Scrapy 是用 Python 實現的一個為了爬取網站數據、提取結構性數據而編寫的應用框架。
Scrapy 常應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
通常我們可以很簡單的通過 Scrapy 框架實現一個爬蟲,抓取指定網站的內容或圖片。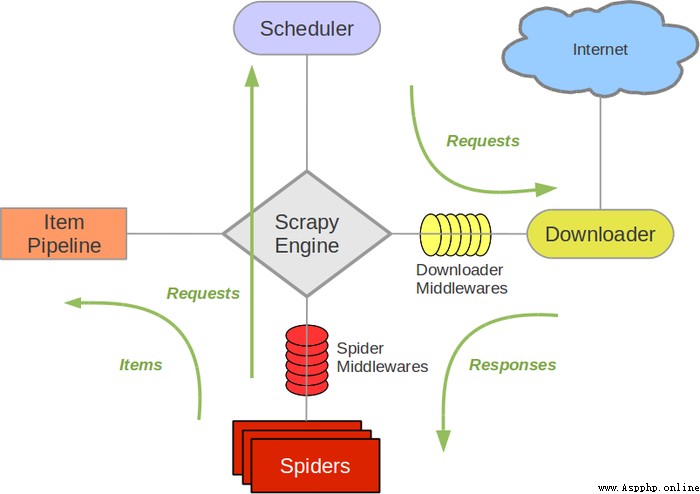
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。
Scheduler(調度器): 它負責接受引擎發送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item字段需要的數據,並將需要跟進的URL提交給引擎,再次進入Scheduler(調度器).
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、存儲等)的地方。
Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件。
Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
制作 Scrapy 爬蟲 一共需要4步:
1、新建項目 (scrapy startproject xxx):新建一個新的爬蟲項目
2、明確目標 (編寫items.py):明確你想要抓取的目標
3、制作爬蟲 (spiders/xxspider.py):制作爬蟲開始爬取網頁
4、存儲內容 (pipelines.py):設計管道存儲爬取內容
在開始爬取之前,必須創建一個新的Scrapy項目。進入自定義的項目目錄中,運行下列命令:
scrapy startproject mySpider
其中, mySpider 為項目名稱,可以看到將會創建一個 mySpider 文件夾,目錄結構大致如下:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
下面來簡單介紹一下各個主要文件的作用:
scrapy.cfg: 項目的配置文件。
mySpider/: 項目的Python模塊,將會從這裡引用代碼。
mySpider/items.py: 項目的目標文件。
mySpider/pipelines.py: 項目的管道文件。
mySpider/settings.py: 項目的設置文件。
mySpider/spiders/: 存儲爬蟲代碼目錄。
我們打算抓取 http://www.itcast.cn/channel/teacher.shtml 網站裡的所有講師的姓名、職稱和個人信息。
打開 mySpider 目錄下的 items.py。
Item 定義結構化數據字段,用來保存爬取到的數據,有點像 Python 中的 dict,但是提供了一些額外的保護減少錯誤。
可以通過創建一個 scrapy.Item 類, 並且定義類型為 scrapy.Field 的類屬性來定義一個 Item(可以理解成類似於 ORM 的映射關系)。
接下來,創建一個 ItcastItem 類,和構建 item 模型(model)。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
爬蟲功能要分兩步:
在當前目錄下輸入命令,將在mySpider/spider目錄下創建一個名為itcast的爬蟲,並指定爬取域的范圍:
scrapy genspider itcast "itcast.cn"
打開 mySpider/spider目錄裡的 itcast.py,默認增加了下列代碼:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其實也可以由我們自行創建itcast.py並編寫上面的代碼,只不過使用命令可以免去編寫固定代碼的麻煩
要建立一個Spider, 你必須用scrapy.Spider類創建一個子類,並確定了三個強制的屬性 和 一個方法。
name = “” :這個爬蟲的識別名稱,必須是唯一的,在不同的爬蟲必須定義不同的名字。
allow_domains = [] 是搜索的域名范圍,也就是爬蟲的約束區域,規定爬蟲只爬取這個域名下的網頁,不存在的URL會被忽略。
start_urls = () :爬取的URL元祖/列表。爬蟲從這裡開始抓取數據,所以,第一次下載的數據將會從這些urls開始。其他子URL將會從這些起始URL中繼承性生成。
parse(self, response) :解析的方法,每個初始URL完成下載後將被調用,調用的時候傳入從每一個URL傳回的Response對象來作為唯一參數,主要作用如下:
負責解析返回的網頁數據(response.body),提取結構化數據(生成item)
生成需要下一頁的URL請求。
將start_urls的值修改為需要爬取的第一個url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改parse()方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
然後運行一下看看,在mySpider目錄下執行:
scrapy crawl itcast
是的,就是 itcast,看上面代碼,它是 ItcastSpider 類的 name 屬性,也就是使用 scrapy genspider命令的唯一爬蟲名。
運行之後,如果打印的日志出現 [scrapy] INFO: Spider closed (finished),代表執行完成。 之後當前文件夾中就出現了一個 teacher.html 文件,裡面就是我們剛剛要爬取的網頁的全部源代碼信息。
scrapy保存信息的最簡單的方法主要有四種,-o 輸出指定格式的文件,命令如下:
scrapy crawl itcast -o teachers.json
json lines格式,默認為Unicode編碼
scrapy crawl itcast -o teachers.jsonl
csv 逗號表達式,可用Excel打開
scrapy crawl itcast -o teachers.csv
xml格式
scrapy crawl itcast -o teachers.xml