User behavior data usually includes : Web browsing 、 Purchase Click 、 Ratings and reviews, etc .
User behavior is generally divided into two types in personalized recommendation system :
Explicit feedback behavior (explicit feedback) Invisible feedback behavior (implicit feedback) Install the feedback direction switch , Can be divided into The positive feedback and Negative feedback
In explicit feedback behavior , It's easy to tell whether a user's behavior is positive feedback or negative feedback , And in invisible feedback behavior , It is relatively difficult to determine .
Before designing recommendation algorithms using user behavior data , Researchers need to analyze user behavior data , Understand the general rules contained in the data , Only in this way can we play a guiding role in the design of calculation .
There are many ways to coordinate laws :
Domain based approach (neighborhood-based)
Collaborative filtering algorithm based on users : Recommend other users' favorite items with similar interests to users . Collaborative filtering algorithm based on items : Recommend items similar to his previous favorite Wuping to users .Domain based algorithm is the most basic algorithm in recommendation system , This algorithm has not only been deeply studied in academic circles , And it has been widely used in the industry .
The basic idea :
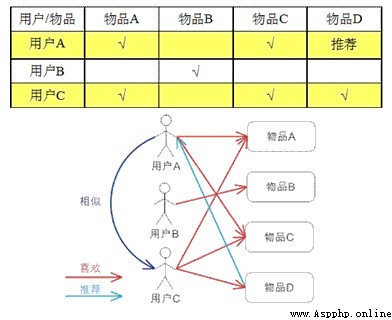
In an online personalized recommendation system , When a user A When you need a personalized recommendation , You can find other users with similar interests first , And then put those users like 、 And users A Items not recommended to A.
step :
(1) Find a set of users with similar interests to the target user .
(2) Find what users in this collection like , And the target user has heard of items recommended to the target user .
ItemCollaborationFilter
The core :
Recommend items that are similar to their previous favorite items .
Main steps :
(1) Calculate the similarity between items ;
(2) According to the similarity of items and the historical behavior of users, we can generate recommendation list for users ;
principle : The connection between movies seen by users
user A: Watching the film film1 and film2, be film1 And film2 The relationship value is 1.
user B: I've seen The movie film1 and film2, Then the relationship value +1
And so on .
Use cosine similarity 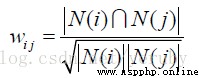
|N(i)|: Like things i Number of users |N(j)|: Like things j Number of users |N(i)&N(j)|: At the same time like things i And objects j Number of users
give an example :
(1) user A Yes a、b、d Had behavior , user B For items b、c、e Had behavior ...
A:a、b、dB:b、c、eC:c、dD:b、c、dE:a、d
(2) Build users in turn — Items to the list :
eg. goods a By user A、E Had behavior ,...
a:A、Eb:A、B、Dc:B、C、Dd:A、C、D、Ed:B
(3) Establish item similarity matrix C
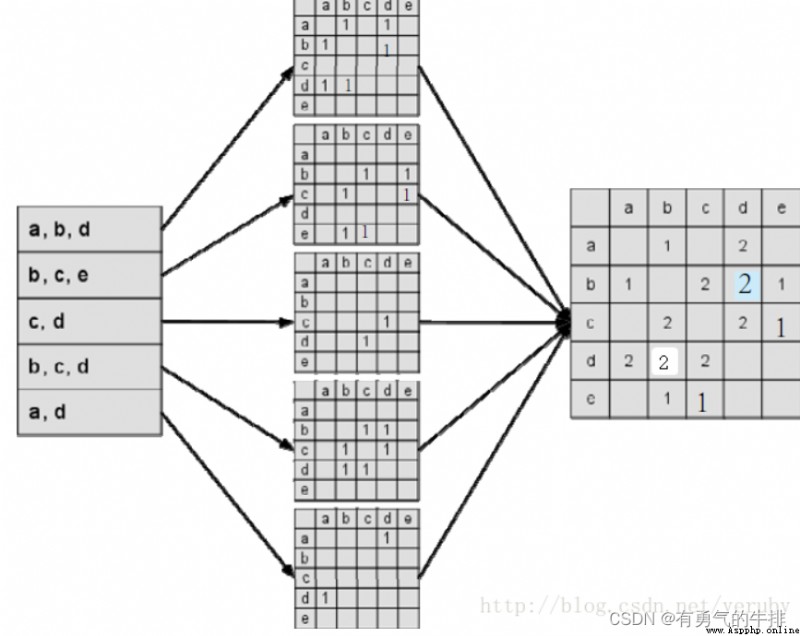
among ,C[i][j] Record the same thing you like i And objects j Number of users , In this way, we can get the similarity matrix between items W.
# Calculate the similarity between films
def calc_movie_sim(self):
print('=' * 100)
print(' Two 、 Calculate the similarity matrix of the film ......')
# establish movies_popular Dictionaries
print('-' * 35 + '1. A dictionary for calculating the popularity of movies movie——popular...' + '-' * 26)
for user, movies in self.trainSet.items():
for movie in movies:
""" If so movie Not in movies_popular In the dictionary , Then insert it into the dictionary and assign it as 0, otherwise +1, The final movie_popular The dictionary key is the movie name , The value is the total number of views of all users """
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
else:
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
# print(self.movie_popular)
print(" Total number of films in training focus = %d" % self.movie_count)
print('-' * 35 + '2. Build a movie connection matrix ... ' + '-' * 43)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
""" The next three steps are : Set the connection value between each movie seen by each user and all other movies respectively 1, If another user watches two movies at the same time , be +1 """
self.movie_sim_matrix.setdefault(m1, {
})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
print(" Build the similarity matrix of the film successfully !")
# print(" Before matrix similarity calculation movieId=1 An act of :")
# print(self.movie_sim_matrix['1'])
# Calculate the similarity between films
print('-' * 35 + '3. Calculate the final similarity matrix ... ' + '-' * 40)
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# Be careful 0 Vector processing , That is, the number of users of a movie is 0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print(' Calculate the similarity matrix of the film successfully !')
Computing users u Which one to shoot outside j The interest of :
According to the similarity of items and the historical behavior of users, we can generate recommendation list for users 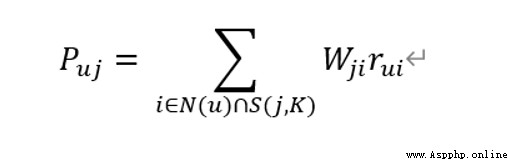
Puj: Represent user u For items j The interest of .N(u): Represents a collection of items that users like (i: An item that the user likes ).S(i, k): Presentation and items i The most similar k A collection of items ( j It's an item in this collection ).Wji: Indicates an item j and i The similarity .Rui: Represent user u For items i The interest of .
The result of the calculation is : Items that are more similar to items of interest to users in history , The more likely you are to get a high ranking .
def recommend(self, user):
K = int(self.n_sim_movie)
N = int(self.n_rec_movie)
rank = {
}
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
""" For every movie the target user has seen , From the similar movie matrix, take the top... With the largest correlation value with this movie K movie , If this K The movie users haven't seen before , Add it to rank In the dictionary , The key for movieid name , Its value ( That is, the degree of recommendation ) by w( The value of the similar movie Matrix ) And rating( The rating of each movie given by the user ) The product of the """
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
# Calculate recommendation
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
In principle :
UserCF Recommend items to users who have common interests and are well liked by users .
ItemCF Recommend items similar to his favorite items to users .
From the point of view of principle ,UserCF The recommendation is more social , It reflects the popularity of items in the user's small interest group , and ItemCF 's recommendations are more personalized , It reflects the user's own interest inheritance .
UserCF You can recommend to users a group of tower users who have similar hobbies to him. They are watching the news today , In this way, while grasping Ren store and timeliness , Guaranteed a certain degree of personalization . meanwhile , In news websites , The update speed of items is much faster than that of new users , But for new users , You can recommend the hottest news , therefore UserCF Greater profit .
But in books 、 In the e-commerce website , The interests of users are fixed and persistent . Technicians often buy professional books , But many high-quality data are not popular books , therefore ItemCF The algorithm is very suitable for .
Update once a day , There will be less pressure on the website , however , Need to maintain the similarity matrix of items , Need more storage space .
Reference address :
https://www.jianshu.com/p/a21944550656
https://blog.csdn.net/qq_40965177/article/details/106636012
https://blog.csdn.net/qq_35704904/article/details/103031962
https://blog.csdn.net/yeruby/article/details/44154009