This is a excel form , Yes 1k Data
link
1000 A patient's condition 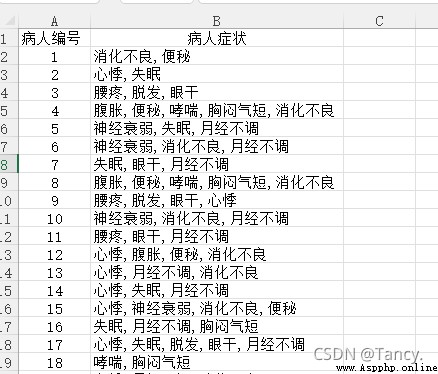
Output strong association rules directly 
More content , Set in the code
For example, look at Frequent itemsets , You can uncomment the code yourself and run it again
# -*- codeing = utf-8 -*-
# @Time : 2021/11/26 22:41
# @Author : Tancy
# @File : Case analysis -- Apriori Algorithm .py
# @Software : PyCharm
# 1. data fetch
import pandas as pd
df = pd.read_excel('D:\A_ Study \ Data warehouse and data mining \ experiment \ Patient symptoms .xlsx')
# print(df.head())
# 2. Data preprocessing
symptoms = [] # Create an empty list Illness
# segmentation Into a two-dimensional array
for i in df[' Patient symptoms '].tolist():
symptoms.append(i.split(','))
# print(symptoms)
# Convert data to boolean type
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder() # Construct conversion type
data = TE.fit_transform(symptoms) # Convert to a Boolean table
# print(data)
# Store Boolean data as DataFrame Format
import pandas as pd
df = pd.DataFrame(data, columns=TE.columns_)
# print(df.head())
# 3. Mining frequent itemsets
from mlxtend.frequent_patterns import apriori
items = apriori(df, min_support=0.15, use_colnames=True)
# print(items)
# print(items[items['itemsets'].apply(lambda x:len(x))==1])
# print(items[items['itemsets'].apply(lambda x:len(x))==2])
# print(items[items['itemsets'].apply(lambda x:len(x))==3])
# print(items[items['itemsets'].apply(lambda x:len(x))==4])
# 4. According to the minimum confidence , Find strong association rules in frequent itemsets
from mlxtend.frequent_patterns import association_rules
rules = association_rules(items, min_threshold=0.6)
# print(rules)
# 5. Extract association rules , beautify
for i, j in rules.iterrows():
X = j['antecedents']
Y = j['consequents']
x = ', '.join([item for item in X])
y = ', '.join([item for item in Y])
print(x + ' → ' + y)