According to the Cloudera official declaration :
2021 year 1 month 31 The day begins , all Cloudera The software needs a valid subscription to access .
Include : contain Apache Hadoop Of Cloudera Distribution version (CDH),Hortonworks Data Platform (HDP),Data Flow (HDF / CDF) and Cloudera Data Science Workbench (CDSW) .
For specific information, please refer to the description on the official website :
About Cloudera Access to software
After this , Most of cdh The resource websites have 404, perhaps 403, Bloggers are also looking for cdh Resources cost a lot of time and energy ( When it was free, no resources were stored locally , I regret it very much …)
Fortunately, , Recently found an available resource website :
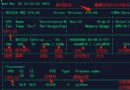
It contains all versions of cdh resources , Here's the picture :
by cdh6 Part of our resources 
Considering that the link will be unavailable sooner or later , Prepare to download all its resources to local permanent storage .
Use Python Script implementation is a very suitable solution
Be careful :
get_file When the method is called, a link to the website where you want to download the resource is passed in
vim download.py
# -*- coding: UTF-8 -*-
import urllib.request
import requests
import re, os
def get_file(url):
''' Recursively download the files of the website :param url: :return: '''
if isFile(url):
print(url)
try:
download(url)
except:
pass
else:
urls = get_url(url)
for u in urls:
get_file(u)
def isFile(url):
''' Determine whether a link is a file :param url: :return: '''
if url.endswith('/'):
return False
else:
return True
def download(url):
''' :param url: The file link :return: Download the file , Automatically create directories '''
full_name = url.split('//')[-1]
filename = full_name.split('/')[-1]
dirname = "/".join(full_name.split('/')[:-1])
if os.path.exists(dirname):
pass
else:
os.makedirs(dirname, exist_ok=True)
urllib.request.urlretrieve(url, full_name)
def get_url(base_url):
''' :param base_url: Give a URL :return: Get all links in a given URL '''
text = ''
try:
text = requests.get(base_url).text
except Exception as e:
print("error - > ",base_url,e)
pass
reg = '<a href="(.*)">.*</a>'
urls = [base_url + url for url in re.findall(reg, text) if url != '../']
return urls
if __name__ == '__main__':
get_file('https://ro-bucharest-repo.bigstepcloud.com/cloudera-repos/')
python download.py
After script execution , Resources will be downloaded under the same level directory of the script according to the directory structure of the website
A lot of resources , Make sure you have enough disk space
After downloading resources successfully , How to use it ?
We can build local yum Source
yum install -y httpd >/dev/null 2>&1
# The value here local_soft_path You need to configure it according to your actual situation
local_soft_path=/opt/modules
sudo sed -i "s#/var/www/html#$local_soft_path#g" /etc/httpd/conf/httpd.conf
service httpd restart >/dev/null 2>&1
chkconfig httpd on
After the configuration is finished , It can be done by http://{hostip} To access resources
I'm here download.py The local path corresponding to the script is :/opt/modules/cloudera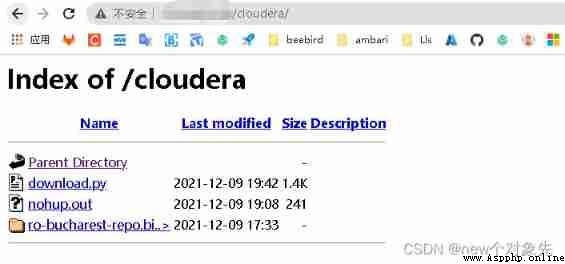
With cdh6.2.0 For example
From the website https://ro-bucharest-repo.bigstepcloud.com Downloaded configuration
vim /etc/yum.repos.d/cdh6.repo
[cloudera-cdh6]
# Packages for Cloudera's Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
name=Cloudera's Distribution for Hadoop, Version 5
baseurl=https://ro-bucharest-repo.bigstepcloud.com/cloudera-repos/cdh6/redhat/7/x86_64/cdh/6.2.0
gpgkey = https://ro-bucharest-repo.bigstepcloud.com/cloudera-repos/cdh6/redhat/7/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 1
If you are using local resources , How to configure ?
as follows ( This is my situation , according to 3.1 The operation of the steps is different , Everyone's path may be inconsistent )
[cloudera-cdh6]
# Packages for Cloudera's Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
name=Cloudera's Distribution for Hadoop, Version 5
baseurl=http://{yourlocal_ip}/cloudera/ro-bucharest-repo.bigstepcloud.com/cloudera-repos/cdh6/redhat/7/x86_64/cdh/6.2.0
gpgkey = https://{yourlocal_ip}/cloudera/ro-bucharest-repo.bigstepcloud.com/cloudera-repos/cdh6/redhat/7/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 1
Then you can enjoy it ! Mom doesn't have to worry that I can't find it anymore cdh Resources