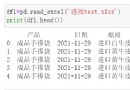
簡單使用csv.DictReader()方法
使用csv.DictReader()之fieldnames參數
使用csv.DictReader()之restkey參數
使用csv.DictReader()之restval參數
簡單使用csv.DictReader()方法示例代碼1:
import csvf = open('sample','r',encoding='utf8')reader = csv.DictReader(f)print(reader) # <csv.DictReader object at 0x000002241D730FD0>for line in reader: # reader為了方便理解我們可以把它看成是一個列錶嵌套OrderedDict(一種長相類似於列錶的數據類型) print(line) # OrderedDict([('id', '1'), ('name', 'jason'), ('age', '18')]) sample為一個txt文件,文件內容如下:
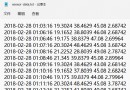
id,name,age1,jason,182,jian,203,xiaoming,304,dog,40代碼運行在終端輸出的結果為:
<csv.DictReader object at 0x000001FCF6FA0FD0> # 來自於示例代碼1中的print(reader)
OrderedDict([('id', '1'), ('name', 'jason'), ('age', '18')]) # 來自於示例代碼1中的print(line)
1 jason 18 # 來自於示例代碼1中的print(line['id'],line['name'],line['age'])
OrderedDict([('id', '2'), ('name', 'jian'), ('age', '20')])
2 jian 20
OrderedDict([('id', '3'), ('name', 'xiaoming'), ('age', '30')])
3 xiaoming 30
OrderedDict([('id', '4'), ('name', 'dog'), ('age', '40')])
4 dog 40
OrderedDict是一種長相類似於列錶的數據類型,該列錶中嵌套著元組例:line = OrderedDict([('id', '1'), ('name', 'jason'), ('age', '18')]),每個元組中的第一個元素為鍵,第二個元素為值(類似於字典),每個元組中的鍵是哪裏來的呢?==默認情況下(可以自己設置的)==csv.DictReader()讀到的第一行數據就是鍵。並且可以通過索引的方法來取出OrderedDict數據中的值print(line['id'],line['name'],line['age']) # 可以通過鍵進行索引取值(類似於字典)。
使用csv.DictReader()之fieldnames參數在reader = csv.DictReader(f,fieldnames=['new_id','new_name','new_age'])中添加參數fieldnames=['new_id','new_name','new_age']用來指定鍵。
示例代碼2:
import csvf = open('sample','r',encoding='utf8')# 通過fieldnames參數指定字段reader = csv.DictReader(f,fieldnames=['new_id','new_name','new_age'])head_row = next(reader) # next()方法用於移動指針print(reader) # <csv.DictReader object at 0x000002241D730FD0>for line in reader: # reader為了方便理解我們可以把它看成是一個列錶嵌套OrderedDict(一種長相類似於列錶的數據類型) print(line) # OrderedDict([('new_id', '2'), ('new_name', 'jian'), ('new_age', '20')]) # 通過指定的字段進行索引取值並打印輸出 print(line['new_id'],line['new_name'],line['new_age']) # 可以通過鍵進行索引取值(類似於字典)next()方法用於移動指針,示例代碼2中的head_row = next(reader)獲取的是第一行數據存儲在head_row中,執行一次next()指針移動一行,此時指針已經移動到了第二行開頭,再次讀數據的時候,就從第二行開始讀取。如果不執行head_row = next(reader)則輸出中還會多出這樣的結果OrderedDict([('new_id', 'id'), ('new_name', 'name'), ('new_age', 'age')])第一行數據也被算在了其中。
代碼運行在終端輸出的結果為:
使用csv.DictReader()之restkey參數<csv.DictReader object at 0x000001D329CF2080> # 來自於示例代碼2的print(reader)
OrderedDict([('new_id', '1'), ('new_name', 'jason'), ('new_age', '18')]) # 來自於示例代碼2的print(line)
1 jason 18 # 來自於示例代碼2的print(line['new_id'],line['new_name'],line['new_age'])
OrderedDict([('new_id', '2'), ('new_name', 'jian'), ('new_age', '20')])
2 jian 20
OrderedDict([('new_id', '3'), ('new_name', 'xiaoming'), ('new_age', '30')])
3 xiaoming 30
OrderedDict([('new_id', '4'), ('new_name', 'dog'), ('new_age', '40')])
4 dog 40
如果讀取的行具有比鍵名序列更多的值,此時則會將剩餘的數據作為值添加到restkey中的鍵下面。此時我們修改sample文件多添加一列數據。
在reader = csv.DictReader(f,fieldnames=['new_id','new_name','new_age'],restkey='hobby')中添加restkey='hobby'用來指定接收多餘值的鍵,並且要注意restkey只能傳入一個值,不能傳入列錶,元組數據類型。
sample為一個txt文件,文件內容如下:
id,name,age1,jason,18,dbj2,jian,20,lol3,xiaoming,30,game4,dog,40,noting示例代碼3:
import csvf = open('sample','r',encoding='utf8')# 通過fieldnames參數指定字段,超出fieldnames中鍵數量的值,用restkey中的鍵來接收reader = csv.DictReader(f,fieldnames=['new_id','new_name','new_age'],restkey='hobby')head_row = next(reader) # next用於移動指針print(reader) # <csv.DictReader object at 0x000002241D730FD0>for line in reader: # reader為了方便理解我們可以把它看成是一個列錶嵌套OrderedDict(一種長相類似於列錶的數據類型) print(line) # OrderedDict([('new_id', '2'), ('new_name', 'jian'), ('new_age', '20')]) # 通過指定的字段進行索引取值並打印輸出 print(line['new_id'],line['new_name'],line['new_age'],line['hobby']) # 可以通過鍵進行索引取值(類似於字典)代碼運行在終端輸出的結果為:
<csv.DictReader object at 0x000001CB6B6030F0> # 來自於示例代碼3的print(reader)
OrderedDict([('new_id', '1'), ('new_name', 'jason'), ('new_age', '18'), ('hobby', ['dbj'])]) # 來自於示例代碼3的print(line)
1 jason 18 # 來自於示例代碼3的print(line['new_id'],line['new_name'],line['new_age'])
OrderedDict([('new_id', '2'), ('new_name', 'jian'), ('new_age', '20'), ('hobby', ['lol'])])
2 jian 20
OrderedDict([('new_id', '3'), ('new_name', 'xiaoming'), ('new_age', '30'), ('hobby', ['game'])])
3 xiaoming 30
OrderedDict([('new_id', '4'), ('new_name', 'dog'), ('new_age', '40'), ('hobby', ['noting'])])
4 dog 40
從代碼運行結果中我們會發現多出來的值,確實使用restkey指定的鍵restkey='hobby'來接收了OrderedDict([('new_id', '1'), ('new_name', 'jason'), ('new_age', '18'), ('hobby', ['dbj'])])
注意雖然多餘的鍵可以用restkey指定的鍵接收,但是卻無法通過索引打印出來,也就是執行print(line["hobby"])的話就會報錯KeyError: 'hobby'。
如果讀取的行具有比鍵名序列更少的值,此時剩餘的鍵則會使用可選參數restval中的值。此時我們修改sample文件多添加一列數據。
在reader = csv.DictReader(f,fieldnames=['new_id','new_name','new_age','hobby'],restval='others')中添加restval='others'用來指定鍵對應值為空時的默認值,並且要注意restval也只能傳入一個值,不能傳入列錶,元組數據類型。
sample為一個txt文件,文件內容如下:
id,name,age1,jason,182,jian,20,lol3,xiaoming,304,dog,40,noting示例代碼4:
import csvf = open('sample','r',encoding='utf8')# 通過fieldnames參數指定字段,超出fieldnames中鍵數量的值,用restkey中的鍵來接收reader = csv.DictReader(f,fieldnames=['new_id','new_name','new_age','hobby'],restval='others')head_row = next(reader) # next用於移動指針# print(reader) # <csv.DictReader object at 0x000002241D730FD0>for line in reader: # reader為了方便理解我們可以把它看成是一個列錶嵌套OrderedDict(一種長相類似於列錶的數據類型) print(line) # OrderedDict([('new_id', '1'), ('new_name', 'jason'), ('new_age', '18'), ('hobby', 'others')]) # 通過指定的字段進行索引取值並打印輸出 print(line['new_id'],line['new_name'],line['new_age'],line['hobby']) # 可以通過鍵進行索引取值(類似於字典)代碼運行在終端輸出的結果為:
OrderedDict([('new_id', '1'), ('new_name', 'jason'), ('new_age', '18'), ('hobby', 'others')]) # 來自於示例代碼4的print(line)
1 jason 18 others # 來自於示例代碼4的print(line['new_id'],line['new_name'],line['new_age'],line['hobby'])
OrderedDict([('new_id', '2'), ('new_name', 'jian'), ('new_age', '20'), ('hobby', 'lol')])
2 jian 20 lol
OrderedDict([('new_id', '3'), ('new_name', 'xiaoming'), ('new_age', '30'), ('hobby', 'others')])3 xiaoming 30 others
OrderedDict([('new_id', '4'), ('new_name', 'dog'), ('new_age', '40'), ('hobby', 'noting')])
4 dog 40 noting
到此這篇關於python操作csv格式文件之csv.DictReader()方法的文章就介紹到這了,更多相關python csv.DictReader方法內容請搜索軟件開發網以前的文章或繼續瀏覽下面的相關文章希望大家以後多多支持軟件開發網!