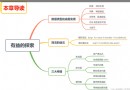
A string is an array of sequential characters , And write it in single quotation marks , In double or triple quotation marks . in addition ,Python There is no character data type , So when we write “ a” when , It will be considered to be of length 1 String .
Single quotation marks [' ']
Double quotes [" "]
Three quotes [''' ''']
Creating a string is simple , We can use quotation marks ( ’ or " ) To create a string , Just assign a value to the variable . for example :
a = 'Hello'
print(a)
b = "Hello"
print(b)
c ='''Hello
How is the whether today? '''
print(c)
# Output results
Hello
Hello
Hello
How is the whether today?
- When we use both single and double quotation marks in a string and write multiple lines of sentences , Three quotation marks are usually used
- When using single quotation marks , String should not contain single quotes , Because if that happens ,Python It is assumed that the line ends with the second quotation mark itself , And don't get the output you need
- Double and triple quotation marks should be added after the same symbol
You can intercept a part of the string and splice it with other fields , as follows :
a='hello world'
print(a)
print(' Updated string :',a[:6] + 'how are you')
# The results are as follows
hello world
Updated string : hello how are you
demonstration :
------------------------------------------------( Cross row output )----------------------------------------
print("line1 \ line2 \ line3")
# The results are as follows
line1 line2 line3
------------------------------------------------( Line break )-------------------------------------------
print("hello\nworld")
# The results are as follows
hello
world
------------------------------------------------( Horizontal tabs )---------------------------------------
print("hello \tworld")
# The execution process is as follows
hello world
------------------------------------------------( Replace )----------------------------------------
print("hello\rworld")
# The execution process is as follows
world
print('google runoob taobao\r123456')
# The execution process is as follows
123456
------------------------------------------------( Backspace )----------------------------------------
print("hello\bworld")
# The execution process is as follows
hellworld
Output multiple times in the following code " I this year XX year ", Only one xx The content of the representative is changing , Just imagine , Is there a way to simplify the procedure ?
print(" I this year 10 year ")
print(" I this year 11 year ")
print(" I this year 12 year ")
We can do this through string formatting , As shown below
print(" My name is %s, This year, %d year !" % (' Xiao Ming ',10))
# Output results
My name is Xiao Ming , This year, 10 year !
a=" my "
b=" Motherland "
print(" I love you! ,%s,%s"%(a,b))
# Output results
I love you! , my , Motherland
Common formatting symbols
Python3 Provides input Function reads a line of text from standard input , The default standard input is the keyboard .
user_name=input(" Please enter a user name :")
print(user_name)
# Output results
Please enter a user name : Zhang San
Zhang San
Each character of the string corresponds to a subscript , Subscript number from 0 Start 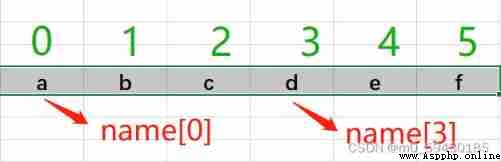
Example
a="hello,this is a apple"
print(len(a))
# Output results
21
What is slicing ? The syntax format of the slice is as follows :
[ start : end : step ]
The section selected by the slice belongs to the left closed right open type , From “ start ” Bit start , To “ end ” The last one of the first ( Does not include the end bit itself )
a="Hello,this is a super man."
print(len(a))
print(a[5]) #a[5] Indicates that the subscript in the string is 5 The characters of , The first 6 Characters
print(a[5:10]) #a[5:10] Represents that the subscript in the string is from 5 To 9 The characters of , That is to say 6 One to the first 10 Characters , barring 10
print(a[5:10:2]) #a[5:10:2] Represents that the subscript in the string is from 5 To 9 The characters of , One before every two , That is to say 6,8,10 The characters of
# Output results
26
,
,this
,hs
Assuming a string name=“abcdef”, be
name[0:3] ———— abc # from 0 Start to 2 Value
name[3:5] ————de # from 3 Start to 4 Value
name[1:-1]————bcde #1 From the first ,-1 Take from the back to the front , Not including the last one
name[2:] ————cdef # From 2 From the beginning to the end
name[::-2]————fdb # From the back to the front , In steps of 2
Common operations for strings are as follows
Check whether the string contains substrings
str.find(sub[,start[,end]])
# The parameters are as follows :
sub——》 Specifies the string to retrieve
start——》 Start index , The default is 0
end——》 End index , The default is the length of the string
Example :
a="Hello,I'm guyu"
b="Hello"
c="I'm guyu"
print(a.find(b))
print(a.find(c))
print(b.find(c))
# Output results
0
6
-1
Check whether the string contains substrings
str.index(sub[,start[,end]])
# The parameters are as follows
sub——》 Specifies the string to retrieve
start——》 Start index , The default is 0
end——》 End index , The default is the length of the string
a="Hello,I'm LiLei"
b="Hello"
c="I'm LiLei"
print(a.index(b))
print(a.index(c))
print(b.index(c)) # Because if you can't find it, you will report an error
# Output results
0
6
Traceback (most recent call last):
File "E:/PycharmProjects/str_2022.0115/str/transform.py", line 69, in <module>
print(b.index(c))
ValueError: substring not found
PS:find and index Almost the same in function , however find If it is not found, it will return a -1 , and index If it cannot be found, an error will be reported directly
Count the number of characters in a string
str.count(sub[,start[,end]])
# The parameters are as follows
sub——》 Search for substrings
start——》 Where the string starts searching
end——》 Where the string ends the search
Example :
a="Hello,I'm LiLei"
print(a.count("m",9))
print(a.count("m",8)) # From 8 Start looking for ,m The subscript of is 8, So we can find
print(a.count("m",8,1)) # If the actual subscript is larger than the ending subscript , Is equivalent to an empty string
# Output results
0
1
0
PS: If there are multiple matches , Only the first matching position will be returned
Replace the old string with the new string
str.replace(old,new[,count])
# The parameters are as follows
old——》 Replaced string
new——》 Replace with a new string
count——》 Optional parameters , Replace no more than count Time .0
Example :
a="Hello,I'm LiLei,How are you! Hello"
b="Hello"
c="I'm LiLei"
print(a.replace("LiLei","lisi")) # hold LiLei Replace with lisi 了
print(a.replace(b," Hello ")) # hold b Defined Hello, stay a All have been replaced in
print(a.replace(b," Hello ",1)) # Replace only once , Replace the previous one first
# Output results
Hello,I'm lisi,How are you! Hello Hello ,I'm LiLei,How are you! Hello
Hello ,I'm LiLei,How are you! Hello
Slice a string by specifying a separator
str.split(sep=None,maxsplit=-1)
# The parameters are as follows
sep——》 Separator , The default is all empty characters
maxsplit——》 Number of divisions
Example :
a="Hello,I'm LiLei,How are you! Hello"
print(a.split(",")) # Separate with commas
print(a.split(",",1)) # Specify the number of splits as 1 Time
# Output results
['Hello', "I'm LiLei", 'How are you! Hello']
['Hello', "I'm LiLei,How are you! Hello"]
capitalize: The first character is capitalized , Other characters are lowercase
str.capitalize()
title: All words are capitalized , The rest of the letters are lowercase
str.title()
upper: All characters are capitalized
str.upper()
lower: All characters are lowercase
str.lower()
Example :
a="hello,i'm lilei,how are you! hello"
print(a.capitalize()) # The first letter is capitalized
print(a.title()) # Capitalize the first letter after the space and symbol , Other lowercase
print(a.upper()) # All are capitalized
print(a.lower()) # All lowercase
# Output results
Hello,i'm lilei,how are you! hello Hello,I'M Lilei,How Are You! Hello
HELLO,I'M LILEI,HOW ARE YOU! HELLO hello,i'm lilei,how are you! hello
startwith: Check whether the string starts with the specified string endswith: Check whether the string ends with the specified string
str.startswith(prefix[,start[,end]])
# The parameters are as follows
prefix——》 Detected string
start——》 Optional parameters , The starting position of string detection
end——》 Optional parameters , End position of string detection
Example :
a="hello,i'm lilei,how are you! Hello"
print(a.startswith("hello",0))
print(a.startswith("Hello"))
print(a.startswith("Hello",29))
print(a.endswith("Hello"))
print(a.endswith("hello"))
print(a.endswith("hello",0,5)) #0,5 Indicates the search start subscript 0 And end subscript 5
# Execution results
True
False
True
True
False
True
Align left , Fill a new string with spaces to the specified length Right alignment , Fill a new string with spaces to the specified length
str.ljust(width[,fillchar])
str.rjust(width[,fillchar])
# The parameters are as follows
width——》 Specifies the length of the string
fillchar——》 Fill character , Default is space
Example :
b="Hello"
print(b.ljust(10,','))
print(b.rjust(10,','))
# Execution results
Hello,,,,,
,,,,,Hello
Returns a length of width And centered string
str.center(width[,fillchar])
# The parameters are as follows
width——》 Specifies the length of the string
fillchar——》 Fill character
Example :
b="Hello"
print(b.center(10,'_')) # Put the string in the middle , Left and right _ Fill to 10 A space
# Execution results
__Hello___
Intercept the space to the left of the string or the specified character
str.lstrip([chars])
# The parameters are as follows
chars——》 Specify the characters to intercept
Example :
c=" I'm LiLei "
print(c.lstrip()) # There are spaces on the left and right , Only the left
print(c.rstrip()) # There are spaces on the left and right , Only the one on the right is removed
print(a.rstrip('Hello')) # You can also remove the specified string
# Execution results
I'm LiLei I'm LiLei
hello,i'm lilei,how are you!
Format
encode(encoding='UTF-8',errors='strict')
With encoding The specified encoding format encodes the string , If there is an error, one will be reported by default ValueError It's abnormal , Unless errors Specifies the ’ignore’ perhaps ’replace’
Example :
b=" Hello "
print(b.encode("UTF-8"))
print(b.encode("GBK"))
# Execution results
b'\xe4\xbd\xa0\xe5\xa5\xbd'
b'\xc4\xe3\xba\xc3'
Delete the characters specified at the beginning and end of the string
str.strip([chars])
# The parameters are as follows
chars——》 Remove the characters specified at the beginning and end of the string
Example :
a="hello,i'm lilei,how are you! Hello"
print(a.strip('hello'))
# Execution results
,i'm lilei,how are you! H
python2.6 Version start , Added a function to format strings str.format(), It enhances string formatting The basic grammar is through {} and :
To replace the old % format Function can take any number of arguments , Positions can be out of order
Example
① The specified location
print("{} {}".format("hello","world")) # No location , By default
print("{0} {1}".format("hello","world")) # The specified location
print("{1} {0}".format("hello","world"))
print("{1} {0} {1}".format("hello","world"))
# Execution results
hello world
hello world
world hello
world hello world
② Set the parameters through the dictionary
site={
"name":" Baidu ","url":"www.baidu.com"}
print(" The websites :{name}, Address :{url}".format(**site))
# Execution results
The websites : Baidu , Address :www.baidu.com
③ Set the parameters by the list index
my_list=[" Baidu Encyclopedia ","www.baidu,com"]
print(" The websites :{0[0]}, Address :{0[1]}".format(my_list))
# Execution results
The websites : Baidu Encyclopedia , Address :www.baidu,com
Example
a="hello"
b="world"
print(a+b)
# Output results
helloworld
------------------------------------------------------------------------------------------------
a="hello"
print(a*3)
# Output results
hellohellohello
------------------------------------------------------------------------------------------------
a="hello"
b="world"
print(a[1])
# Output results
e
------------------------------------------------------------------------------------------------
a="hello"
b="world"
print(a[1:3]) # Subscript 1 To 3 Value , barring 3
# Output results
el