對原始數據的商品金額進行區間劃分,統計各個區間的訂單數
分箱使用pd.cut()
pd.cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False,duplicates='raise')
x : 一維數組
bins :整數,標量序列或者間隔索引,是進行分組的依據,
如果填入整數n,則表示將x中的數值分成等寬的n份(即每一組內的最大值與最小值之差約相等);
如果是標量序列,序列中的數值表示用來分檔的分界值
如果是間隔索引,“ bins”的間隔索引必須不重疊
right :布爾值,默認為True表示包含最右側的數值
當“ right = True”(默認值)時,則“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]
當bins是一個間隔索引時,該參數被忽略。
labels : 數組或布爾值,可選.指定分箱的標簽
如果是數組,長度要與分箱個數一致,比如“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3個區間,則labels的長度也就是標簽的個數也要是3
如果為False,則僅返回分箱的整數指示符,即x中的數據在第幾個箱子裡
當bins是間隔索引時,將忽略此參數
retbins: 是否顯示分箱的分界值。默認為False,當bins取整數時可以設置retbins=True以顯示分界值,得到劃分後的區間
precision:整數,默認3,存儲和顯示分箱標簽的精度。
include_lowest:布爾值,表示區間的左邊是開還是閉,默認為false,也就是不包含區間左邊。
duplicates:如果分箱臨界值不唯一,則引發ValueError或丟棄非唯一
可視化統計,使用pd.pivot_table()
df = pd.read_excel('新建 XLSX 工作表.xlsx',sheet_name= 'Sheet1') #讀取數據進入Python程序
data = df[['訂單號','付款時間','訂單金額','商品名稱','產品規格','商品數量','商品金額']] # 選擇需用用到的數據列
print(data.head()) # 打印數據
# 定義金額區間
je_cut =[0,10,50,100,150,200,500,100000]
je_label = ['0-10','10-50','50-100','100-150','150-200','200-500','500以上'] #給金額區間設置標簽
data['金額區間'] = pd.cut(data['商品金額'],bins=je_cut,labels= je_label)
print(data)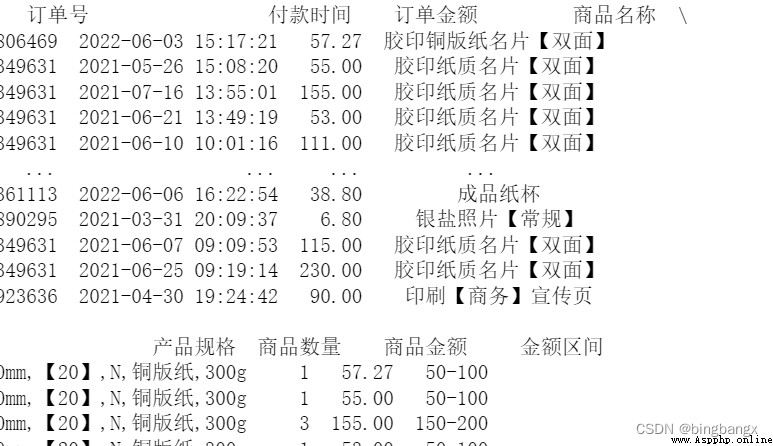
Data = pd.pivot_table(data,values = ['訂單號'],index = ['金額區間'],aggfunc = {'訂單號':lambda x: len(x.dropna().unique())}
,fill_value =0).reset_index(drop = False) # fill_value = 0是用來填充缺失值、空值
Data = Data.rename(columns ={'訂單號':'訂單數'}) # 修改列名
print(Data)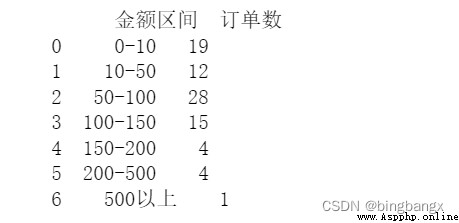
至此,我們已經完成了數據的分箱統計需求~~~~~~