前言
場景一:數據不需要頻繁的寫入mysql
場景二:數據是增量的,需要自動化並頻繁寫入mysql
總結
前言Python 讀取數據自動寫入 MySQL 數據庫,這個需求在工作中是非常普遍的,主要涉及到 python 操作數據庫,讀寫更新等,數據庫可能是 mongodb、 es,他們的處理思路都是相似的,只需要將操作數據庫的語法更換即可。本篇文章會給大家系統的分享千萬級數據如何寫入到 mysql,分為兩個場景,兩種方式。
場景一:數據不需要頻繁的寫入mysql使用 navicat 工具的導入向導功能。支持多種文件格式,可以根據文件的字段自動建表,也可以在已有表中插入數據,非常快捷方便。
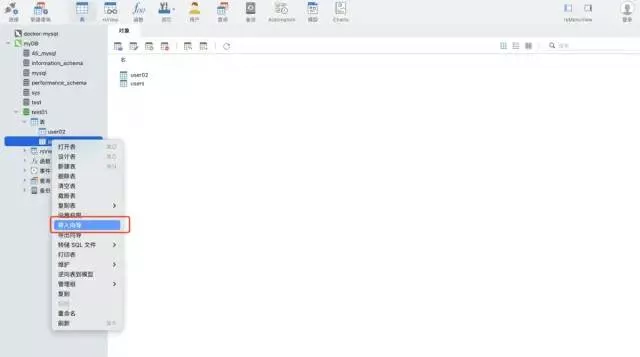
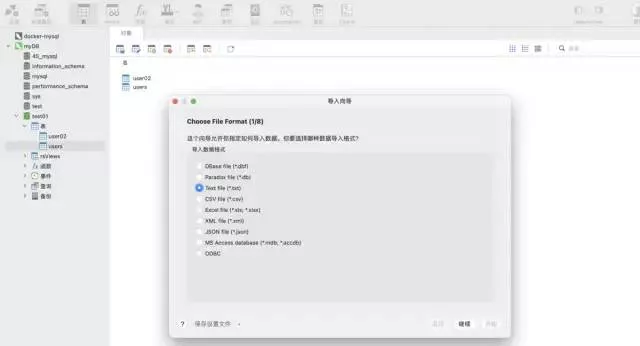
測試數據:csv 格式 ,大約 1200萬行
import pandas as pddata = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')data.shape打印結果:

方式一:python pymysql 庫
安裝 pymysql 命令:
pip install pymysql代碼實現:
import pymysql# 數據庫連接信息conn = pymysql.connect( host='127.0.0.1', user='root', passwd='wangyuqing', db='test01', port = 3306, charset="utf8")# 分塊處理big_size = 100000# 分塊遍歷寫入到 mysqlwith pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader: for df in reader: datas = [] print('處理:',len(df))# print(df) for i ,j in df.iterrows(): data = (j['user_id'],j['item_id'],j['behavior_type'], j['item_category'],j['time']) datas.append(data) _values = ",".join(['%s', ] * 5) sql = """insert into users(user_id,item_id,behavior_type ,item_category,time) values(%s)""" % _values cursor = conn.cursor() cursor.executemany(sql,datas) conn.commit() # 關閉服務conn.close()cursor.close()print('存入成功!')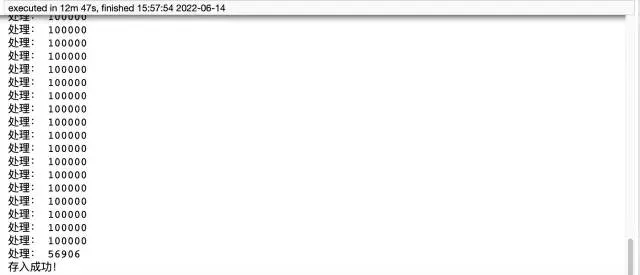
方式二:pandas sqlalchemy:pandas需要引入sqlalchemy來支持sql,在sqlalchemy的支持下,它可以實現所有常見數據庫類型的查詢、更新等操作。
代碼實現:
from sqlalchemy import create_engineengine = create_engine('mysql+pymysql://root:[email protected]:3306/test01')data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')data.to_sql('user02',engine,chunksize=100000,index=None)print('存入成功!')總結pymysql 方法用時12分47秒,耗時還是比較長的,代碼量大,而 pandas 僅需五行代碼就實現了這個需求,只用了4分鐘左右。最後補充下,方式一需要提前建表,方式二則不需要。所以推薦大家使用第二種方式,既方便又效率高。如果還覺得速度慢的小伙伴,可以考慮加入多進程、多線程。
最全的三種將數據存入到 MySQL 數據庫方法:
直接存,利用 navicat 的導入向導功能
Python pymysql
Pandas sqlalchemy
到此這篇關於Python 讀取千萬級數據自動寫入 MySQL 數據庫的文章就介紹到這了,更多相關Python 讀取數據內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!