Python There is a lot to do in PDF Excellent library of , Let's briefly compare the advantages and disadvantages of each library .
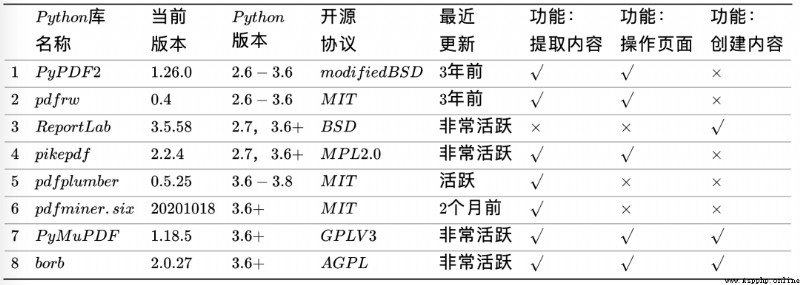
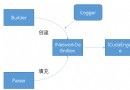
PyPDF2 series 、pdfrw And pikepdf Focus on what already exists PDF The operation of ( Division 、 Merge 、 Spin, etc ), The first two are basically in the stop maintenance state .
pdfplumber And its dependence pdfminer.six focus PDF Content extraction , For example, text ( Location 、 Font and color, etc ) And shape ( rectangular 、 A straight line 、 curve ), The former also has the function of parsing tables .
ReportLab focus PDF The page content ( Text 、 chart 、 Table, etc ) The creation of .
PyMuPDF and borb It also supports reading 、 Write and PDF Page operation , The most comprehensive function . among ,PyMuPDF It is especially famous for its fast speed , and borb It is a newly developed and highly praised library , The potential is endless . however , Both are GPL Family of open source protocols , Not very business friendly .
PyMuPDF brief introduction
Introduce
function
install
About the name `fitz` Explanation
Usage method
1 Import library , View version
2 Open the document
3 Document Methods and properties of
4 Fetch metadata
5 Get the goal outline
6 page (`Page`)
7 PDF operation

PyMuPDF brief introduction
Today is our main character PyMuPDF, One with the most comprehensive functions python Office automation tools !

github Address :pymupdf/PyMuPDF: Python bindings for MuPDF’s rendering library
The official manual :PyMuPDF Documentation — PyMuPDF 1.18.17 documentation
Introducing PyMuPDF Before , Let's first get to know MuPDF, As can be seen from the naming form ,PyMuPDF yes MuPDF Of Python Interface form .
MuPDF It's a lightweight PDF、XPS And e-book viewer .MuPDF By software library 、 Command line tools and viewers of various platforms .
MuPDF The renderer in is tailored for high-quality anti aliasing graphics . The text is rendered in a fraction of its pixel spacing , To obtain the highest fidelity when reproducing the appearance of the printed page on the screen .
This observer is very small , fast , But it's complete . It supports multiple document formats , Such as PDF、XPS、OpenXPS、CBZ、EPUB and FictionBook 2. You can use the mobile viewer to PDF Annotate the document and fill in the form ( This feature will also be applied to desktop viewers soon ).
Command line tools allow you to comment 、 Edit document , And convert the document to other formats , Such as HTML、SVG、PDF and CBZ. You can also use it Javascript Write scripts to manipulate documents .
PyMuPDF( current version 1.18.17) It's supporting MuPDF( current version 1.18.*) Of Python binding .
Use PyMuPDF, You can access the extension “.pdf”、“.xps”、“.oxps”、“.cbz”、“.fb2” or “.epub”. Besides , about 10 A popular image format can also be processed like a document :“.png”,“.jpg”,“.bmp”,“.tiff” etc. .
For all supported document types, you can :
Decrypt files
Access meta information 、 Links and Bookmarks
In grid format (PNG And other formats ) Or vector format SVG Render page
Search text
Extract text and images
Convert to other formats :PDF, (X)HTML, XML, JSON, text
about PDF file , There are a lot of additional functions : They can establish 、 Merge or split . Pages can be used in many ways Insert 、 Delete 、 Rearrange or modify ( Include comments and form fields ).
You can extract or insert images and Fonts
Fully support embedded files
pdf Reformat the file , To support duplex printing , Color separation , Apply logo or watermark
Fully support password protection : Decrypt 、 encryption 、 Encryption method selection 、 Permission levels and users / Owner password settings
Support image 、 Text and drawing PDF Optional content concept
You can access and modify low-level data PDF structure
Command line module "python \-m fitz…" Multifunctional utility with the following features
encryption / Decrypt / Optimize
Create subdocuments
Document connection
Images / Font extraction
Fully support embedded files
Save the text extraction of the layout ( All documents )
PyMuPDF You can install... From the source code , You can also get it from wheels install .
about Windows, Linux and Mac OSX platform , stay PyPI The download section of is wheels. This includes Python 64 Bit version 3.6 To 3.9.Windows The version also has 32 Bit version . Starting recently ,Linux ARM There are also some problems with the architecture —— Find platform label manylinux2014_aarch64.
In addition to the standard library , It has no mandatory external dependencies . Only when some packages are installed , There will be some good methods :
Pillow: When using Pixmap.pil_save() and Pixmap.pil_tobytes() The need when
fontTools: When using Document.subset_fonts() The need when
pymupdf-fonts Is a good font choice , Can be used for text output methods
Use pip Installation command :
pip install PyMuPDFImport library :
import fitzfitz Explanation The standard of this library Python The import statement is import fitz. There are historical reasons for that :MuPDF The original rendering library is called Libart.
stay Artifex Software acquisition MuPDF After the project , The focus of development has shifted to the preparation of a new modern graphics library called “Fitz”.Fitz Originally as a research and development project , To replace aging Ghostscript Graphics library , But it became MuPDF The rendering engine ( Quoted from Wikipedia ).
Usage method
import fitz
print(fitz.__doc__)
PyMuPDF 1.18.16: Python bindings for the MuPDF 1.18.0 library.
Version date: 2021-08-05 00:00:01.
Built for Python 3.8 on linux (64-bit).doc = fitz.open(filename) This will create Document object doc. The file name must be the name of an existing file python character string .
You can also get it from Memory data Open the document , Or create a new empty PDF. You can also use documents as context managers .
Document.page_count the number of pages (int)Document.metadata Metadata (dict)Document.get_toc() Get directory (list)Document.load_page() Read page Example :
>>> doc.count_page
1
>>> doc.metadata
{'format': 'PDF 1.7',
'title': '',
'author': '',
'subject': '',
'keywords': '',
'creator': '',
'producer': ' Foxin reader PDF The printer edition 10.0.130.3456',
'creationDate': "D:20210810173328+08'00'",
'modDate': "D:20210810173328+08'00'",
'trapped': '',
'encryption': None}PyMuPDF Fully support standard metadata .Document.metadata Is a with the following keys Python Dictionaries .
It applies to all document types , But not all entries always contain data . The metadata field is a string , If not otherwise instructed , It is nothing . Also note that , Not all data always contains meaningful data —— Even if they don't have none .
toc = doc.get_toc()Page) Page processing is MuPDF The core of function .
• You can render the page as a raster or vector (SVG) Images , You can choose to zoom 、 rotate 、 Move or cut pages .
• You can extract Multiple formats Page text and image , And search the text string .
• about PDF file , There are more ways to add text or images to a page .
First , You must create a page Page. This is a Document One way :
page = doc.load_page(pno) # loads page number 'pno' of the document (0-based)
page = doc[pno] # the short form Any integer can be used here -inf<pno<page_count. Negative numbers count down from the end , therefore doc[-1] It's the last page , It's like Python The sequence is the same .
A more advanced approach is to use the document as an iterator for the page :
for page in doc:
# do something with 'page'
# ... or read backwards
for page in reversed(doc):
# do something with 'page'
# ... or even use 'slicing'
for page in doc.pages(start, stop, step):
# do something with 'page'Next , This paper mainly introduces
PageCommon operations of !
When using some viewer software to display documents , The link appears as ==“ Hot spots ”==. If you are in the cursor display Hand symbol Click when , You will usually be taken to the coded mark in the hot area . Here's how to get all the links :
# get all links on a page
links = page.get_links()links It's a Python Dictionaries list .
It can also be used as an iterator :
for link in page.links():
# do something with 'link' If processing PDF Document page , There may also be comments (Annot) Or form fields (Widget), Each field has its own iterator :
for annot in page.annots():
# do something with 'annot'
for field in page.widgets():
# do something with 'field'This example creates a raster image of the contents of a page :
pix = page.get_pixmap()pix It's a Pixmap object , it ( In this case ) That contains the page RGB Images , It can be used for many purposes .
Method Page.get_pixmap() Many variants for controlling images are provided : The resolution of the 、 Color space ( for example , Generate a grayscale image or an image with a subtraction scheme )、 transparency 、 rotate 、 Mirror image 、 displacement 、 Shear, etc .
for example : establish RGBA Images ( namely , contain alpha passageway ), Appoint pix=page.get_pixmap(alpha=True).\
Pixmap Contains many methods and properties referenced below . It includes integers Width 、 Height ( Every pixel ) and Span ( The number of bytes in a horizontal image line ). The attribute example represents a property that represents image data Rectangular byte area (Python Byte object ).
You can also use page.get_svg_image() Create a vector image of the page .
We can simply store images in PNG In file :
pix.save("page-%i.png" % page.number)We can also extract all the text of the page in many different forms and levels of detail 、 Images and other information :
text = page.get_text(opt) Yes opt Use one of the following strings to get a different format :
"text":( Default ) Plain text with line breaks . Unformatted 、 No text location details 、 No image
"blocks": Generate text blocks ( The paragraph ) A list of
"words": Generate word list ( Strings without spaces )
"html": Create a full visual version of the page , Include any images . This can be done by internet Browser display
"dict"/"json": And HTML Same level of information , But as a Python Dictionary or resp.JSON character string .
"rawdict"/"rawjson":"dict"/"json" Super Collection of . It also provides services such as XML Character details like .
"xhtml": The text information level is the same as the text version , But it contains images .
"xml": Does not contain images , But with each text character Complete location and font information . Use XML Module to explain .
You can find the exact location of a text string on the page :
areas = page.search_for("mupdf") This will provide a Rectangular list , Each rectangle contains a string “mupdf”( Case insensitive ). You can use this information to highlight these areas ( Limited to PDF) Or create cross references to documents .
PDF Is the only one that can use PyMuPDF modify The document type of . Other file types are read-only .
however , You can send any document ( Include images ) Convert to PDF, And then all of the PyMuPDF The function is applied to the conversion result ,Document.convert_to_pdf().
Document.save() Always PDF With its current ( May have been modified ) The status is stored on disk .
Usually , You can choose to save to a new file , Or just append the changes to the existing file (“ Incremental save ”), This is usually much faster .
Here's how to operate PDF file .
There are several ways to manipulate the so-called page tree ( Describe the structure of all pages ):
PDF:Document.delete_page() and Document.delete_pages() Delete page
Document.copy_page()、Document.fullcopy_page() and Document.move_page() Page Copy or move To another location in the same document .
Document.select() take PDF Compress to selected page , The parameter is the page number sequence to keep . These integers must be in 0<=i<page_ count Within the scope of . Execution time , All pages missing from this list will be deleted . The remaining pages will appear in order , Same number of times (!) As you specified .
therefore , You can easily use to create new PDF:
First or last 10 page
Only odd or even pages ( For duplex printing )
A page with or without the given text
Reverse page order
The saved new document will contain links that are still valid 、 Comments and Bookmarks (i.a.w. Point to the selected page or some external resources ).
Document.insert_page() and Document.new_page() Insert new page .
Besides , The page itself can be modified in a series of ways ( For example, page rotation 、 Notes and link maintenance 、 Text and image insertion ).
Method Document.insert_pdf() In different pdf Copy pages between documents . Here's a simple one joiner Example (doc1 and doc2 stay PDF Open in ):
# append complete doc2 to the end of doc1
doc1.insert_pdf(doc2)Here's a Split doc1 Fragments of . It will create the first page and the last 10 New document for page :
doc2 = fitz.open() # new empty PDF
doc2.insert_pdf(doc1, to_page = 9) # first 10 pages
doc2.insert_pdf(doc1, from_page = len(doc1) - 10) # last 10 pages
doc2.save("first-and-last-10.pdf")Document.save() The document will always be saved in its current state .
You can specify options by incremental=True Write changes back to the original PDF. This process ( Usually ) Very fast , Because the change will additional To the original file , Without completely rewriting it .
While the program continues to run , Usually “ close ” Document to give control of the underlying file to the operating system .
This can be done by Document.close() Method realization . In addition to closing the basic file , The buffer associated with the document will also be freed
source :https://blog.csdn.net/ling620/article/details/120035699
author : ice __ blue
Recommended reading
50 That's ok Python Code crawl black silk Meimei high definition picture
Ten minutes to complete python exception handling
5 Life saving python Tips