download installation configuration SQL Server、SSMS, Use Python Connect to read and write data .
'''
Batch process all excel data
'''
# Data files are stored in a specified directory , Such as :
files_path = './data/'
bf_path = './process/'
# Get the names of all files in the current directory
# files = os.listdir(files_path)
# files
# Table name : The attachment excel name
data_dict = {
'testa': ['test1.xls', 'test2.xls'],
'testb': ['test3.xls'],
'testc': ['test4.xls']
}
# Select the specified column in the attachment , Store only the data in the specified column
columns_a = ['S/No', 'SOID #', 'Current MileStone', 'Store In Date Time']
columns_b = ['Received Part Serial No', 'Received Product Category', 'Received Part Desc']
columns_c = ['From Loc', 'Orig Dispoition Code']
columns = [columns_a, columns_b, columns_c]
flag = 0 # Column selection mark
# Ergodic dictionary Merger related excel Then process the data , Deposit in sql
for k,v in data_dict.items():
table_name = k
data = merge_excel(v, files_path)
# 1、 Processing data
if 'SOID #' not in data.columns:
# Contains no columns to process , Then simply remove the weight 、 Store in database
data.drop_duplicates(inplace=True)
else:
# Special data processing
data = process_data(data)
# 2、 Store the data
# Be on the safe side Save one locally
data.to_excel(bf_path+table_name+'.xls')
# Store in database
data_to_sql(data, table_name, columns[flag])
flag+=1