The gods were silent - personal CSDN Blog Directory
This article will introduce jieba、HanLP、LAC、THULAC、NLPIR、spacy And other common Python Simple usage of Chinese word segmentation tool .
official GitHub project :fxsjy/jieba: Stuttering Chinese word segmentation
Installation mode :pip install jieba
Accurate model :jieba.cut(text) Returns an iterator , Each element is a word .(lcut() Go straight back to list)
import jieba
print(' '.join(jieba.cut(' Action is the fruit , Words are but branches and leaves .')))
Output :
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.455 seconds.
Prefix dict has been built successfully.
action only yes Fruit , Words however yes Branches and leaves .
cut() The parameters of the function :
HMM: New word discovery function , Automatically calculated word frequency ( The custom dictionary section below ) May not be valid .use_paddle:paddle Pattern : The dictionary cannot be customized after use , According to my guess, it should be with LAC The bag is the same , So it's better to use LAC package . Use jieba.enable_parallel() The parallel word segmentation mode can be enabled ( Separate text by line ), I won't support it Windows. The input parameter is the number of parallel processes , If no parameter is entered, it is assumed that CPU Number .jieba.disable_parallel() Turn off parallel word segmentation mode
① Add a custom dictionary :jieba.load_userdict(file_name) file_name Path for file class object or custom dictionary .
Dictionary format and https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt equally , One word for one line ; Each line is divided into three parts : words 、 Word frequency ( Omission )、 The part of speech ( Omission ), Space off , Order cannot be reversed .file_name If a file is opened in path or binary mode , The document must be UTF-8 code .
When the word frequency is omitted, the word frequency calculated automatically can ensure that the word can be distinguished .
② Adjust dictionary :add_word(word, freq=None, tag=None) and del_word(word) The dictionary can be dynamically modified in the program .
Use suggest_freq(segment, tune=True) The frequency of a single word can be adjusted , Make it possible to ( Or not ) Be divided .
Examples of using custom dictionaries :https://github.com/fxsjy/jieba/blob/master/test/test_userdict.py
Use jieba.posseg Replace jieba, It can also return part of speech tagging .
Use jieba.tokenize() It can also return the starting and ending positions of words in the original text , Input only accepts Unicode.
If you only have the permission of the user folder, but do not /tmp Authority , A warning message will be sent , You can change the word breaker ( The default is jieb.dt) Of tmp_dir and cache_file Property to solve this problem .
official GitHub project :hankcs/HanLP: Chinese word segmentation Part of speech tagging Named entity recognition dependency parsing Component parsing Semantic dependency analysis Semantic Role Labeling Anaphora digestion Style change semantic similarity The discovery of new words Keyword phrase extraction Automatic summarization Text classification and clustering Phonetic conversion natural language processing
Official website :HanLP The online demo Multilingual natural language processing
You need to apply for a key , So I haven't used it yet , await a vacancy or job opening .
official GitHub project :baidu/lac: Baidu NLP: participle , Part of speech tagging , Named entity recognition , Word importance
The paper quotes :
@article{jiao2018LAC,
title={Chinese Lexical Analysis with Deep Bi-GRU-CRF Network},
author={Jiao, Zhenyu and Sun, Shuqi and Sun, Ke},
journal={arXiv preprint arXiv:1807.01882},
year={2018},
url={https://arxiv.org/abs/1807.01882}
}
Installation mode :pip install lac or pip install lac -i https://mirror.baidu.com/pypi/simple
extracted_sentences=" As the business continues to generate sales of goods , Its data is important to its own marketing planning 、 Market analysis 、 Logistics planning is of great significance . However, there are many factors influencing the sales forecast , The traditional measurement model based on statistics , For example, time series models have too many assumptions about reality , Resulting in poor prediction results . Therefore, we need better intelligence AI Algorithm , To improve the accuracy of the prediction , So as to help enterprises reduce inventory costs 、 Shorten lead time 、 Improve the anti risk ability of enterprises ."
from LAC import LAC
lac=LAC(mode='seg') # The default value is mode='lac' Part of speech tagging function will be attached , See the following text for the corresponding label
seg_result=lac.run(extracted_sentences) # With Unicode String is an input parameter
print(seg_result)
seg_result=lac.run(extracted_sentences.split(',')) # Take string list as input parameter , The average speed will be faster
print(seg_result)
Output :
W0625 20:03:29.850801 32781 init.cc:157] AVX is available, Please re-compile on local machine
W0625 20:03:29.868482 32781 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:03:29.868522 32781 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
[' With ', ' Enterprises ', ' continued ', ' produce ', ' Of ', ' goods ', ' sales ', ',', ' Its ', ' data ', ' about ', ' Oneself ', ' marketing ', ' planning ', '、', ' Market analysis ', '、', ' logistics ', ' planning ', ' all ', ' Yes ', ' important ', ' significance ', '.', ' however ', ' sales ', ' forecast ', ' Of ', ' influence ', ' factors ', ' various ', ',', ' Tradition ', ' Of ', ' be based on ', ' Statistics ', ' Of ', ' metering ', ' Model ', ',', ' such as ', ' Time ', ' Sequence ', ' Model ', ' etc. ', ' because ', ' Yes ', ' reality ', ' Of ', ' hypothesis ', ' situation ', ' Too much ', ',', ' Lead to ', ' forecast ', ' result ', ' Poor ', '.', ' therefore ', ' need ', ' more ', ' good ', ' Of ', ' intelligence ', 'AI', ' Algorithm ', ',', ' With ', ' Improve ', ' forecast ', ' Of ', ' accuracy ', ',', ' thus ', ' help ', ' Enterprises ', ' Reduce ', ' stock ', ' cost ', '、', ' To shorten the ', ' delivery ', ' cycle ', '、', ' Improve ', ' Enterprises ', ' resist ', ' risk ', ' Ability ', '.']
[[' With ', ' Enterprises ', ' continued ', ' produce ', ' Of ', ' goods ', ' sales '], [' Its ', ' data ', ' about ', ' Oneself ', ' marketing ', ' planning ', '、', ' Market analysis ', '、', ' logistics ', ' planning ', ' all ', ' Yes ', ' important ', ' significance ', '.', ' however ', ' sales ', ' forecast ', ' Of ', ' influence ', ' factors ', ' various '], [' Tradition ', ' Of ', ' be based on ', ' Statistics ', ' Of ', ' metering ', ' Model '], [' such as ', ' Time ', ' Sequence ', ' Model ', ' etc. ', ' because ', ' Yes ', ' reality ', ' Of ', ' hypothesis ', ' situation ', ' Too much '], [' Lead to ', ' forecast ', ' result ', ' Poor ', '.', ' therefore ', ' need ', ' more ', ' good ', ' Of ', ' intelligence ', 'AI', ' Algorithm '], [' With ', ' Improve ', ' forecast ', ' Of ', ' accuracy '], [' thus ', ' help ', ' Enterprises ', ' Reduce ', ' stock ', ' cost ', '、', ' To shorten the ', ' delivery ', ' cycle ', '、', ' Improve ', ' Enterprises ', ' resist ', ' risk ', ' Ability ', '.']]
Part of speech tagging function tag :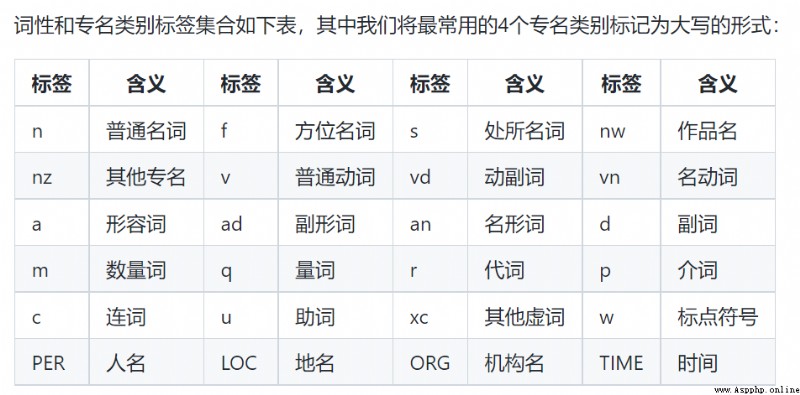
Use a custom dictionary :item Will not be divided .
Each line of the dictionary file represents a customized item, Consisting of one word or more consecutive words , Use... After each word ’/‘ It means label , without ’/' The label will use the default label of the model . Every item More words , The more precise the intervention will be .
Example dictionary file :
spring /SEASON
flowers /n open /v
Autumn wind
fall Yang
stay run() Use the code before :
# Load intervention Dictionary , sep Parameter indicates the separator used by the dictionary file , by None The default is to use spaces or tabs '\t'
lac.load_customization('custom.txt', sep=None)
Official website :THULAC: An efficient Chinese lexical analysis toolkit
Online demo site :THULAC: An efficient Chinese lexical analysis toolkit
I saw that the model download needs to apply , So it hasn't been used yet , await a vacancy or job opening .
official GitHub project :NLPIR-team/NLPIR
Official website :NLPIR Natural language processing and information retrieval sharing platform – NLPIR Natural Language Processing & Information Retrieval Sharing Platform natural language processing 、 Big data Lab 、 Intelligent semantic platform Chinese word segmentation 、 Chinese semantic analysis 、 Chinese information processing 、 Semantic analysis system 、 Chinese knowledge map 、 Big data analysis tools
NLPIR The official website of Chinese word segmentation system :NLPIR-ICTCLAS Chinese word segmentation system - home page
After reading this, I still need to download the software , It feels inconvenient to use , If you really need it in the future .
spacy Model official website :Trained Models & Pipelines · spaCy Models Documentation
extracted_sentences=" As the business continues to generate sales of goods , Its data is important to its own marketing planning 、 Market analysis 、 Logistics planning is of great significance . However, there are many factors influencing the sales forecast , The traditional measurement model based on statistics , For example, time series models have too many assumptions about reality , Resulting in poor prediction results . Therefore, we need better intelligence AI Algorithm , To improve the accuracy of the prediction , So as to help enterprises reduce inventory costs 、 Shorten lead time 、 Improve the anti risk ability of enterprises ."
import zh_core_web_sm
nlp = zh_core_web_sm.load()
doc = nlp(extracted_sentences)
print([(w.text, w.pos_) for w in doc])
Output :[(' With ', 'ADP'), (' Enterprises ', 'NOUN'), (' continued ', 'ADV'), (' produce ', 'VERB'), (' Of ', 'PART'), (' goods ', 'NOUN'), (' sales ', 'NOUN'), (',', 'PUNCT'), (' Its ', 'PRON'), (' data ', 'NOUN'), (' about ', 'ADP'), (' Oneself ', 'PRON'), (' marketing ', 'NOUN'), (' planning ', 'NOUN'), ('、', 'PUNCT'), (' market ', 'NOUN'), (' analysis ', 'NOUN'), ('、', 'PUNCT'), (' logistics ', 'NOUN'), (' planning ', 'NOUN'), (' all ', 'ADV'), (' Yes ', 'VERB'), (' important ', 'ADJ'), (' significance ', 'NOUN'), ('.', 'PUNCT'), (' however ', 'ADV'), (' sales ', 'VERB'), (' forecast ', 'NOUN'), (' Of ', 'PART'), (' influence ', 'NOUN'), (' factors ', 'NOUN'), (' various ', 'VERB'), (',', 'PUNCT'), (' Tradition ', 'ADJ'), (' Of ', 'PART'), (' be based on ', 'ADP'), (' Statistics ', 'NOUN'), (' Of ', 'PART'), (' metering ', 'NOUN'), (' Model ', 'NOUN'), (',', 'PUNCT'), (' such as ', 'ADV'), (' Time ', 'NOUN'), (' Sequence ', 'NOUN'), (' Model ', 'NOUN'), (' etc. ', 'PART'), (' because ', 'ADP'), (' Yes ', 'ADP'), (' reality ', 'NOUN'), (' Of ', 'PART'), (' hypothesis ', 'NOUN'), (' situation ', 'NOUN'), (' too ', 'ADV'), (' many ', 'VERB'), (',', 'PUNCT'), (' Lead to ', 'VERB'), (' forecast ', 'NOUN'), (' result ', 'NOUN'), (' a ', 'ADV'), (' Bad ', 'VERB'), ('.', 'PUNCT'), (' therefore ', 'ADV'), (' need ', 'VERB'), (' more ', 'ADV'), (' good ', 'VERB'), (' Of ', 'PART'), (' intelligence ', 'NOUN'), ('AI Algorithm ', 'NOUN'), (',', 'PUNCT'), (' With ', 'PART'), (' Improve ', 'VERB'), (' forecast ', 'NOUN'), (' Of ', 'PART'), (' accuracy ', 'NOUN'), (',', 'PUNCT'), (' thus ', 'ADV'), (' help ', 'NOUN'), (' Enterprises ', 'NOUN'), (' Reduce ', 'VERB'), (' stock ', 'NOUN'), (' cost ', 'NOUN'), ('、', 'PUNCT'), (' To shorten the ', 'VERB'), (' delivery ', 'VERB'), (' cycle ', 'NOUN'), ('、', 'PUNCT'), (' Improve ', 'VERB'), (' Enterprises ', 'NOUN'), (' resist ', 'NOUN'), (' risk ', 'NOUN'), (' Ability ', 'NOUN'), ('.', 'PUNCT')]
For the labels of part of speech tagging, please refer to :Universal POS tags
Official website :The Stanford Natural Language Processing Group
You also need to download the software , It also needs to be Java1.8+ To run , There is some trouble for me . await a vacancy or job opening .