這是一個excel表格,有1k條數據
鏈接
1000條患者病症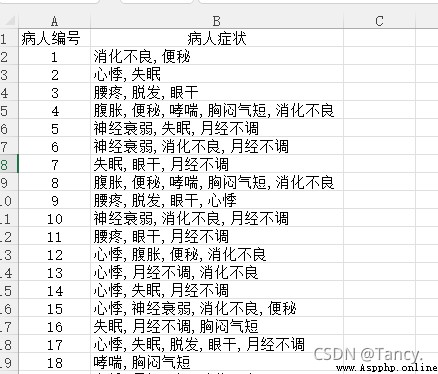
直接輸出了強關聯規則
更多的內容,在代碼裡面設置
比如看頻繁項集,可以自己取消注釋代碼再運行
# -*- codeing = utf-8 -*-
# @Time : 2021/11/26 22:41
# @Author : Tancy
# @File : 病例分析-- Apriori算法.py
# @Software : PyCharm
# 1.數據讀取
import pandas as pd
df = pd.read_excel('D:\A_學習\數據倉庫與數據挖掘\實驗\患者病症.xlsx')
# print(df.head())
# 2. 數據預處理
symptoms = [] # 創建一個空列表 病症
# 切分 轉化為一個二維數組
for i in df['病人症狀'].tolist():
symptoms.append(i.split(','))
# print(symptoms)
# 將數據轉化為布爾類型
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder() # 構造轉換類型
data = TE.fit_transform(symptoms) # 轉換為一個布爾類型的表格
# print(data)
# 將布爾類型的數據存儲為DataFrame 格式
import pandas as pd
df = pd.DataFrame(data, columns=TE.columns_)
# print(df.head())
# 3.挖掘頻繁項集
from mlxtend.frequent_patterns import apriori
items = apriori(df, min_support=0.15, use_colnames=True)
# print(items)
# print(items[items['itemsets'].apply(lambda x:len(x))==1])
# print(items[items['itemsets'].apply(lambda x:len(x))==2])
# print(items[items['itemsets'].apply(lambda x:len(x))==3])
# print(items[items['itemsets'].apply(lambda x:len(x))==4])
# 4.根據最小置信度,在頻繁項集中找強關聯規則
from mlxtend.frequent_patterns import association_rules
rules = association_rules(items, min_threshold=0.6)
# print(rules)
# 5.提取關聯規則,美化
for i, j in rules.iterrows():
X = j['antecedents']
Y = j['consequents']
x = ', '.join([item for item in X])
y = ', '.join([item for item in Y])
print(x + ' → ' + y)