print(sum(range(1,101)))
5050
a=10
def func():
a=20
print(a)
func()
print(a)
Execution results :20,10
a=10
def func():
global a
a=20
print(a)
func()
print(a)
Execution results :20,20
import os
import sys
import time
import datetime
import random
import re
Delete key
Method 1 : Use pop()
Method 2 : Use del
dic = {
'a': 1, 'b': 2}
dic1 = {
'c': 3, 'd': 4}
dic.pop('b')
print(dic)
del dic1['c']
print(dic1)
Merge dictionaries
update: You can merge dictionaries
dic = {
'a': 1, 'b': 2}
dic1 = {
'c': 3, 'd': 4}
dic.update(dic1)
print(dic)
Execution results :{‘a’: 1, ‘b’: 2, ‘c’: 3, ‘d’: 4}
Multithreads in a process share data in the process , In a single cpu Within the time frame , If a thread has not finished executing , And there is no continuity cpu Time slice , At this point, the subsequent thread also starts to execute the task , There will be data confusion , That is, the thread is not safe . resolvent : Lock , Ensure that only one thread is executing a task at a certain time .
li=[2,3,4,5,6]
li1=[4,5,6,7,8]
li.extend(li1)
ll=list(set(li))
print(ll)
*args,**kwargs) Medium *args,**kwargs What does that mean? *args: Receive all unmatched position parameters in the actual parameters **kwargs: Receive all unmatched keyword parameters in the actual parameters
Functions can be passed as parameters
str
int
float
bool
list
tuple
dict
set
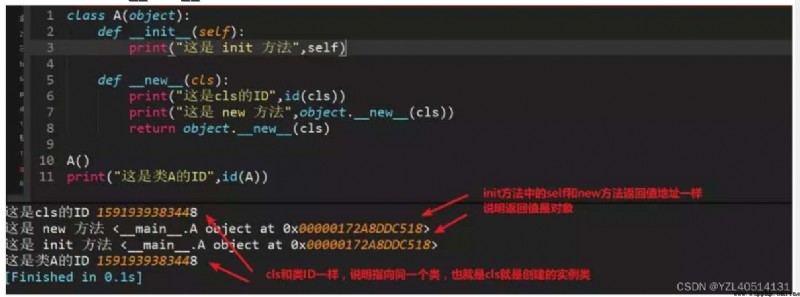
__new__ and __init__ difference __new__:
a、 For creating objects , Give the created object to __init__ Method
b、 Pass at least one parameter cls, Represents the current class
c、 There must be a return value , Return the instantiated instance
__init__:
a、 Used to initialize objects , The prerequisite is that the object must be created , Once the object is created, it is called by default , Can receive parameters .
b、 The first parameter bit self, This is this.__new__The returned instance ;__init__stay__new__Can complete some other initialization actions on the basis of
c、__init__You don't need to return a value
d、 If__new__Create an instance of the current class , Automatically called__init__function , adopt return Statement__new__First argument to function cls To ensure that it is the current class instance ; If it's the class name of another class , Then the actual creation returns instances of other classes , In fact, the current class will not be called__init__function , No other classes will be called__init__function .
If you use conventional f.open() How to write it , We need to try、except、finally, Make abnormal judgment , And in the end, whatever happens to the file , To perform all finally f.close() Close file .
f=open('./1.txt','w')
try:
f.write("hello")
except:
pass
finally:
f.close()
Use with Method
with open('a.txt') as f:
print(f.read())
perform with After this structure .f It will automatically turn off . It's equivalent to bringing a finally.
however with There is no exception capture function in itself , But if a runtime exception occurs , It can still close files and free resources .
Method 1 :
a=[1,2,3,4,5]
def func1(x):
return x**2
aa=map(func1,a)
new_aa=[i for i in aa if i>10]
print(new_aa)
Method 2 :
l=[1,2,3,4,5]
ll=list(map(lambda x:x*x,l))
lll=[i for i in ll if i>10]
print(lll)
random.random(): Random generation 0 To 1 Decimal between
:.3f: Retain 3 Significant digits
import random
num=random.randint(1,6)
num1=random.random()
print(num)
print(num1)
print('{:.3f}'.format(num1))
a=3
assert(a>1)
print(a) #3
a=3
assert(a>6)
print(a)
Assertion failed
Traceback (most recent call last):
File "D:\log\ceshi_log\face_1.py", line 64, in <module>
assert(a>6)
AssertionError
The history blog has detailed answers , Assignment by value and assignment by reference
Collection can de duplicate strings
s = 'ajldjlajfdljfddd'
s1=list(set(s))
s1.sort()
s2=''.join(s1)
print(s2)
Particular attention : Out of commission split() Method
s1=s.split()
print(s1)
['ajldjlajfdljfddd']
sum=lambda a,b:a*b
print(sum(3,4))
12
dict1.items(): Get the key value in the dictionary , And keys and values are combined into a tuple
dict1={
"name":"zs","city":"beijing","tel":1243124}
print(dict1.items())
dd=sorted(dict1.items(),key=lambda x:x[0])
print(dd)
new_dict={
}
for item in dd:
new_dict[item[0]]=item[1]
print(new_dict)
Count the number of occurrences of each word in the string :
from collections import Counter
res=Counter(a)
from collections import Counter
a="werwerwegdfgerwewed;wer;wer;6"
from collections import Counter
res=Counter(a)
print(res)
Execution results :
Counter({‘e’: 8, ‘w’: 7, ‘r’: 5, ‘;’: 3, ‘g’: 2, ‘d’: 2, ‘f’: 1, ‘6’: 1})
a=[1,2,3,4,5,6,7,8,9,10]
def func(x):
return x%2==1
newlist=filter(func,a)
newlist=[i for i in newlist]
print(newlist)
Execution results :
[1, 3, 5, 7, 9]
a=[1,2,3,4,5,6,7,8,9,10]
aa=[i for i in a if i%2==1]
print(aa)
Execution results :
[1, 3, 5, 7, 9]
a=(1,)
b=(1)
c=('1')
print(type(a))
print(type(b))
print(type(c))
Execution results :
<class ‘tuple’>
<class ‘int’>
<class ‘str’>
List together : Merge list
extend
a=[1,3,4,5,6]
b=[1,3,56,7,7,5]
c=a+b
a.extend(b)
a.sort()
print(c)
print(a)
l=[[1,2],[3,4],[5,6]]
new_list=[]
for item in l:
for i in item:
new_list.append(i)
print(newlist)
Execution results :
[1, 3, 5, 7, 9]
join(): In parentheses are iteratable objects ,x Insert in the middle of an iteratable object , Form a string , Consistent result
x = "abc"
y = "def"
z = ["d", "e", "f"]
x_1=x.join(y)
print(x_1)
x_2=x.join(z)
print(x_2)
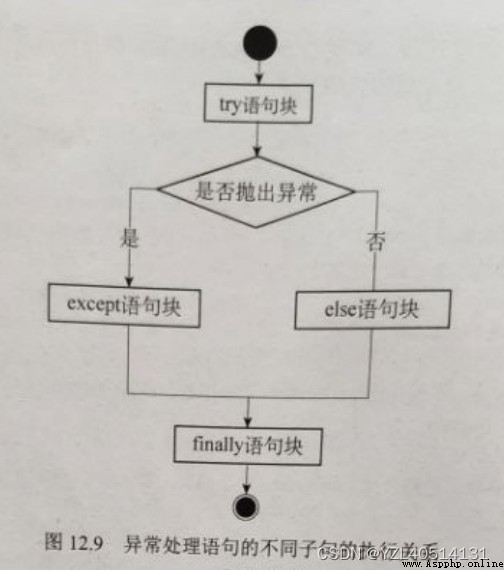
try except else No exception was caught , perform else sentence
try except finally Whether or not an exception is caught , All implemented finally sentence
a=12
b=23
a,b=b,a
print(a)
print(b)
a、zip() Function in operation , In one or more sequences ( Iteratable object ) As a parameter , Returns a list of tuples , At the same time, pair the elements side by side in these sequences .
b、zip() Function can receive any type of sequence , There can also be 2 More than parameters ; When the parameters passed in are different ,zip It can automatically intercept the shortest sequence , Get tuple .
a=[1,2,3]
b=[5,6,7]
res=list(zip(a,b))
print(res)
a=(1,2,3)
b=(5,6,7)
res1=list(zip(a,b))
print(res1)
a=(1,2)
b=(5,6,7)
res2=list(zip(a,b))
print(res2)
Execution results :
[(1, 5), (2, 6), (3, 7)]
[(1, 5), (2, 6), (3, 7)]
[(1, 5), (2, 6)]
print([1,2,3]+[4,5,6])
print([1,2,3]+[3,4,5,6])
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 3, 4, 5, 6]
1、 Adopt generator , Do not use lists and list derivations , Save a lot of memory
2、 Multiple if elif else Conditional statements , Write the most likely conditions first , This can reduce the number of program judgments , Increase of efficiency .
3、 Loop code optimization , Avoid too much repetitive code execution
4、 Multi process 、 Multithreading 、 coroutines
redis: Memory non relational database , Data is stored in memory , Fast
mysql: Relational database , The data is stored on disk , Search words , There will be a certain amount of IO operation , The access speed is relatively slow
list1=[2,3,5,4,9,6]
def list_str(list):
num=len(list)
for i in range(num-1):
for j in range(num-1-i):
if list[j]>list[j+1]:
list[j],list[j+1]=list[j+1],list[j]
print(list)
list_str(list1)
[2, 3, 4, 5, 6, 9]
class Create_Object:
obj=None
def __new__(cls, *args, **kwargs):
if obj is None:
cls.obj=super().__new__(cls)
return cls.obj
object=Create_Object
object1=Create_Object
print(id(object))
print(id(object1))
2944204723184
2944204723184
round(3.1415926,2):2 Means to keep the decimal point 2 position
num='{:.2f}'.format(3.4564564)
print(num)
num1=round(3.4564564,3)
print(num1)
3.46
3.456
fn(“one”,1): Pass the key value directly to the dictionary
fn(“two”,2): Because dictionaries are variable data types , So it points to the same memory address , After passing in the new parameter , It is equivalent to adding value to the dictionary
fn(“three”,3,{}): A new dictionary has been passed in , So it is no longer the default dictionary
def fn(k,v,div={
}):
div[k]=v
print(div)
fn("one",1)
fn("two",2)
fn("three",3,{
})
{‘one’: 1}
{‘one’: 1, ‘two’: 2}
{‘three’: 3}
a=[("a",1),("b",2),("c",3),("d",4),("e",5)]
A=zip(("a","b","c","d","e"),(1,2,3,4,5))
print(dict(A))
B=dict([["name","zs"],["age",18]])
C=dict([("name","ls"),("age",20)])
print(B)
print(C)
The history blog explains in detail
__init__: Initialize object__new__: Create objects__str__: Returns the description of the instance object__dict__: If it is a class to call , Represents all class properties and methods in the statistics class ; If it is an object to call , The statistics are instance properties__del__: Methods to delete object execution__next__: Generator object to call , Keep returning data from the generator
d=" sdf fg "
e=d.strip(' ')
print(e)
sort: Sort the original list , Only the list can be sorted
f=[1,4,6,3,2,4]
f.sort()
print(f)
[1, 2, 3, 4, 4, 6]
f1=(1,4,6,3,2,4)
f1.sort()
print(f1)
An error is reported when sorting tuples
Traceback (most recent call last):
File “D:\log\ceshi_log\face_1.py”, line 249, in
f1.sort()
AttributeError: ‘tuple’ object has no attribute ‘sort’
sorted: Sort the objects that can be iterated , After sorting, new iteratable objects are generated ( list )
f1=(1,4,6,3,2,4)
g=sorted(f1)
print(g,id(g))
print(f1,id(f1))
Execution results
[1, 2, 3, 4, 4, 6] 1646645367488
(1, 4, 6, 3, 2, 4) 1646643170272
f=[1,2,4,6,3,-6,5,7,-1]
f1=sorted(f,key=lambda x:x)
print(f1)
Don't use lambda Function to sort the data from small to large
f=[1,2,4,6,3,-6,5,7,-1]
f1=sorted(f)
print(f1)
Don't use lambda Function sorts data from large to small
f=[1,2,4,6,3,-6,5,7,-1]
f1=sorted(f,reverse=True)
print(f1)
foo=[-5,8,0,4,9,-4,-20,-2,8,2,-4]
foo1=sorted(foo,key=lambda x:(x<0,abs(x)))
print(foo1)
[0, 2, 4, 8, 8, 9, -2, -4, -4, -5, -20]
foo=[{
'name':'zs','age':18},
{
'name':'li','age':24},
{
'name':'ww','age':25},]
Sort by name
foo1=sorted(foo,key=lambda x:x['name'])
print(foo1)
Sort by annual collar
foo2=sorted(foo,key=lambda x:x['age'],reverse=True)
print(foo2)
[{‘name’: ‘li’, ‘age’: 24}, {‘name’: ‘ww’, ‘age’: 25}, {‘name’: ‘zs’, ‘age’: 18}]
[{‘name’: ‘ww’, ‘age’: 25}, {‘name’: ‘li’, ‘age’: 24}, {‘name’: ‘zs’, ‘age’: 18}]
foo1=[('zs',19),('ls',18),('ww',20)]
foo2=sorted(foo1,key=lambda x:x[0])
print(foo2)
foo3=sorted(foo1,key=lambda x:x[1])
print(foo3)
[(‘ls’, 18), (‘ww’, 20), (‘zs’, 19)]
[(‘ls’, 18), (‘zs’, 19), (‘ww’, 20)]
foo2=[['zs',19],['ls',18],['ww',20]]
a=sorted(foo2,key=lambda x:x[0])
b=sorted(foo2,key=lambda x:(x[1],x[0])) # The same numbers are arranged alphabetically
print(a)
print(b)
[[‘ls’, 18], [‘ww’, 20], [‘zs’, 19]]
[[‘ls’, 18], [‘zs’, 19], [‘ww’, 20]]
Method 1 :
dict1={
"name":"zs","city":"beijing","tel":1243124}
dict1_1=sorted(dict1.items(),key=lambda x:x)
print(dict1_1) # [('city', 'beijing'), ('name', 'zs'), ('tel', 1243124)]
new_dict={
}
for i in dict1_1:
new_dict[i[0]]=i[1]
print(new_dict)
{‘city’: ‘beijing’, ‘name’: ‘zs’, ‘tel’: 1243124}
Method 2 :
dict1={
"name":"zs","city":"beijing","tel":1243124}
dict1_1=list(zip(dict1.keys(),dict1.values()))
print(dict1_1)
dict1_2=sorted(dict1_1,key=lambda x:x[0])
new_dict={
i[0]:i[1] for i in dict1_2}
print(new_dict)
dt=["name1","zs","city","beijing","tel"]
dt1=sorted(dt,key=lambda x:len(x))
print(dt1)
[‘zs’, ‘tel’, ‘city’, ‘name1’, ‘beijing’]
dt=["name1","zs","city","beijing","tel"]
dt1=sorted(dt,key=lambda x:len(x))
print(dt1)
def func_sum(number):
if number>=1:
sum=number+func_sum(number-1)
else:
sum=0
return sum
print(func_sum(6))
21
def func_sum(number):
if number==1:
return 1
else:
sum=number*func_sum(number-1)
return sum
print(func_sum(7))
5040
Method 1:
st=" re rt ty"
st1=st.replace(' ','')
print(st1)
Method 2:
st2=st.split(' ')
print(st2) #['', 're', 'rt', 'ty']
st3=''.join(st2)
print(st3)
rertty
rertty