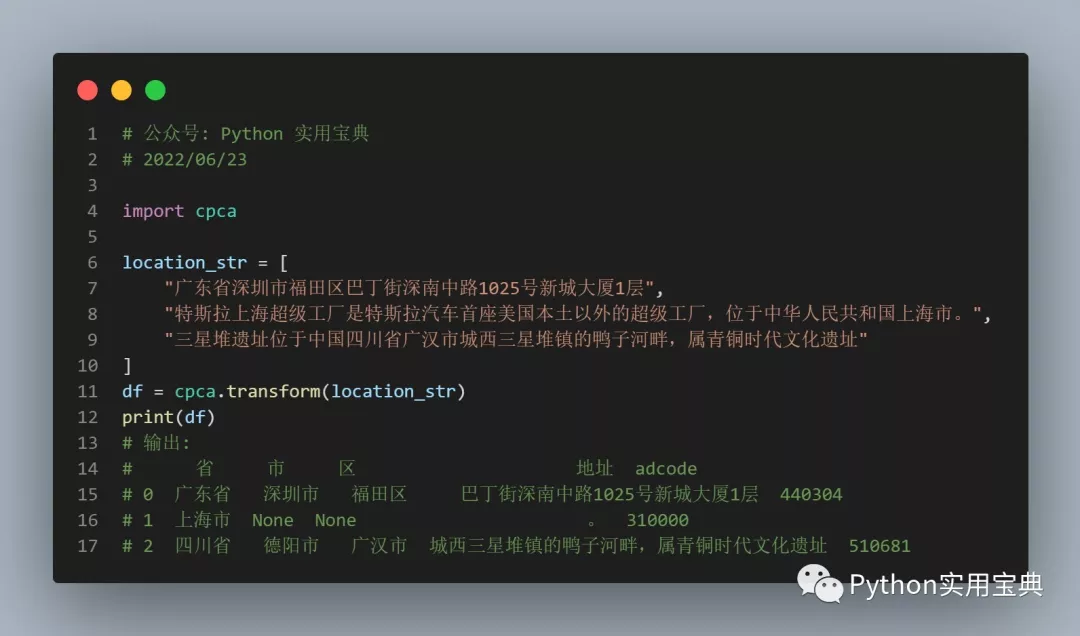
首先,主要討論和演示機器學習中使用的基本數據模型及其演示,其次開始的深度學習討論,然後,探討 ANN 和 CNN 如何預測結果,例如,當呈現未知圖像時,CNN 將嘗試將其識別為屬於它已被訓練識別的類別之一。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn import decomposition
from sklearn.preprocessing import scale
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
df = pd.read_csv('iris.csv', header=None, sep=',')
df.columns=['sepal_length', 'sepal_width', 'petal_length',
'petal_width', 'class']
df.dropna(how="all", inplace=True) # Drops empty line at EOF
# Show the first 5 records
print(df.head())
f, ax = plt.subplots(1, 4, figsize=(10,5))
vis1 = sns.distplot(df['sepal_length'],bins=10, ax= ax[0])
vis2 = sns.distplot(df['sepal_width'],bins=10, ax=ax[1])
vis3 = sns.distplot(df['petal_length'],bins=10, ax= ax[2])
vis4 = sns.distplot(df['petal_width'],bins=10, ax=ax[3])
plt.show()
# split data table into data X and class labels y
X = df.ix[:,0:4].values
y = df.ix[:,4].values
# Standardize the data
X_std = StandardScaler().fit_transform(X)
# Compute the covariance matrix
mean_vec = np.mean(X_std, axis=0)
cov_mat = (X_std -mean_vec).T.dot(X_std - mean_vec) /
(X_std.shape[0] - 1)
print('Covariance matrix \n%s' %cov_mat)
# Compute the Eigenvectors and Eigenvalues
cov_mat = np.cov(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors \n%s' %eig_vecs)
print('Eigenvalues \n%s' %eig_vals)
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in
range(len(eig_vals))]
eig_pairs.sort()
eig_pairs.reverse()
print('Eigenvalues in descending order:')
for i in eig_pairs:
print(i[0])
# Compute the Eigenvalue ratios
tot = sum(eig_vals)
var_exp = [(i / tot)*100 for i in sorted(eig_vals,
reverse=True)]
cum_var_exp = np.cumsum(var_exp)
print('Eigenvalue ratios:%s' %cum_var_exp)
#Create the W matrix
matrix_w = np.hstack((eig_pairs[0][1].reshape(4,1),
eig_pairs[1][1].reshape(4,1)))
print('Matrix W:\n', matrix_w)
# Transform the X_std dataset to the sub-space Y
Y = X_std.dot(matrix_w)
features = ['sepal_length', 'sepal_width', 'petal_length',
'petal_width']
# Create a scatter plot for PC1 vs PC2
x = df.loc[:,features].values
x = StandardScaler().fit_transform(x)
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data=principalComponents,
columns=['principal component 1','principal component 2'])
finalDf = pd.concat([principalDf, df[['class']]], axis=1)
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize=15)
ax.set_ylabel('Principal Component 2', fontsize=15)
ax.set_title('2 Component PCA', fontsize=20)
targets = ['setosa', 'versicolor', 'virginica']
colors = ['r', 'g', 'b']
for target, color in zip(targets, colors):
indicesToKeep = finalDf['class'] == target
ax.scatter(finalDf.loc[indicesToKeep, 'principal component
1'], finalDf.loc[indicesToKeep, 'principal component 2'],
c=color, s=50)
ax.legend(targets)
ax.grid
plt.show()