用戶行為數據通常把包括:網頁浏覽、購買點擊、評分和評論等。
用戶行為在個性化推薦系統中一般分為兩種:
顯性反饋行為(explicit feedback)隱形反饋行為(implicit feedback)安裝反饋方向分,又可以分為正反饋和負反饋
在顯性反饋行為中,很容易區分一個用戶行為是正反饋還是負反饋,而在隱形反饋行為中,就相對難以確定。
在利用用戶行為數據設計推薦算法之前,研究人員需要對用戶行為數據進行分析,了解數據中蘊含的一般規律,這樣才能對算的設計起到指導作用。
協同規律有很多方法:
基於領域的方法(neighborhood-based)
基於用戶的協同過濾算法:給用戶推薦和他興趣相似的其他用戶喜歡的物品。基於物品的協同過濾算法:給用戶推薦和他之前喜歡的武平相似的物品。基於領域的算法是推薦系統中最基本的算法,該算法不僅在學術界得到了深入研究,而且在業界得到了廣泛應用。
基本思想:
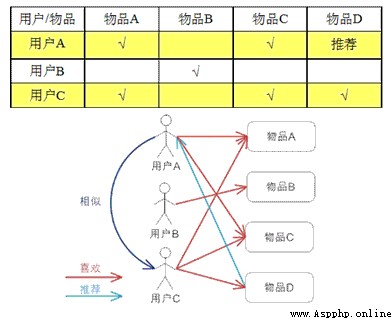
在一個在線個性化推薦系統中,當一個用戶A需要個性化推薦時,可以先找到和他有相似興趣的其他用戶,然後把那些用戶喜歡的、而用戶A沒有的物品推薦給A。
步驟:
(1)找到和目標用戶興趣相似的用戶集合。
(2)找到這個集合中的用戶喜歡的,且目標用戶木有聽說過的物品推薦給目標用戶。
ItemCollaborationFilter
核心:
給用戶推薦那些和他們之前喜歡的物品相似的物品。
主要步驟:
(1)計算物品之間的相似度;
(2)根據物品的相似度和用戶的歷史行為給用戶生成推薦列表;
原理: 用戶看過的電影之間的聯系
用戶A:看過電影 film1 和 film2,則 film1 與 film2 關系值為1。
用戶B:也看過 電影 film1 和 film2,則關系值 +1
以此類推。
使用余弦相似度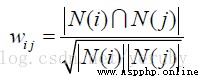
|N(i)|:喜歡物品 i 的用戶數|N(j)|:喜歡物品 j 的用戶數|N(i)&N(j)|:同時喜歡物品 i 和物品 j 的用戶數
舉例:
(1)用戶 A 對 a、b、d 有過行為,用戶 B 對物品 b、c、e 有過行為。。。
A:a、b、dB:b、c、eC:c、dD:b、c、dE:a、d
(2)依次構建用戶—物品到排表:
eg. 物品 a 被用戶 A、E 有過行為,。。。
a:A、Eb:A、B、Dc:B、C、Dd:A、C、D、Ed:B
(3)建立物品相似度矩陣 C
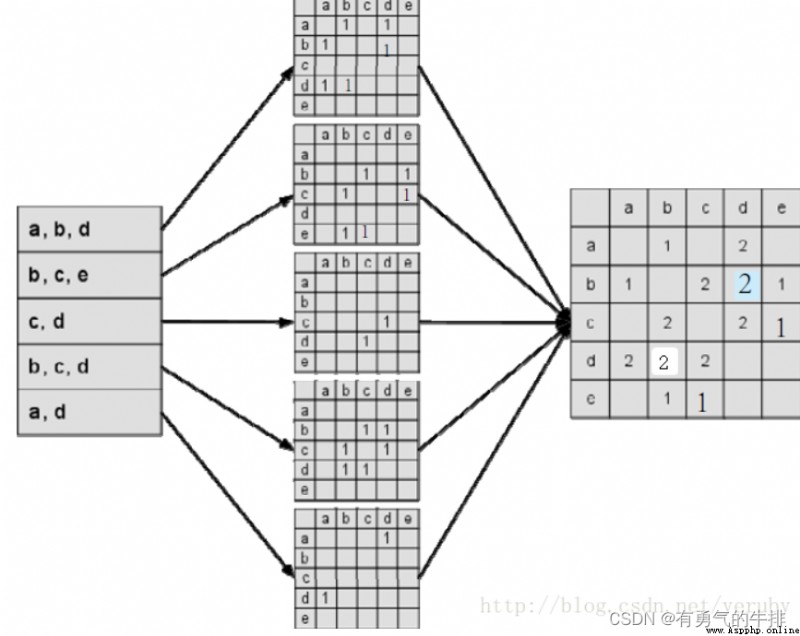
其中,C[i][j]記錄了同時喜歡物品i和物品j的用戶數,這樣我們就可以得到物品之間的相似度矩陣W。
# 計算電影間的相似度
def calc_movie_sim(self):
print('=' * 100)
print('二、計算電影的相似矩陣......')
# 建立movies_popular字典
print('-' * 35 + '1.計算電影的流行度字典movie——popular...' + '-' * 26)
for user, movies in self.trainSet.items():
for movie in movies:
""" 若該movie沒在movies_popular字典中,則把其插入字典並賦值為0,否則+1, 最終的movie_popular字典鍵為電影名,值為所有用戶總的觀看數 """
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
else:
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
# print(self.movie_popular)
print("訓練集中電影總數 = %d" % self.movie_count)
print('-' * 35 + '2.建立電影聯系矩陣... ' + '-' * 43)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
""" 下面三步的作用是: 分別將每個用戶看過的每一部電影與其他所有電影的聯系值置1,若之後又有用戶同時看了兩部電影, 則+1 """
self.movie_sim_matrix.setdefault(m1, {
})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
print("建立電影的相似矩陣成功!")
# print("矩陣進行相似計算前movieId=1的一行為:")
# print(self.movie_sim_matrix['1'])
# 計算電影之間的相似性
print('-' * 35 + '3.計算最終的相似矩陣... ' + '-' * 40)
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的處理,即某電影的用戶數為 0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('計算電影的相似矩陣成功!')
計算用戶u對外拍哪個j的興趣:
根據物品的相似度和用戶的歷史行為給用戶生成推薦列表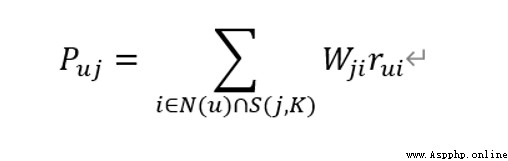
Puj:表示用戶 u 對物品 j 的興趣。N(u):表示用戶喜歡的物品集合(i:用戶喜歡的某一個物品)。S(i, k):表示和物品 i 最相似的 k 個物品集合( j 是這個集合中的某一個物品)。Wji:表示物品 j 和 i 的相似度。Rui:表示用戶 u 對物品 i 的興趣。
計算結果:和用戶歷史上感興趣的物品越相似的物品,越可能得到高的排名。
def recommend(self, user):
K = int(self.n_sim_movie)
N = int(self.n_rec_movie)
rank = {
}
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
""" 對目標用戶每一部看過的電影,從相似電影矩陣中取與這部電影關聯值最大的前K部電影, 若這K部電影用戶之前沒有看過,則把它加入rank字典中,其鍵為movieid名, 其值(即推薦度)為w(相似電影矩陣的值)與rating(用戶給出的每部電影的評分)的乘積 """
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
# 計算推薦度
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
從原理上:
UserCF給用戶推薦那些和他們有共同興趣安好的用戶喜歡的物品。
ItemCF給用戶推薦那些和他喜歡的物品類似的物品。
從原理角度可以看出,UserCF的推薦更社會化,反應了用戶所在的小型興趣群體中物品的熱門程度,而ItemCF的推薦更加個性化,反應了用戶自己的興趣傳承。
UserCF可以給用戶推薦和他有相似愛好的一群塔器用戶今天都在看的新聞,這樣在抓住任店和時效性的同時,保證了一定程度的個性化。同時,在新聞網站中,物品的更新速度遠遠快於新用戶的加入速度,而卻對於新用戶,完全可以推薦最熱門的新聞,因此UserCF利更大。
但是在圖書、電商網站中,用戶的興趣是比較固定和持久的。技術人員往往會購買專業書籍,但是很多優質數據並不是熱門書籍,所以ItemCF算法非常適合。
一天更新一次,對網站壓力會較小,但是,需要維護物品的相似性矩陣,需要更多存儲空間。
參考地址:
https://www.jianshu.com/p/a21944550656
https://blog.csdn.net/qq_40965177/article/details/106636012
https://blog.csdn.net/qq_35704904/article/details/103031962
https://blog.csdn.net/yeruby/article/details/44154009
 Django post run browser warning: devtools cannot load sourcemap: cannot load http://127.0.0.1:800/skins/css/bootstrap.min.css.map:
Django post run browser warning: devtools cannot load sourcemap: cannot load http://127.0.0.1:800/skins/css/bootstrap.min.css.map:
Use uwsgi start-up Django Afte
 Python Programming Language Learning: set a field as an index column in pandas, and specify the index column in dataframe
Python Programming Language Learning: set a field as an index column in pandas, and specify the index column in dataframe
Python Programming language le