In recent development requirements , This involves deleting rows with empty values in the specified columns , Access to information , Use .dropna Can meet the above requirements , To this end, I specially wrote this article for future review and learning
Missing values delete df.dropna() https://blog.csdn.net/Hudas/article/details/122924791 Data preparation
https://blog.csdn.net/Hudas/article/details/122924791 Data preparation
import pandas as pd
import numpy as np
df = pd.DataFrame([['liver',np.nan,89,21,24,64],
['Arry','C',36,37,37,57],
[np.nan,np.nan,57,60,18,84],
['Eorge','C',93,96,71,np.nan],
[None,None,65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])df
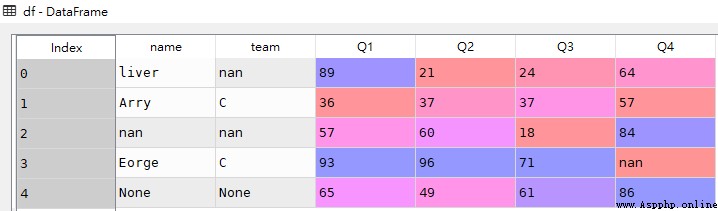
From the above df The data sheet shows that , All in all 6 Null value at
problem : Delete name,team Rows with empty values in two column fields
df = df.dropna(subset=['name','team'])df( First processing )

After the first treatment df Data sheet , You can see Eorge In that line of record Q4 Still empty (nan) , If you want to delete Q4 Empty record , The following operations can be carried out
df = df.dropna(subset=['name','team','Q4'])df( Second treatment )

Extended supplementary information
Filter and delete the row where the target value is located https://blog.csdn.net/Hudas/article/details/125394010?spm=1001.2014.3001.5501
Screening DataFrame Data rows with null values https://blog.csdn.net/Hudas/article/details/125351275?spm=1001.2014.3001.5501