visit Python Official website download address : https://www.python.org/downloads/
Download the installation package suitable for your system :

I use it Windows Environmental Science , So it's direct exe Package for installation .
After downloading , Double click download package , Get into Python Installation wizard , Very simple installation , You just need to use the default settings to keep clicking " next step " Until the installation is complete .
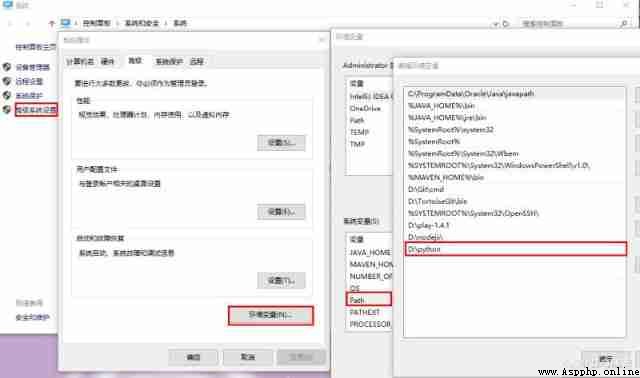
Right click on the " Computer ", Click on " attribute ";
And then click " Advanced system setup "-“ environment variable ”;
choice " System variables " Below the window “Path” , add to python The installation path ;
After successful setup , stay cmd Command line , Enter the command "python", If there is a display, the configuration is successful .
The dependent modules that our crawler needs to install include requests,lxml,pymysql , Steps are as follows :
Get into python Install under directory Scripts Catalog , Click on the address bar to enter “cmd” Open the command line tool :
Install the corresponding in this path requests,lxml,pymysql rely on :

Command to enter :
// install requests rely on
pip install requests
// install lxml rely on
pip install lxml
// install pymysql rely on
pip install pymysql
Development collectMovies.py
#!/user/bin env python
# Get movie paradise details
import requests
import time
from lxml import etree
import pymysql
requests.adapters.DEFAULT_RETRIES = 5
# Camouflage browser
HEADERS ={
'User-Agent':'Mozilla/5.(Windows NT 10.0; WOW64) AppleWebKit/537.3(KHTML, like Gecko) Chrome/63.0.3239.13Safari/537.36',
'Host':'www.dy2018.com'
}
# Define global variables
BASE_DOMAIN = 'https://www.dy2018.com/'
# Get home page information and parse
def getUrlText(url,coding):
s = requests.session()
#print(" Get home page information and parse :", url)
respons = s.get(url,headers=HEADERS)
print(" request URL:", url)
if(coding=='c'):
urlText = respons.content.decode('gbk')
html = etree.HTML(urlText) # Use lxml Parse web pages
else:
urlText = respons.text
html = etree.HTML(urlText) # Use lxml Parse web pages
s.keep_alive = False
return html
# Get the movie details page href,text analysis
def getHref(url):
html = getUrlText(url,'t')
aHref = html.xpath('//table[@class="tbspan"]//a/@href')
print(" Get the movie details page href,text analysis ```")
htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # For each href Add BASE_DOMAIN
return htmlAll
# Use content Analyze the movie details page , And get detailed information data
def getPage(url):
html = getUrlText(url,'c')
moveInfo = {} # Define movie information
mName = html.xpath('//div[@class="title_all"]//h1/text()')[0]
moveInfo['movie_name'] = mName
mDiv = html.xpath('//div[@id="Zoom"]')[0]
mImgSrc = mDiv.xpath('.//img/@src')
moveInfo['image_path'] = mImgSrc[0] # Get posters src Address
if len(mImgSrc) >= 2:
moveInfo['screenshot'] = mImgSrc[1] # Get movie screenshots src Address
mContnent = mDiv.xpath('.//text()')
def pares_info(info,rule):
'''
:param info: character string
:param rule: Replace string
:return: Replace the specified string with an empty , And eliminate the left and right spaces
'''
return info.replace(rule,'').strip()
for index,t in enumerate(mContnent):
if t.startswith('◎ translate name '):
name = pares_info(t,'◎ translate name ')
moveInfo['translation']=name
elif t.startswith('◎ slice name '):
name = pares_info(t,'◎ slice name ')
moveInfo['movie_title']=name
elif t.startswith('◎ year generation '):
name = pares_info(t,'◎ year generation ')
moveInfo['movie_age']=name
elif t.startswith('◎ production The earth '):
name = pares_info(t,'◎ production The earth ')
moveInfo['movie_place']=name
elif t.startswith('◎ class other '):
name = pares_info(t,'◎ class other ')
moveInfo['category']=name
elif t.startswith('◎ language said '):
name = pares_info(t,'◎ language said ')
moveInfo['language']=name
elif t.startswith('◎ word The tent '):
name = pares_info(t,'◎ word The tent ')
moveInfo['subtitle']=name
elif t.startswith('◎ Release date '):
name = pares_info(t,'◎ Release date ')
moveInfo['release_date']=name
elif t.startswith('◎ Douban score '):
name = pares_info(t,'◎ Douban score ')
moveInfo['douban_score']=name
elif t.startswith('◎ slice Long '):
name = pares_info(t,'◎ slice Long ')
moveInfo['file_length']=name
elif t.startswith('◎ guide Play '):
name = pares_info(t,'◎ guide Play ')
moveInfo['director']=name
elif t.startswith('◎ Ed Drama, '):
name = pares_info(t, '◎ Ed Drama, ')
writers = [name]
for i in range(index + 1, len(mContnent)):
writer = mContnent[i].strip()
if writer.startswith('◎'):
break
writers.append(writer)
moveInfo['screenwriter'] = writers
elif t.startswith('◎ Lord Play '):
name = pares_info(t, '◎ Lord Play ')
actors = [name]
for i in range(index+1,len(mContnent)):
actor = mContnent[i].strip()
if actor.startswith('◎'):
break
actors.append(actor)
moveInfo['stars'] = " ".join(actors)
elif t.startswith('◎ mark sign '):
name = pares_info(t,'◎ mark sign ')
moveInfo['tags']=name
elif t.startswith('◎ Jane Medium '):
name = pares_info(t,'◎ Jane Medium ')
profiles = []
for i in range(index + 1, len(mContnent)):
profile = mContnent[i].strip()
if profile.startswith('◎ awards ') or '【 Download address 】' in profile:
break
profiles.append(profile)
moveInfo['introduction']=" ".join(profiles)
elif t.startswith('◎ awards '):
name = pares_info(t,'◎ awards ')
awards = []
for i in range(index + 1, len(mContnent)):
award = mContnent[i].strip()
if '【 Download address 】' in award:
break
awards.append(award)
moveInfo['awards']=" ".join(awards)
moveInfo['movie_url'] = url
return moveInfo
# Before acquisition n Page details of all movies href
def spider():
# Connect to database
base_url = 'https://www.dy2018.com/html/gndy/dyzz/index_{}.html'
moves = []
m = int(input(' Please enter the start page you want to get :'))
n = int(input(' Please enter the end page you want to get :'))
print(' About to write the {} To the first page {} Page of movie information , Please later ...'.format(m, n))
for i in range(m,n+1):
print('******* The first {} Page movie Are written to the ********'.format(i))
if i == 1:
url = "https://www.dy2018.com/html/gndy/dyzz/"
else:
url = base_url.format(i)
moveHref = getHref(url)
print(" rest 2s After that, we can operate ")
time.sleep(2)
for index,mhref in enumerate(moveHref):
print('---- Under processing {} movie ----'.format(index+1))
move = getPage(mhref)
moves.append(move)
# Write movie information to the database
db = pymysql.connect(host='127.0.0.1',user='root', password='123456', port=3306, db=' Your database name ')
table = 'movies'
i = 1
for data in moves:
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}(id,{keys}) VALUES (null,{values})'.format(table=table, keys=keys, values=values)
try:
cursor = db.cursor()
cursor.execute(sql, tuple(data.values()))
print(' This data is successfully executed !')
if i%10==0:
db.commit()
except Exception as e:
print(' An exception occurred while writing movie information to the database !',repr(e))
db.rollback()
cursor.close()
i = i + 1
db.commit()
db.close()
print(' Write to database complete !')
if __name__ == '__main__':
spider()
CREATE TABLE `movies` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`movie_name` varchar(255) DEFAULT NULL,
`image_path` varchar(255) DEFAULT NULL,
`screenshot` varchar(255) DEFAULT NULL,
`translation` varchar(255) DEFAULT NULL,
`movie_title` varchar(255) DEFAULT NULL,
`movie_age` varchar(50) DEFAULT NULL,
`movie_place` varchar(50) DEFAULT NULL,
`category` varchar(100) DEFAULT NULL,
`language` varchar(100) DEFAULT NULL,
`subtitle` varchar(100) DEFAULT NULL,
`release_date` varchar(50) DEFAULT NULL,
`douban_score` varchar(50) DEFAULT NULL,
`file_length` varchar(255) DEFAULT NULL,
`director` varchar(100) DEFAULT NULL,
`screenwriter` varchar(100) DEFAULT NULL,
`stars` mediumtext,
`tags` varchar(255) DEFAULT NULL,
`introduction` mediumtext,
`awards` text,
`movie_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
open collectMovies.py In the directory , Enter the command to run :
python collectMovies.py
The operation results are as follows :
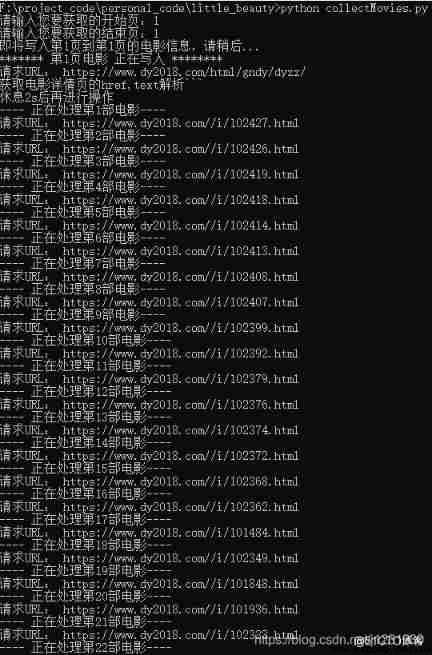
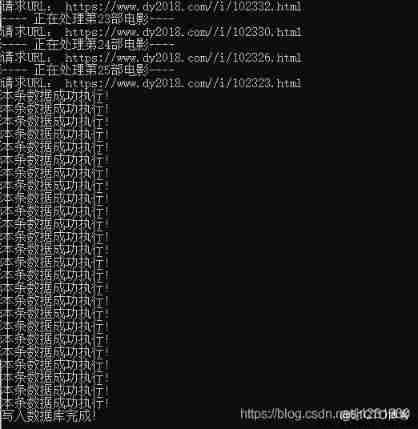
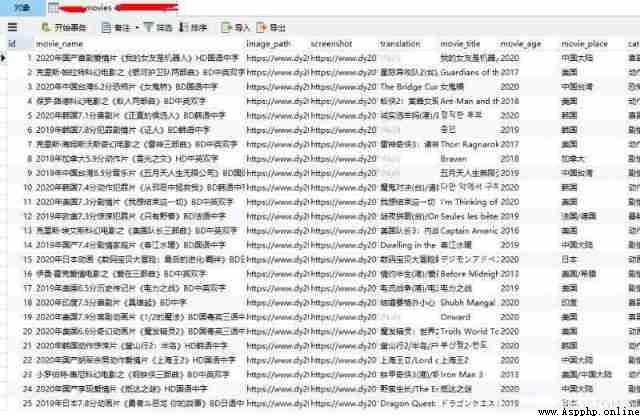
View database tables , Data inserted successfully :
unindent does not match any outer indentation level
For the first time Python, Not familiar with its rules , Space and Tab A mixture of , The operation will report the following error :
unindent does not match any outer indentation level
resolvent
download Notepad++, choice “ edit ” – “ White space character operation ” – " Space turn Tab ( Head of line )" that will do .
Modify the format and run again , Repeated requests for error , The error information mainly includes the following contents :
ssl.SSLEOFError: EOF occurred in violation of protocol
······
Max retries exceeded with url
resolvent
I thought there was something wrong with the request settings , All kinds of Baidu , And installed pip install incremental , But it still doesn't work .
Later, the requested URL was changed to Baidu. Com and no error was reported , In this way, it can be located that there is a problem with the access to the original website , The acquisition source path has been changed , The problem is solved .