import os
import pandas as pd
def writefilename2excel(folder_path, excel1_path, txt_path):
# Load folder
folder = os.listdir(folder_path)
satellite_list = [] # satellite
image_list = [] # Imaging mode
product_list = [] # Product category
time_list = [] # Imaging date
moment1_list = [] # Imaging time 1
moment2_list = [] # Imaging time 2
orbit_list = [] # Absolute orbital number
task_list = [] # Task data utilizes identifiers
code_list = [] # Unique product identification code
for file in folder:
# file_list.append(file)
satellite = file.split('_')[0] # Get satellite identification
# print(satellite)
satellite_list.append(satellite)
# print(satellite)
image = file.split('_')[1] # Obtain imaging mode
# print(image)
image_list.append(image)
product = file.split('_')[2] # Get product categories
# print(product)
product_list.append(product)
time = file.split('_')[5] # Get the imaging date
time = time.split('T')[0] # Get the imaging date
time_list.append(time)
# print(time)
moment1 = file.split('_')[5].split('T')[1] # Obtain the imaging start time
moment1_list.append(moment1)
moment2 = file.split('_')[6].split('T')[1] # Obtain the imaging end time
moment2_list.append(moment2)
orbit = file.split('_')[7] # Get the absolute track number
orbit_list.append(orbit)
task = file.split('_')[8] # Get task data using identifiers
task_list.append(task)
code = file.split('_')[9] # Get task data using identifiers
code_list.append(code)
all_list = {
'satellite_list': satellite_list,
'image_list': image_list,
'product_list': product_list,
'time_list': time_list,
'moment1_list': moment1_list,
'moment2_list': moment2_list,
'orbit_list': orbit_list,
'task_list': task_list,
'code_list': code_list,
}
df = pd.DataFrame(all_list)
# columns = ['file_name', 'sensor', 'longitude', 'latitude','time', 'product_ID']
pd.DataFrame(df).to_excel(excel1_path, index=False)
# for i in range(len(product_ID_list)):
# product_ID_list[i].replace("'", "")
# print(product_ID_list)
str = '\n'
f = open(txt_path, "w")
f.write(str.join(time_list))
f.close()
if __name__ == '__main__':
folder = r''
excel = r''
txt = r''
writefilename2excel(folder, excel, txt)
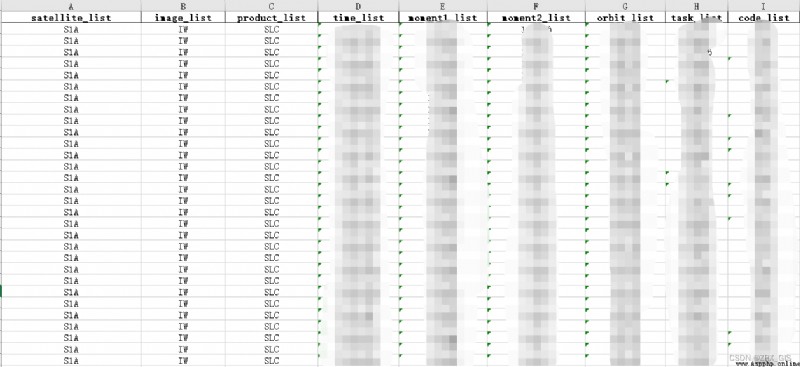

use excel Generate a date .csv, Don't title, Save as CSV UTF-8 file type 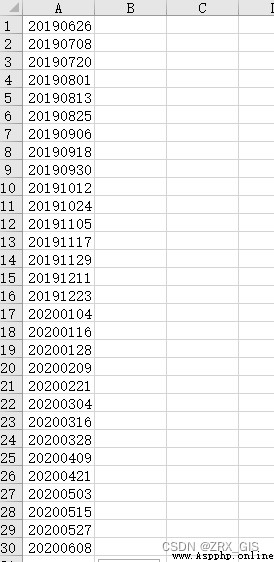
Open the source page , obtain cookie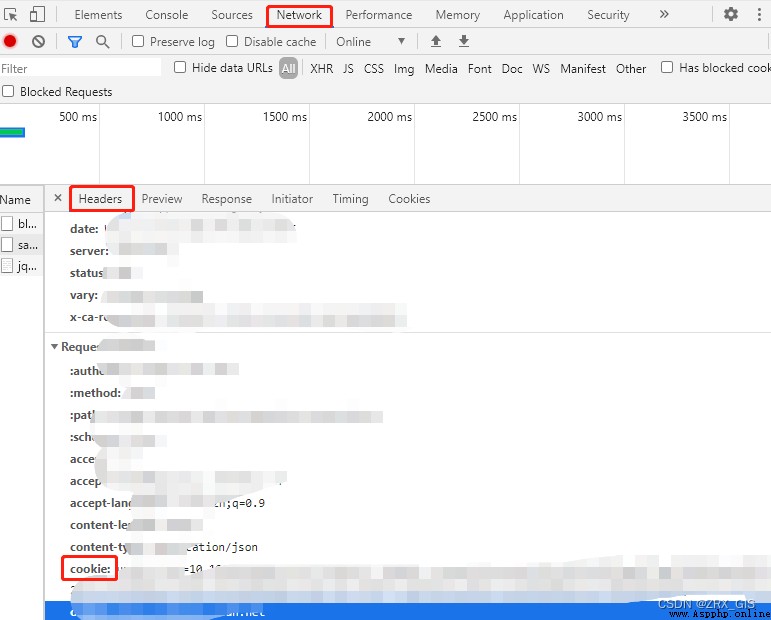
from urllib.request import Request, build_opener
from urllib.error import URLError
from my_fake_useragent import UserAgent
from time import sleep
import re
import datetime
import pandas
import os
from dateutil.parser import parse
''' 1、 The program gets 'https://s1qc.asf.alaska.edu/aux_poeorb/' The data on this website 2、 Need to write a csv file , stay csv The first column of the file starts to write the download time of the image 3、 The first place this program needs to be changed is 'get_info_href()' and 'DownLoad_POD()' In these two functions cookie attribute 4、 The second place the program needs to change is 'get_data_time()' Function csv Path to file , for example :'D:\python\datatime.csv' 5、 The path for the program to download the precision orbit data is the following... For the program to run POD Folder , The program will create itself , The path will also appear in the output window '''
def get_info_href(): # Use regular expressions to get the web address of each specific precise orbit data
try:
ua = UserAgent(family='chrome')
UA = ua.random() # Set up virtual proxy
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.41'
headers = {
'User-Agent': UA,
'Cookie': ''}
url = 'https://s1qc.asf.alaska.edu/aux_poeorb/' # Request URL
time = get_datetime() # function get_datatime() function , Return time
day = datetime.timedelta(days=1) # determine day Parameters , Give Way day=1
href = [] # Set empty list , Used to store the fine rail web address
for i in time: # Traverse the return time
# str For regular expressions , Used to identify data , Remember to change S1A\S1B,int((i-day).strftime("%Y%m%d")) and int((i+day).strftime("%Y%m%d")) Calculate the date of the previous day and the next day according to the fine track naming rules
str = f'S1A_OPER_AUX_POEORB_OPOD_\d+\w\d+_\w{
int((i - day).strftime("%Y%m%d"))}\w\d+_{
int((i + day).strftime("%Y%m%d"))}\w\d+.EOF'
req = Request(url, headers=headers) # Send request header
sleep(2) # Sleep for two seconds , Prevent website identification
opener = build_opener()
result = opener.open(req)
a = result.read().decode() # Get all the fine rail websites , With str Type to save
result1 = re.search(str, a) # Matching using regular expressions
href.append(result1.group()) # Store the matched data in the trace href In the list
return href # return href list
except URLError as e:
print(print(' Network error is :' + '{0}'.format(e)))
def DownLoad_POD(): # Start the download POD Data files
ua = UserAgent(family='chrome')
UA = ua.random() # Set up virtual proxy
headers = {
'User-Agent': UA,
'Cookie': ''}
hrefs = get_info_href()
path() # Return to the POD route
num = 0
for href in hrefs: # Traverse each returned POD website
try:
url = f'https://s1qc.asf.alaska.edu/aux_poeorb/{
href}'
req = Request(url, headers=headers)
sleep(2)
opener = build_opener()
result = opener.open(req)
try:
''' Start downloading data '''
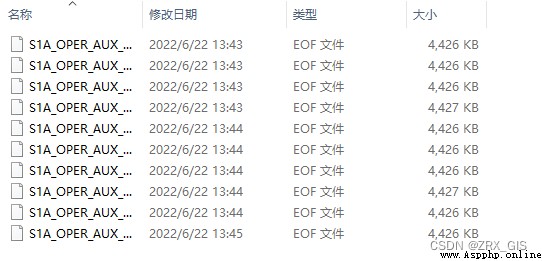
print(' Data download ')
f = open(f'{
href}', 'w', encoding='utf-8')
f.write(result.read().decode())
f.close()
print(f'{
href} Download complete ')
num = num + 1
except BaseException as f:
print(' The file download error is :', f)
except URLError as e:
print(' Network error is :', e)
print(' download POD data ', str(num), ' individual ', f' The download folder path is {
os.getcwd()}')
def path(): # alternate path , establish POD Folder
path = os.getcwd()
isexist = os.path.exists('POD')
if not isexist: # Judge whether there is... In this path POD file
os.mkdir('POD')
os.chdir(f'{
path}\POD')
print(f' In the {
path} Created under POD Folder , The current directory has been set to {
os.getcwd()}')
else:
os.chdir(f'{
path}\POD')
os.chdir(f'{
path}\POD')
print(f' The {
path} It already exists POD Folder , The current directory has been set to {
os.getcwd()}')
def get_datetime(): # Yes csv The time in the file is converted
with open(r'C:\Users\123\Desktop\datatime.csv', encoding='utf-8') as a:
a_scv = pandas.read_csv(a, header=None)
nrows = a_scv.shape[0]
ncols = a_scv.columns.size
list = []
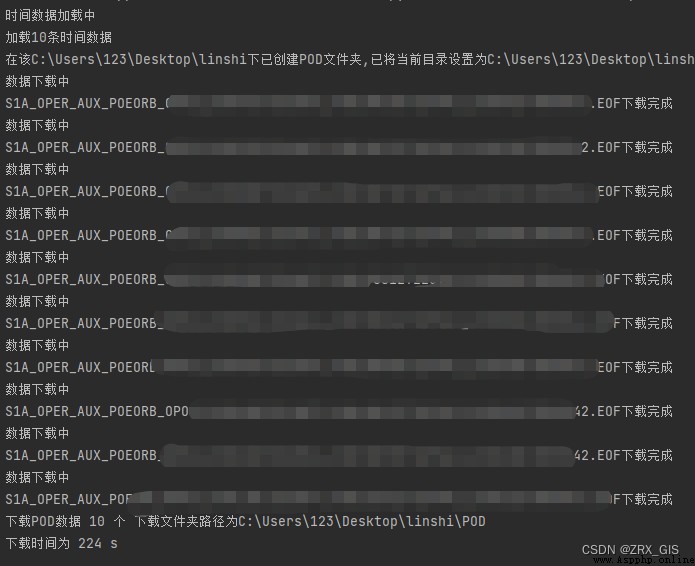
print(' Time data loading ')
for irow in range(nrows):
for icol in range(ncols):
# print(a_scv.iloc[irow, icol])
list.append(a_scv.iloc[irow, icol])
print(f' load {
nrows} Time data ')
time = []
for t in list:
time.append(parse(str(t)).date())
return time
if __name__ == '__main__':
import http.client
http.client.HTTPConnection._http_vsn = 10
http.client.HTTPConnection._http_vsn_str = 'HTTP/1.0'
start_time = datetime.datetime.now()
DownLoad_POD()
end_time = datetime.datetime.now()
spend_time = (end_time - start_time).seconds
print(' Download time is ', spend_time, 's')