前言
梯度
前向傳播
反向傳播
開始訓練
前言在這篇文章中,准備用 Python 從頭開始實現一個全連接的神經網絡。你可能會問,為什麼需要自己實現,有很多庫和框架可以為我們做這件事,比如 Tensorflow、Pytorch 等。這裡只想說只有自己親手實現了,才是自己的。
想到今天自己從接觸到從事與神經網絡相關工作已經多少 2、3 年了,其中也嘗試用 tensorflow 或 pytorch 框架去實現一些經典網絡。不過對於反向傳播背後機制還是比較模糊。
梯度梯度是函數上升最快方向,最快的方向也就是說這個方向函數形狀很陡峭,那麼也是函數下降最快的方向。
雖然關於一些理論、梯度消失和結點飽和可以輸出一個 1、2、3 但是深究還是沒有底氣,畢竟沒有自己動手去實現過一個反向傳播和完整訓練過程。所以感覺還是浮在表面,知其所以然而。
因為最近有一段空閒時間、所以利用這段休息時間將要把這部分知識整理一下、深入了解了解
類型符號說明表達式維度 標量n^LnL表示第 L 層神經元的數量 向量B^LBL表示第 L 層偏置 n^L \times 1nL×1矩陣W^LWL表示第 L 層的權重 n^L \times n^LnL×nL向量Z^LZL表示第 L 層輸入到激活函數的值Z^L=W^LA^{(L-1)} + B^LZL=WLA(L−1)+BLn^L \times 1nL×1向量A^LAL表示第 L 層輸出值A^L = \sigma(Z^L)AL=σ(ZL)n^L \times 1nL×1我們大家可能都了解訓練神經網絡的過程,就是更新網絡參數,更新的方向是降低損失函數值。也就是將學習問題轉換為了一個優化的問題。那麼如何更新參數呢?我們需要計算參與訓練參數相對於損失函數的導數,然後求解梯度,然後使用梯度下降法來更新參數,迭代這個過程,可以找到一個最佳的解決方案來最小化損失函數。
我們知道反向傳播主要就是用來結算損失函數相對於權重和偏置的導數
可能已經聽到或讀到了,很多關於在網絡通過反向傳播來傳遞誤差的信息。然後根據神經元的 w 和 b 對偏差貢獻的大小。也就是將誤差分配到每一個神經元上。 但這裡的誤差(error)是什麼意思呢?這個誤差的確切的定義又是什麼?答案是這些誤差是由每一層神經網絡所貢獻的,而且某一層的誤差是後繼層誤差基礎上分攤的,網絡中第 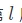 層的誤差用
層的誤差用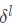 來表示。
來表示。
反向傳播是基於 4 個基本方程的,通過這些方程來計算誤差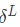 和損失函數,這裡將這 4 個方程一一列出
和損失函數,這裡將這 4 個方程一一列出
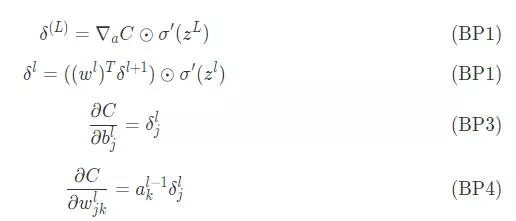
關於如何解讀這個 4 個方程,隨後想用一期分享來說明。
class NeuralNetwork(object): def __init__(self): pass def forward(self,x): # 返回前向傳播的 Z 也就是 w 和 b 線性組合,輸入激活函數前的值 # 返回激活函數輸出值 A # z_s , a_s pass def backward(self,y,z_s,a_s): #返回前向傳播中學習參數的導數 dw db pass def train(self,x,y,batch_size=10,epochs=100,lr=0.001): pass我們都是神經網絡學習過程,也就是訓練過程。主要分為兩個階段前向傳播和後向傳播
在前向傳播函數中,主要計算傳播的 Z 和 A,關於 Z 和 A 具體是什麼請參見前面表格
在反向傳播中計算可學習變量 w 和 b 的導數
def __init__(self,layers = [2 , 10, 1], activations=['sigmoid', 'sigmoid']): assert(len(layers) == len(activations)+1) self.layers = layers self.activations = activations self.weights = [] self.biases = [] for i in range(len(layers)-1): self.weights.append(np.random.randn(layers[i+1], layers[i])) self.biases.append(np.random.randn(layers[i+1], 1))layers 參數用於指定每一層神經元的個數
activations 為每一層指定激活函數,也就是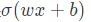
來簡單讀解一下代碼 assert(len(layers) == len(activations)+1)
for i in range(len(layers)-1): self.weights.append(np.random.randn(layers[i+1], layers[i])) self.biases.append(np.random.randn(layers[i+1], 1))因為權重連接每一個層神經元的 w 和 b ,也就兩兩層之間的方程,上面代碼是對
前向傳播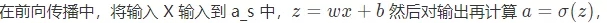
def feedforward(self, x): # 返回前向傳播的值 a = np.copy(x) z_s = [] a_s = [a] for i in range(len(self.weights)): activation_function = self.getActivationFunction(self.activations[i]) z_s.append(self.weights[i].dot(a) + self.biases[i]) a = activation_function(z_s[-1]) a_s.append(a) return (z_s, a_s)這裡激活函數,這個函數返回值是一個函數,在 python 用 lambda 來返回一個函數,這裡簡答留下一個伏筆,隨後會對其進行修改。
@staticmethod def getActivationFunction(name): if(name == 'sigmoid'): return lambda x : np.exp(x)/(1+np.exp(x)) elif(name == 'linear'): return lambda x : x elif(name == 'relu'): def relu(x): y = np.copy(x) y[y<0] = 0 return y return relu else: print('Unknown activation function. linear is used') return lambda x: x[@staticmethod]def getDerivitiveActivationFunction(name): if(name == 'sigmoid'): sig = lambda x : np.exp(x)/(1+np.exp(x)) return lambda x :sig(x)*(1-sig(x)) elif(name == 'linear'): return lambda x: 1 elif(name == 'relu'): def relu_diff(x): y = np.copy(x) y[y>=0] = 1 y[y<0] = 0 return y return relu_diff else: print('Unknown activation function. linear is used') return lambda x: 1反向傳播這是本次分享重點
def backpropagation(self,y, z_s, a_s): dw = [] # dC/dW db = [] # dC/dB deltas = [None] * len(self.weights) # delta = dC/dZ 計算每一層的誤差 # 最後一層誤差 deltas[-1] = ((y-a_s[-1])*(self.getDerivitiveActivationFunction(self.activations[-1]))(z_s[-1])) # 反向傳播 for i in reversed(range(len(deltas)-1)): deltas[i] = self.weights[i+1].T.dot(deltas[i+1])*(self.getDerivitiveActivationFunction(self.activations[i])(z_s[i])) #a= [print(d.shape) for d in deltas] batch_size = y.shape[1] db = [d.dot(np.ones((batch_size,1)))/float(batch_size) for d in deltas] dw = [d.dot(a_s[i].T)/float(batch_size) for i,d in enumerate(deltas)] # 返回權重(weight)矩陣 and 偏置向量(biases) return dw, db首先計算最後一層誤差根據 BP1 等式可以得到下面的式子
deltas[-1] = ((y-a_s[-1])*(self.getDerivitiveActivationFunction(self.activations[-1]))(z_s[-1]))
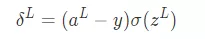
接下來基於上一層的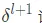 誤差來計算當前層
誤差來計算當前層

batch_size = y.shape[1]db = [d.dot(np.ones((batch_size,1)))/float(batch_size) for d in deltas]dw = [d.dot(a_s[i].T)/float(batch_size) for i,d in enumerate(deltas)]
def train(self, x, y, batch_size=10, epochs=100, lr = 0.01):# update weights and biases based on the output for e in range(epochs): i=0 while(i<len(y)): x_batch = x[i:i+batch_size] y_batch = y[i:i+batch_size] i = i+batch_size z_s, a_s = self.feedforward(x_batch) dw, db = self.backpropagation(y_batch, z_s, a_s) self.weights = [w+lr*dweight for w,dweight in zip(self.weights, dw)] self.biases = [w+lr*dbias for w,dbias in zip(self.biases, db)] # print("loss = {}".format(np.linalg.norm(a_s[-1]-y_batch) ))到此這篇關於Python 實現一個全連接的神經網絡的文章就介紹到這了,更多相關Python 全連接神經網絡內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!