The gods were silent - personal CSDN Blog Directory
fastText Python official GitHub Folder URL :fastText/python at main · facebookresearch/fastText
In this paper, fastText Python Basic tutorial of package , Including installation and simple use .
The sample Chinese text classification data used in this article comes from https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv. In addition to the work done in the text , You can also do other work such as stop word processing .
other fasttext Python For example code, please refer to :fastText/python/doc/examples at master · facebookresearch/fastText
Installation is required first numpy、scipy and pybind11.
Because I use anaconda, So the following will tend to use conda install . use pip The installation principle is similar .
numpy I'm installing PyTorch When , Installed incidentally . The command line I use is conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch. Separate installation numpy You can use conda install numpy.
install SciPy:conda install scipy
install pybind11, Refer to official documentation :Installing the library — pybind11 documentation:conda install -c conda-forge pybind11
After installing the front package , install fastText:pip install fasttext
I used to use gensim done . Later, you can compare the differences between the two packages .
Besides fasttext Word vector used in the thesis baseline It's Google's official word2vec package :Google Code Archive - Long-term storage for Google Code Project Hosting.
Official detailed tutorial :Word representations · fastText( Using the corpus of English Wikipedia , The experiment in this paper uses Chinese corpus )
because fasttext It has no Chinese word segmentation function , Therefore, you need to manually pre segment the text . The code for processing data can be referred to :
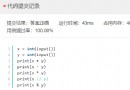
import csv,jieba
with open('data/cls/ChnSentiCorp_htl_all.csv') as f:
reader=csv.reader(f)
header = next(reader) # Header
data = [[int(row[0]),row[1]] for row in reader] # Each element is a list of strings , The first element is the tag (01), The second element is the comment text .
tofiledir='data/cls'
with open(tofiledir+'/corpus.txt','w') as f:
f.writelines([' '.join(jieba.cut(row[1]))+'\n' for row in data])
Document effect :
Learn word vectors and show the code :
import fasttext
model=fasttext.train_unsupervised('data/cls/corpus.txt',model='skipgram') #model The input parameter can be changed to `cbow`
print(model.words[:10]) # Before printing 10 Word
print(model[model.words[9]]) # Print page 10 A word vector of two words
( The presentation word vector can also be used get_word_vector(word), And you can find those that do not appear in the data data( In fact, word vectors are represented by the sum of substrings ))
Output :
Read 0M words
Number of words: 6736
Number of labels: 0
Progress: 100.0% words/sec/thread: 71833 lr: 0.000000 avg.loss: 2.396854 ETA: 0h 0m 0s
[',', ' Of ', '.', ',', ' 了 ', ' The hotel ', ' yes ', '</s>', ' very ', ' room ']
[ 1.44523270e-02 -1.14391923e-01 -1.31457284e-01 -1.59686044e-01
-4.57017310e-02 2.04045177e-01 2.00106978e-01 1.63031772e-01
1.71287894e-01 -2.93396801e-01 -1.01871997e-01 2.42363811e-01
2.78942972e-01 -4.99058776e-02 -1.27043173e-01 2.87460908e-02
3.73771787e-01 -1.69842303e-01 2.42533281e-01 -1.82482198e-01
7.33817369e-02 2.21920848e-01 2.17794716e-01 1.68730497e-01
2.16873884e-02 -3.15452456e-01 8.21631625e-02 -6.56387508e-02
9.51113254e-02 1.69942483e-01 1.13980576e-01 1.15132451e-01
3.28856230e-01 -4.43856061e-01 -5.13903908e-02 -1.74580872e-01
4.39242758e-02 -2.22267807e-01 -1.09185934e-01 -1.62346154e-01
2.11286068e-01 2.44934723e-01 -1.95910111e-02 2.33887792e-01
-7.72107393e-02 -6.28366888e-01 -1.30844399e-01 1.01614185e-01
-2.42928267e-02 4.28218693e-02 -3.78409088e-01 2.31552869e-01
3.49486321e-02 8.70033056e-02 -4.75800633e-01 5.37340902e-02
2.29140893e-02 3.87787819e-04 -5.77102527e-02 1.44286081e-03
1.33415654e-01 2.14263964e-02 9.26891491e-02 -2.24226922e-01
7.32692927e-02 -1.52607411e-01 -1.42978013e-01 -4.28122580e-02
9.64387357e-02 7.77726322e-02 -4.48957413e-01 -6.19397573e-02
-1.22236833e-01 -6.12100661e-02 -5.51685333e-01 -1.35704070e-01
-1.66864052e-01 7.26311505e-02 -4.55838069e-02 -5.94963729e-02
1.23811573e-01 6.13824800e-02 2.12341957e-02 -9.38200951e-02
-1.40030123e-03 2.17677400e-01 -6.04508296e-02 -4.68601920e-02
2.30288744e-01 -2.68855840e-01 7.73726255e-02 1.22143216e-01
3.72817874e-01 -1.87924504e-01 -1.39104724e-01 -5.74962497e-01
-2.42888659e-01 -7.35510439e-02 -6.01616681e-01 -2.18178451e-01]
Check the effect of word vectors : Search for their nearest neighbors (nearest neighbor (nn)), Give the intuitive impression that vectors capture semantic information ( If you misspell English in the course, you can also use , But how can I try Chinese , Forget it )
( The vector distance is calculated by cosine similarity )
print(model.get_nearest_neighbors(' room '))
Output :[(0.804237425327301, ' A small room '), (0.7725597023963928, ' House '), (0.7687026858329773, ' At the end of '), (0.7665393352508545, ' The first one '), (0.7633816599845886, ' But the bed '), (0.7551409006118774, ' Old '), (0.7520463466644287, ' In the room '), (0.750516414642334, ' Repression '), (0.7492958903312683, ' The smell of paint '), (0.7476236820220947, ' know ')]
word analogies( A word that predicts the relationship between the first two words and the third word ):
print(model.get_analogies(' room ',' Repression ',' Environmental Science '))
Output :[(0.7665581703186035, ' superior '), (0.7352521419525146, ' Location '), (0.7330452799797058, ' quiet '), (0.7157530784606934, ' Surrounding environment '), (0.7050396800041199, ' The natural environment '), (0.6963807344436646, ' Good service '), (0.6960451602935791, ' Good '), (0.6948464512825012, ' grace '), (0.6906660795211792, ' place '), (0.6869651079177856, ' Geography ')]
Other functions :
model.save_model(path)fasttext.load_model(path) return modelfasttext.train_unsupervised() The other parameters :
dim Vector dimension ( The default value is 100,100-300 Are common values )minnmaxn The biggest and the smallest subword Substring ( The default value is 3-6)epoch( The default value is 5)lr High learning rate will lead to faster convergence , But it may be over fitting ( The default value is 0.05, A common range of choices is [0.01, 1] )thread( The default value is 12) input # training file path (required)
model # unsupervised fasttext model {cbow, skipgram} [skipgram]
lr # learning rate [0.05]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [5]
minn # min length of char ngram [3]
maxn # max length of char ngram [6]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [ns]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
verbose # verbose [2]
fastText The official offer has been trained 300 Dimensional multilingual word vector :Wiki word vectors · fastText new edition :Word vectors for 157 languages · fastText
In the thesis, for example, use word vectors , It is necessary to quote this literature :Enriching Word Vectors with Subword Information
skipgram and cbow It should not be necessary to introduce , This is a NLP Common sense knowledge of .skipgram Use a randomly selected neighbor word to predict the target word ,cbow Use context ( In a window Inside , For example, the sum vector ) Predict the target word .
fasttext The word vector used takes into account subword Information ( Use substrings to represent the sum , As a representation of the whole ), Compared with single use word Information can get richer semantics , Faster computation , And you can get words that do not exist in the primitive .
Official detailed tutorial :Text classification · fastText( The data set used in the official tutorial is in the field of English cooking stackexchange Data sets )
First process the raw data into fasttext Classification format ( Chinese word segmentation is required manually , Label with __label__ Start with )( because fasttext Only training code and test code , So I only divided the training set and the test set ), Code reference :
import csv,jieba,random
with open('data/cls/ChnSentiCorp_htl_all.csv') as f:
reader=csv.reader(f)
header = next(reader) # Header
data = [[row[0],row[1]] for row in reader] # Each element is a list of strings , The first element is the tag (01), The second element is the comment text .
tofiledir='data/cls'
# Random sampling 80% Training set ,20% Test set
random.seed(14560704)
random.shuffle(data)
split_point=int(len(data)*0.8)
with open(tofiledir+'/train.txt','w') as f:
train_data=data[:split_point]
f.writelines([' '.join(jieba.cut(row[1]))+' __label__'+row[0]+'\n' for row in train_data])
with open(tofiledir+'/test.txt','w') as f:
test_data=data[split_point:]
f.writelines([' '.join(jieba.cut(row[1]))+' __label__'+row[0]+'\n' for row in test_data])
File example :
Training classification model , And test , Print test results :
import fasttext
model=fasttext.train_supervised('data/cls/train.txt')
print(model.words[:10])
print(model.labels)
print(model.test('data/cls/test.txt'))
print(model.predict(' The hotel Environmental Science also Sure , service also very good , Namely room Of health a little bit Careless 了 some , pedestal pan wipe have to No very clean , Other aspect all not so bad . especially yes breakfast , stay I live too Of Four stars The hotel in Count as Pattern Compare many Of 了 . because The swimming pool yes stay Outside , therefore This season Go to 了 Afraid of the cold Of people Just No, Way swimming . Add comment 2007 year 11 month 16 Japan : service aspect forget 了 say One o'clock , because I fall 了 equally Little things stay The hotel , also think Even if the 了 , little does one think yesterday Leave , today Just received mail remind I say I fall 了 thing , ask I need No need they to Send Come back , this One o'clock Than There are some The hotel want good quite a lot .'))
Output :
Read 0M words
Number of words: 26133
Number of labels: 2
Progress: 100.0% words/sec/thread: 397956 lr: 0.000000 avg.loss: 0.353336 ETA: 0h 0m 0s
[',', ' Of ', '.', ',', ' 了 ', ' The hotel ', ' yes ', '</s>', ' very ', ' room ']
['__label__1', '__label__0']
(1554, 0.8783783783783784, 0.8783783783783784)
(('__label__1',), array([0.83198541]))
test() The output of the function is : Sample size ,[email protected],[email protected]
( This [email protected] The percentage of tags with the highest score that belong to the correct tag , You can refer to :IR-ratio: Precision-at-1 and Reciprocal Rank[email protected] Is the probability that the correct tag will be predicted )
predict() Function can also pass in a list of strings .
test() and predict() Input k You can specify the number of tags returned , The default is 1.
The way to store and load model files is similar to the word vector model in Section 2 .
train_supervised() Other parameters into :
epoch( The default value is 5)lr( The range of good effects is 0.1-1)wordNgrams use n-gram instead of unigram( When using word order is an important classification task ( Like emotional analysis ) Time is important )bucketdimlosshs (hierarchical softmax) Substitute standard softmax, It can speed up the operation one-vs-all or ova:multi-label normal form , Model each tag as a separate one-label Classification task ( Compared with other loss functions , It is suggested to lower the learning rate .predict() When you specify k=-1 Output as many predicted results as possible ,threshold Specify the label whose output is greater than the threshold .test() Directly specify k=-1) input # training file path (required)
lr # learning rate [0.1]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [1]
minCountLabel # minimal number of label occurences [1]
minn # min length of char ngram [0]
maxn # max length of char ngram [0]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [softmax]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
label # label prefix ['__label__']
verbose # verbose [2]
pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []
If the text classification function is used in the paper, it is necessary to quote the literature :Bag of Tricks for Efficient Text Classification
Feeling is a simple model of intuition , Calculate the word vector and find the average value , Calculate output labels . Specific details to be supplemented .
# with the previously trained `model` object, call :
model.quantize(input='data.train.txt', retrain=True)
# then display results and save the new model :
print_results(*model.test(valid_data))
model.save_model("model_filename.ftz")

Method :
get_dimension # Get the dimension (size) of a lookup vector (hidden layer).
# This is equivalent to `dim` property.
get_input_vector # Given an index, get the corresponding vector of the Input Matrix.
get_input_matrix # Get a copy of the full input matrix of a Model.
get_labels # Get the entire list of labels of the dictionary
# This is equivalent to `labels` property.
get_line # Split a line of text into words and labels.
get_output_matrix # Get a copy of the full output matrix of a Model.
get_sentence_vector # Given a string, get a single vector represenation. This function
# assumes to be given a single line of text. We split words on
# whitespace (space, newline, tab, vertical tab) and the control
# characters carriage return, formfeed and the null character.
get_subword_id # Given a subword, return the index (within input matrix) it hashes to.
get_subwords # Given a word, get the subwords and their indicies.
get_word_id # Given a word, get the word id within the dictionary.
get_word_vector # Get the vector representation of word.
get_words # Get the entire list of words of the dictionary
# This is equivalent to `words` property.
is_quantized # whether the model has been quantized
predict # Given a string, get a list of labels and a list of corresponding probabilities.
quantize # Quantize the model reducing the size of the model and it's memory footprint.
save_model # Save the model to the given path
test # Evaluate supervised model using file given by path
test_label # Return the precision and recall score for each label.
model.words # equivalent to model.get_words()
model.labels # equivalent to model.get_labels()
model['king'] # equivalent to model.get_word_vector('king')
'king' in model # equivalent to `'king' in model.get_words()`