什麼是內存管理機制
一、引用計數機制
二、數據池和緩存
什麼是內存管理機制python中創建的對象的時候,首先會去申請內存地址,然後對對象進行初始化,所有對象都會維護在一
個叫做refchain的雙向循環鏈表中,每個數據都保存如下信息:
一、引用計數機制1. 鏈表中數據前後數據的指針
2. 數據的類型
3. 數據值
4. 數據的引用計數
5. 數據的長度(list,dict..)
引用計數增加:
1.1 對象被創建
1.2 對象被別的變量引用(另外起了個名字)
1.3 對象被作為元素,放在容器中(比如被當作元素放在列表中)
1.4 對象被當成參數傳遞到函數中
import sysa = [11,22] # 對象被創建b = a # 對象被別的變量引用c = [111,222,333,a] # 對象被作為元素,放在容器中# 獲取對象的引用計數print(sys.getrefcount(a)) # 對象被當成參數傳遞到函數中最後的執行結果是,a 這個變量被引用了4次

引用計數減少:
對象的別名被顯式的銷毀
對象的一個別名被賦值給其他對象 (例:比如原來的a=10,被改成a=100,此時10的引用計數就減少了)
對象從容器中被移除,或者容器被銷毀(例:對象從列表中被移除,或者列表被銷毀)
一個引用離開了它的作用域(調用函數的時候傳進去的參數,在函數運行結束後,該參數的引用即被銷毀)
import sysdel b # 對象的別名被顯式的銷毀b = 999 # 對象的一個別名被賦值給其他對象del c # 列表被銷毀(容器被銷毀)c.pop() # 把列表數據最後一個刪除掉(對象從容器中被移除)二、數據池和緩存數據池分為兩種:小整數池 和 大整數池
小整數池(-5到256之間的數據)
運行機制:Python自動將 -5~256 的整數進行了緩存到一個小整數池中,當你將這些整數賦值給變量時,並不會重新
創建對象,而是使用已經創建好的緩存對象,當刪除這些數據的引用時,也不會進行回收
超出-5到256的整數將不會在在緩存,會重新創建對象
例如:
對於超出-5到256的整數將不會在在緩存,Python會重新創建對象,返回id
# 場景1:數據為列表,不在-5~256 的范圍>>> a = [11]>>> b = [11]>>> id(a),id(b)(1693226918600, 1693231858248) ========》 id 不一樣# 場景二: 數據為整數,在-5~256 的范圍>>> aa = 11>>> bb = 11>>> id(aa),id(bb)(140720470385616, 140720470385616) id 一樣# 場景三: 數據不在-5~256的范圍>>> bb = -7>>> aa = -7>>> id(aa),id(bb)(1843518717904, 1843518717776) id 不一樣# 場景四: 數據不在-5~256的范圍>>> a = 257>>> b = 257>>> id(a),id(b)(2092420910928, 2092420911056) id 不一樣大整數池(字符串駐留池 / intern機制)
優點:在創建新的字符串對象時,會先在緩存池裡面找是否有已經存在的值相同的對象(標識符,即只包含數字、字母、下劃線的字符串),如果有,則直接拿過來用(引用),避免頻繁的創建和銷毀內存,提升效率
例如:
對於不在標識符內的數據將不會在在緩存,Python會重新創建對象,返回id
# 場景1:>>> a = '123adsf_'>>> b = '123adsf_'>>> id(a),id(b)(61173296, 61173296) ========》 id 一樣# 場景二: >>> b1 = '123adsf_?'>>> b2 = '123adsf_?'>>> id(b1),id(b2)(61173376, 61173416) id 不一樣緩存機制
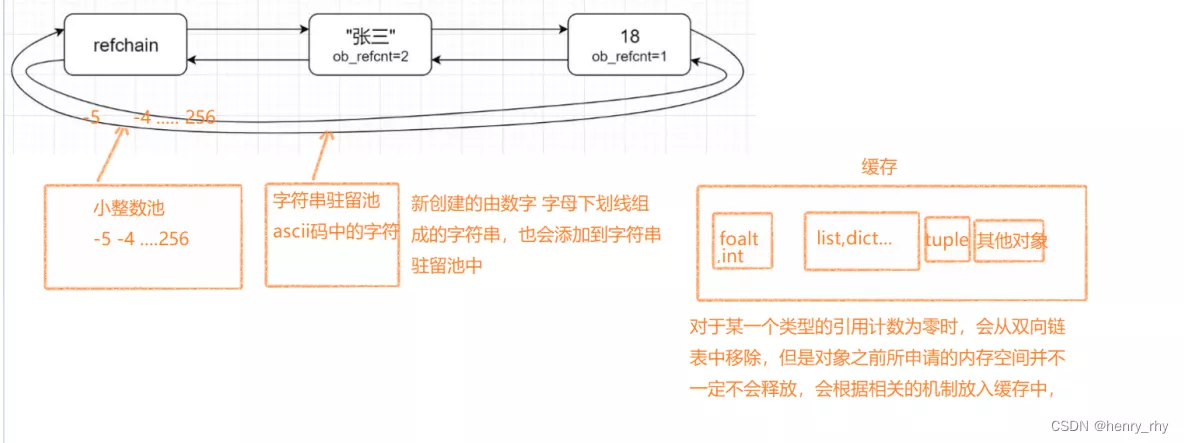
對於python中常用內置數據類型的緩存:
float:緩存100個對象
list: 80個對象
dict: 80個對象
set: 80個對象
元組:會根據元組數據的長度,分別緩存元組長度為0-20的對象
到此這篇關於Python超詳細講解內存管理機制的文章就介紹到這了,更多相關Python內存管理內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!