【寫在前邊】
這次的題還是比較難的,只做出來7道,交上去6道,還有一半是暴力做的。只求國三了
開局兩道填空題用了快兩個小時,直接搞崩了心態。。淦!
本題解僅代表個人觀點及思路,不代表標准答案。歡迎各位巨佬指導交流。
所有代碼均存放於倉庫:
Github:https://github.com/AYO-YO/Algorithm/tree/藍橋杯_國賽
Gitee: https://gitee.com/ayo_yo/Algorithm/tree/藍橋杯_國賽
【問題描述】
斐波那契數列的遞推公式為: F n = F n − 1 + F n − 2 F_n = F_{n-1} + F_{n-2} Fn=Fn−1+Fn−2,其中 F 1 = F 2 = 1 F_1 = F_2 = 1 F1=F2=1。
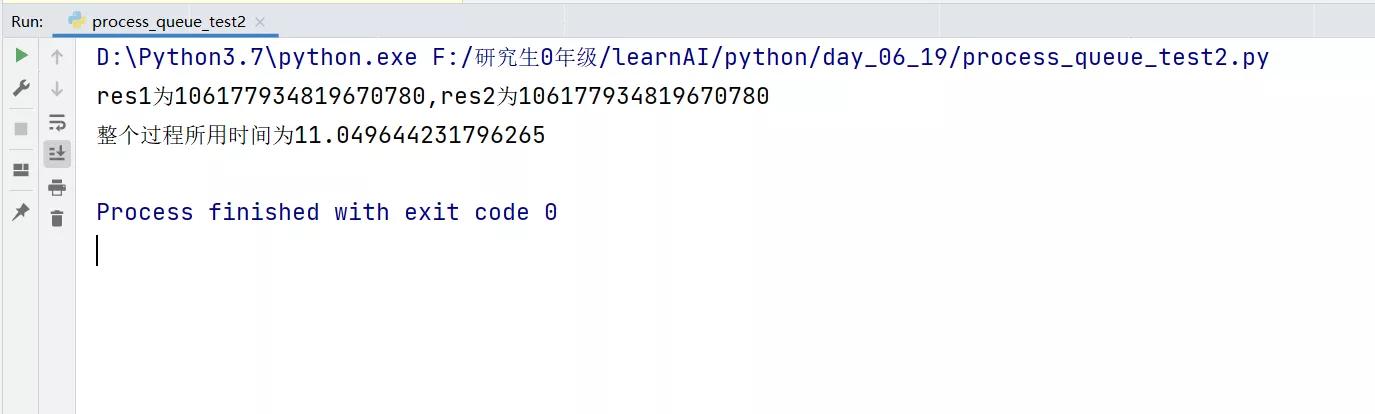
請問,斐波那契數列的第 1 1 1至 202202011200 202202011200 202202011200項(含)中,有多少項的個位是 7 7 7。
【答案提交】
這是一道結果填空的題,你只需要算出結果後提交即可。本題的結果為一個整數,在提交答案時只填寫這個整數,填寫多余的內容將無法得分。
【思路分析】
這道題又是一個超大數,斐波那契本來就是指數級增長,直接爆肯定是不行的。
經過兩位大佬@m0_62944359的勘誤,原方法是錯誤的。
同時由評論區大佬@秋雨洗雞肉提醒,斐波那契數列的個位數60個為1輪,直接1000內的數+100內的數是不對的,會導致部分數錯誤計算。
因此在此寫出大佬@秋雨洗雞肉的正確方法:
斐波那契數列個位數60個為一個循環
60個數中共有8個7。
1 1 2 3 5 8 3 1 4 5 9 4 3 7 0 7 7 4 1 5 6 1 7 8 5 3 8 1 9 0 9 9 8 7 5 2 7 9 6 5 1 6 7 3 0 3 3 6 9 5 4 9 3 2 5 7 2 9 1 0
1 1 2 3 5 8 3 1 4 5 9 4 3 7 0 7 7 4 1 5 6 1 7 8 5 3 8 1 9 0 9 9 8 7 5 2 7 9 6 5 1 6 7 3 0 3 3 6 9 5 4 9 3 2 5 7 2 9 1 0
1 1 2 3 5 8 3 1 4 5 9 4 3 7 0 7 7 4 1 5 6 1 7 8 5 3 8 1 9 0 9 9 8 7 5 2 7 9 6 5 1 6 7 3 0 3 3 6 9 5 4 9 3 2 5 7 2 9 1 0
1 1 2 3 5 8 3 1 4 5 9 4 3 7 0 7 7 4 1 5 6 1 7 8 5 3 8 1 9 0 9 9 8 7 5 2 7 9 6 5 1 6 7 3 0 3 3 6 9 5 4 9 3 2 5 7 2 9 1 0
1 1 2 3 5 8 3 1 4 5 9 4 3 7 0 7 7 4 1 5 6 1 7 8 5 3 8 1 9 0 9 9 8 7 5 2 7 9 6 5 1 6 7 3 0 3 3 6 9 5 4 9 3 2 5 7 2 9 1 0
1 1 2 3 5 8 3 1 4 5 9 4 3 7 0 7 7 4 1 5 6 1 7 8 5 3 8 1 9 0 9 9 8 7 5 2 7 9 6 5 1 6 7 3 0 3 3 6 9 5 4 9 3 2 5 7 2 9 1 0
因此,最終結果應為:
202202011200/60
Out[3]: 3370033520.0
_*8
Out[4]: 26960268160.0
【參考答案】
26960268160
【完整代碼】
A.py (Gitee.com)A.py (github.com)
【問題描述】
小藍很喜歡科研,他最近做了一個實驗得到了一批實驗數據,一共是兩百萬個正整數。如果按照預期,所有的實驗數據 x 都應該滿足 10⁷ ≤ x ≤ 10⁸。但是做實驗都會有一些誤差,會導致出現一些預期外的數據,這種誤差數據 y 的范圍是 10³
≤ y ≤ 10¹² 。由於小藍做實驗很可靠,所以他所有的實驗數據中 99.99% 以上都是符合預期的。小藍的所有實驗數據都在 primes.txt 中,現在他想統計這兩百萬個正整數中有多少個是質數,你能告訴他嗎?
【答案提交】
這是一道結果填空的題,你只需要算出結果後提交即可。本題的結果為一個整數,在提交答案時只填寫這個整數,填寫多余的內容將無法得分。
【思路分析】
這個題有200w個數,直接暴力找肯定不行。我一開始走了彎路子,多線程,素數判斷優化都用上了。最後才發現我想多了,比賽結束前1分鐘才把數爆出來,也沒時間寫針對大數的素性測試了。。思路如下:
首先觀察數據,均以1、3、5、7結尾。大於1000且結尾為5的數,肯定能被5整除,於是先利用編輯器正則替換所有以5結尾的數,此時剩下約150w多個數:
\d+?5
使用埃氏篩選法,獲得10^8以內的所有質數,這裡注意,利用埃氏篩選法需要進行優化,不然也是跑的頭大。我在之前博客裡也寫過直接判斷質數的優化方法,除了2、3,所有質數均位於6n左右。因此可以直接將埃氏篩選法的步長拉到6,這樣速度能進一步提升,然後影響埃氏篩選法速度的大頭主要是2、3、5,需要進行多次循環才能篩掉後邊的合數,因此預處理在生成列表時直接將2、3、5的倍數歸0。理論上直接歸零的質數倍數越多,生成素數就越快。
計數質數 Python 埃氏篩選法_AYO_YO的博客-CSDN博客
判斷質數 Python Java C++_AYO_YO的博客-CSDN博客
def getprimes(n):
ls = [i if i % 2 != 0 and i % 3 != 0 and i % 5 != 0 else 0 for i in range(n + 1)]
ls[1], ls[2], ls[3], ls[5] = 0, 2, 3, 5
for i in range(6, n + 1, 6):
f = i - 1
if f != 0:
for j in range(2 * f, n + 1, f):
ls[j] = 0
continue
f = i + 1
if f != 0:
for j in range(2 * f, n + 1, f):
ls[j] = 0
return filter(lambda x: x != 0, ls)
埃氏篩選法篩選 1 0 8 10^8 108以內的質數大概需要2分鐘左右,再大恐怕就難以承受了。於是先將 1 0 8 10^8 108的質數統計出來,並把大於 1 0 8 10^8 108的質數拎出來。得到結果 1 0 8 10^8 108以內的質數有506733個。大數有約130個。
506733
[542693491967, 142787902577, 452440529173, 663634895869, 71242929179, 999870483413, 441673697183, 895134836909, 59008094959, 812048153483, 153230177243, 5986461211, 825268545161, 85386152959, 305669636917, 176618331487, 627185459239, 517233054923, 347714268719, 75380450897, 652349118967, 746710276723, 887316078643, 55623754253, 726602124691, 63723051253, 11944000489, 14326008041, 995344474081, 127374806651, 101228446879, 782792370337, 7616731547, 672817895497, 309261587441, 993510068537, 898280626321, 691250724803, 436362423451, 135244424501, 873959450791, 404517752423, 803431472291, 890481756773, 299729772337, 993254812121, 939705423281, 928689411767, 950796808643, 925182899009, 867933942403, 177084914339, 374154056921, 195931411013, 636268614181, 845966263637, 669349089677, 279219681547, 116772294307, 458677064359, 414099720659, 553029935971, 225122592047, 523383194647, 291752440213, 29190046721, 756126896941, 400963923179, 807339716593, 666619632839, 792597812483, 157223341237, 515677221383, 869902952023, 277744493561, 279840195947, 12066121523, 659914745389, 796743912131, 973038777059, 856703807231, 66169702601, 987064845247, 916671221021, 884623305749, 504935549881, 232438712231, 701919604183, 542037833447, 521942095081, 726449610001, 840499018589, 492469281101, 757165962919, 437417377471, 903288533789, 254110134101, 265121359891, 776841707227, 854559132599, 325401328397, 675731682791, 730947154187, 280786162939, 670729451441, 48996391291, 286681507897, 847973529401, 166381727761, 568868879153, 56085663143, 417414542761, 666771906149, 857635614683, 188918440631, 490214446741, 82741563491, 411523187461, 304024439243, 912661149107, 556591023551, 934801057481, 828742723319, 814141769183, 528476615281, 560425065263, 224638484077, 610321268093, 655599334577, 624348698849]
這些大數直接判斷是否是質數也是相當恐怖的,於是判斷特大數是否是質數,就要用另一個方法——費馬素性測試。這個是我之前算法課期末作業研究過的一個算法,就是利用隨機數隨機對大數取余,如果能整除,就不是質數;加入了一個優化,加入了一個互質判斷,大大提升了算法效率以及准確率。
for p in bigNum:
K = 100 # 取隨機數驗證的次數,該次數越大,准確率越高。實測K=10就能得到准確結果了
k = 0
while k < K: # 這裡用while是後續判定隨機完成率是否是100%
b = int(random.random() * (p - 1) + 1) # 生成一個1~p-1之間的隨機整數
factor = math.gcd(b, p) # 計算b,p的最大公約數
r = runFermatPower(b, p, p) # 計算b^p mod p
print(f"第{
k + 1}次取隨機數, 隨機數b={
b}, {
b}和{
p}的最大公約數為{
factor}, r=({
b}^{
p})mod p={
r}", end=', ')
if factor > 1:
print(f"因b={
b}與p={
p}的最大公約數為{
factor},不為互質數,故p={
p}為合數")
break
elif r != b:
print(f"因r={
r},({
b}^{
p}) mod p ={
r}!={
b}, 故p={
p}為合數")
break
else:
print(f"故p={
p}可能為素數")
k += 1
if k == K:
print(f"經過{
K}次循環驗證, p={
p}可能為素數, n為素數的概率為{
(1 - 1 / (2 ** k)) * 100}%")
得到最終結果:
506753
【完整代碼】
比賽過程中的代碼是分步驟的,一步步寫,然後得到結果後再計算下一步,這個代碼是優化過的完整版代碼,直接運行就能得到最終結果。
B.py (Gitee.com)B.py (github.com)
【問題描述】
給定 n , m n, m n,m,問是否存在兩個不同的數 x , y x, y x,y使得 1 ≤ x < y ≤ m 1 ≤ x < y ≤ m 1≤x<y≤m且 n n nmod x x x= n n nmod y y y。
【輸入格式】
輸入包含多組獨立的詢問。
第一行包含一個整數 T 表示詢問的組數。
接下來 T T T行每行包含兩個整數 n , m n, m n,m,用一個空格分隔,表示一組詢問。
【輸出格式】
輸出 T T T行,每行依次對應一組詢問的結果。如果存在,輸出單詞 Yes;如果不存在,輸出單詞 No。
【樣例輸入】
3
1 2
5 2
999 99
【樣例輸出】
No
No
Yes
【評測用例規模與約定】
對於 20 % 20\% 20%的評測用例, T ≤ 100 , n , m ≤ 1000 T ≤ 100 ,n, m ≤ 1000 T≤100,n,m≤1000;
對於 50 % 50\% 50%的評測用例, T ≤ 10000 , n , m ≤ 1 0 5 T ≤ 10000 ,n, m ≤ 10^5 T≤10000,n,m≤105;
對於所有評測用例, 1 ≤ T ≤ 1 0 5 , 1 ≤ n ≤ 1 0 9 , 2 ≤ m ≤ 1 0 9 1 ≤ T ≤ 10^5 ,1 ≤ n ≤ 10^9 ,2 ≤ m ≤ 10^9 1≤T≤105,1≤n≤109,2≤m≤109。
【思路分析】
沒啥巧妙的解法,直接暴力做,通關估計夠嗆。
【參考代碼】
C.py (Gitee.com)C.py (github.com)
【問題描述】
小藍最近總喜歡計算自己的代碼中定義的變量占用了多少內存空間。為了簡化問題,變量的類型只有以下三種:
int:整型變量,一個 int 型變量占用 4 Byte 的內存空間。
long:長整型變量,一個 long 型變量占用 8 Byte 的內存空間。
String:字符串變量,占用空間和字符串長度有關,設字符串長度為 L,則字符串占用 L Byte 的內存空間,如果字符串長度為 0 則占用 0 Byte 的內存空間。
定義變量的語句只有兩種形式,第一種形式為:
type var1=value1,var2=value2…;
定義了若干個 type 類型變量 var1、var2、…,並且用 value1、value2…初始化,多個變量之間用, 分隔,語句以; 結尾,type 可能是 int、long 或 String。例如 int a=1,b=5,c=6; 占用空間為 12 Byte;long a=1,b=5;占用空間為 16 Byte;String s1=””,s2=”hello”,s3=”world”;
占用空間為 10 Byte。
第二種形式為:
type[] arr1=new type[size1],arr2=new type[size2]…;
定義了若干 type 類型的一維數組變量 arr1、arr2…,且數組的大小為 size1、size2…,多個變量之間用, 進行分隔,語句以; 結尾,type 只可能是 int 或 long。例如 int[] a1=new int[10]; 占用的內存空間為 40 Byte;long[] a1=new long[10],a2=new long[10]; 占用的內存空間為160 Byte。
已知小藍有 T 條定義變量的語句,請你幫他統計下一共占用了多少內存空間。結果的表示方式為:aGBbMBcKBdB,其中 a、b、c、d 為統計的結果,GB、MB、KB、B 為單位。優先用大的單位來表示,1GB=1024MB, 1MB=1024KB,1KB=1024B,其中 B 表示 Byte。如果 a、b、c、d 中的某幾個數字為0,那麼不必輸出這幾個數字及其單位。題目保證一行中只有一句定義變量的語句,且每條語句都滿足題干中描述的定義格式,所有的變量名都是合法的且均不重復。題目中的數據很規整,和上述給出的例子類似,除了類型後面有一個空格,以及定義數組時 new 後面的一個空格之外,不會出現多余的空格。
【輸入格式】
輸入的第一行包含一個整數 T T T,表示有 T T T句變量定義的語句。接下來 T T T行,每行包含一句變量定義語句。
【輸出格式】
輸出一行包含一個字符串,表示所有語句所占用空間的總大小。
【樣例輸入 1】
1
long[] nums=new long[131072];
【樣例輸出 1】
1MB
【樣例輸入 2】
4
int a=0,b=0; long x=0,y=0;
String s1=”hello”,s2=”world”;
long[] arr1=new long[100000],arr2=new long[100000];
【樣例輸出 2】
1MB538KB546B
【樣例說明】
樣例 1,占用的空間為 131072 × 8 = 1048576 B 131072 × 8 = 1048576 B 131072×8=1048576B,換算過後正好是 1MB,其它三個單位 GB、KB、B 前面的數字都為 0 ,所以不用輸出。
樣例 2,占用的空間為 4 × 2 + 8 × 2 + 10 + 8 × 100000 × 2 B 4 × 2 + 8 × 2 + 10 + 8 × 100000 × 2 B 4×2+8×2+10+8×100000×2B,換算後是1MB538KB546B。
【評測用例規模與約定】
對於所有評測用例, 1 ≤ T ≤ 10 1 ≤ T ≤ 10 1≤T≤10,每條變量定義語句的長度不會超過 1000 1000 1000。所有的變量名稱長度不會超過 10 10 10,且都由小寫字母和數字組成。對於整型變量,初始化的值均是在其表示范圍內的十進制整數,初始化的值不會是變量。對於 String 類型的變量,初始化的內容長度不會超過 50 50 50,且內容僅包含小寫字母和數字,初始化的值不會是變量。對於數組類型變量,數組的長度為一個整數,范圍為: [ 0 , 2 30 ] [0, 2^{30}] [0,230],數組的長度不會是變量。 T T T條語句定義的變量所占的內存空間總大小不會超過 1 GB,且大於 0 B。
【思路分析】
這個題乍一看還挺唬人的,占了足足3頁,因為我前兩道填空題占用了非常多的時間,已經開始慌了,到這題時一看題,心想涼了,這才第二道編程題就這麼難了嗎但仔細讀了一下題目,發現並不難,跟著題目做就行,得益於Python操作字符串非常方便,所以能給這道題省下不少功夫。
思路如下:
首先應該計算當前表達式占用了多少Byte,而且表達式中變量名、=、關鍵字new這些都屬於無關變量,直接忽略即可
獲取輸入的單行表達式後,使用input().split(maxsplit=1)獲取輸入並以第一個空格分隔,主要是用於判斷最左側的數據類型if '[]' in typ
如果類型為數組,注意數組只有int和long:
int[] arr = new int[3];取3)乘以對應變量長度相加即可如果類型為普通類型,則需要額外判斷是不是String:
String:直接正則”.+?”匹配”,注意題目樣例裡這是一個中文字符。匹配到所有值以後直接計算長度相加即可。String:直接.count(',')計算,的長度,變量數量比,數量多1,然後乘以對應長度相加即可。把總長度按要求格式輸出即可:
def convertSize(byte):
size = {
'GB': 0, 'MB': 0, 'KB': 0, 'B': 0}
if byte >= 1073741824:
size['GB'] = byte // 1073741824
byte %= 1073741824
if byte >= 1048576:
size['MB'] = byte // 1048576
byte %= 1048576
if byte >= 1024:
size['KB'] = byte // 1024
byte %= 1024
size['B'] = byte
return size
def printSize(l):
size = convertSize(l)
ans = ''
# 正常情況下直接遍歷字典即可,但我不太確定考試環境的3.8中的字典是否有序。3.9以後肯定是有序的了
if size['GB'] > 0:
ans += f'{
size["GB"]}GB'
if size['MB'] > 0:
ans += f'{
size["MB"]}MB'
if size['KB'] > 0:
ans += f'{
size["KB"]}KB'
if size['B'] > 0:
ans += f'{
size["B"]}B'
print(ans)
【參考代碼】
D.py (Gitee.com)D.py (github.com)
【問題描述】
小藍有一個長度為 n n n的數組 A = ( a 1 , a 2 , ⋅ ⋅ ⋅ , a n ) A = (a_1, a_2, · · · , a_n) A=(a1,a2,⋅⋅⋅,an),數組的子數組被定義為從原數組中選出連續的一個或多個元素組成的數組。數組的最大公約數指的是數組中所有元素的最大公約數。如果最多更改數組中的一個元素之後,數組的最大公約數為 g,那麼稱 g 為這個數組的近似 GCD。一個數組的近似 GCD
可能有多種取值。
具體的,判斷 g 是否為一個子數組的近似 GCD 如下:
小藍想知道,數組 A 有多少個長度大於等於 2 的子數組滿足近似 GCD 的值為 g。
【輸入格式】
輸入的第一行包含兩個整數 n, g,用一個空格分隔,分別表示數組 A 的長度和 g 的值。
第二行包含 n 個整數 a 1 , a 2 , ⋅ ⋅ ⋅ , a n a_1, a_2, · · · , a_n a1,a2,⋅⋅⋅,an,相鄰兩個整數之間用一個空格分隔。
【輸出格式】
輸出一行包含一個整數表示數組 A 有多少個長度大於等於 2 的子數組的近似 GCD 的值為 g 。
【樣例輸入】
5 3
1 3 6 4 10
【樣例輸出】
5
【樣例說明】
滿足條件的子數組有 5 個:
[ 1 , 3 ] [1, 3] [1,3]:將 1 修改為 3 後,這個子數組的最大公約數為 3 ,滿足條件。
[ 1 , 3 , 6 ] [1, 3, 6] [1,3,6]:將 1 修改為 3 後,這個子數組的最大公約數為 3 ,滿足條件。
[ 3 , 6 ] [3, 6] [3,6]:這個子數組的最大公約數就是 3 ,滿足條件。
[ 3 , 6 , 4 ] [3, 6, 4] [3,6,4]:將 4 修改為 3 後,這個子數組的最大公約數為 3 ,滿足條件。
[ 6 , 4 ] [6, 4] [6,4]:將 4 修改為 3 後,這個子數組的最大公約數為 3,滿足條件。
【評測用例規模與約定】
對於 20 % 20\% 20%的評測用例, 2 ≤ n ≤ 1 0 2 2 ≤ n ≤ 10^2 2≤n≤102;
對於 40 % 40\% 40%的評測用例, 2 ≤ n ≤ 1 0 3 2 ≤ n ≤ 10^3 2≤n≤103;
對於所有評測用例, 2 ≤ n ≤ 1 0 5 , 1 ≤ g , a i ≤ 1 0 9 2 ≤ n ≤ 10^5 ,1 ≤ g, a_i ≤ 10^9 2≤n≤105,1≤g,ai≤109。
【思路分析】
這道題雖然說是gcd,但和gcd其實沒有什麼關系。。。
主要是劃分子數組,如果子數組中只有至多 1 個數不是 g 的因子。那麼這個子數組就是滿足條件的,因為可以任意修改,無需關注修改為什麼值。
【參考代碼】
E.py (Gitee.com)E.py (github.com)
【問題描述】
小藍很喜歡 owo ,他現在有一些字符串,他想將這些字符串拼接起來,使得最終得到的字符串中出現盡可能多的 owo 。
在計算數量時,允許字符重疊,即 owowo 計算為 2 個,owowowo 計算為3 個。
請算出最優情況下得到的字符串中有多少個 owo。
【輸入格式】
輸入的第一行包含一個整數 n ,表示小藍擁有的字符串的數量。接下來 n 行,每行包含一個由小寫英文字母組成的字符串 si 。
【輸出格式】
輸出 n 行,每行包含一個整數,表示前 i 個字符串在最優拼接方案中可以得到的 owo 的數量。
【樣例輸入】
3
owo w ow
【樣例輸出】
1
1
2
【評測用例規模與約定】
對於 10 % 10\% 10%的評測用例, n ≤ 10 n ≤ 10 n≤10;
對於 40 % 40\% 40%的評測用例, n ≤ 300 n ≤ 300 n≤300;
對於 60 % 60\% 60%的評測用例, n ≤ 5000 n ≤ 5000 n≤5000;
對於所有評測用例, 1 ≤ n ≤ 1 0 6 , 1 ≤ ∣ s i ∣ , ∣ s i ∣ ≤ 1 0 6 1 ≤ n ≤ 10^6 ,1 ≤ |s_i| , |s_i| ≤ 10^6 1≤n≤106,1≤∣si∣,∣si∣≤106,其中 ∣ s i ∣ |s_i| ∣si∣表示字符串 s i s_i si的長度。
【思路分析】
這個題雖然是25分的題,但用Python來做,不算難,,盲猜應該用動規,但時間不多了,來不及細推,我選擇的是直接暴力做。暴力全排列,時間復雜度極其之高。雖然題目給了10s,,但估計還是過不去。
owo,這個比較取巧的方法就是直接正則'owo'匹配,但是正則一個字符只能匹配一次,但是題目要求中o可以用兩次,那麼直接.replace('o','oo'),把每個oitertools.permutations()生成全排列,再循環尋找最大owo最多的數組。【完整代碼】
I.py (Gitee.com)I.py (github.com)
【問題描述】
給定一個僅含小寫英文字母的字符串 s,每次操作選擇一個區間 [ l i , r i ] [l_i, r_i] [li,ri]將 s的該區間中的所有字母 x i x_i xi全部替換成字母 y i y_i yi,問所有操作做完後,得到的字符串是什麼。
【輸入格式】
輸入的第一行包含一個字符串 s 。第二行包含一個整數 m 。
接下來 m 行,每行包含 4 個參數 l i , r i , x i , y i l_i, r_i, x_i, y_i li,ri,xi,yi,相鄰兩個參數之間用一個空格分隔,其中 l i , r i l_i, r_i li,ri為整數, x i , y i x_i, y_i xi,yi為小寫字母。
【輸出格式】
輸出一行包含一個字符串表示答案。
【樣例輸入】
abcaaea 4
1 7 c e
3 3 e b
3 6 b e
1 4 a c
【樣例輸出】
cbecaea
【評測用例規模與約定】
對於 40 % 40\% 40%的評測用例, ∣ s ∣ , m ≤ 5000 |s|, m ≤ 5000 ∣s∣,m≤5000;
對於所有評測用例, 1 ≤ ∣ s ∣ , m ≤ 1 0 5 , 1 ≤ l i ≤ r i ≤ ∣ s ∣ , x i ≠ y i 1 ≤ |s|, m ≤ 10^5 ,1 ≤ l_i ≤ r_i ≤ |s| ,x_i \not= y_i 1≤∣s∣,m≤105,1≤li≤ri≤∣s∣,xi=yi,其中 |s| 表示字符串 s 的長度。
【思路分析】
這個題甚至比之前的更簡單,覺得需要優化吧,一看時間給了10s。直接跟著題目淦就行了。
【完整代碼】
J.py (Gitee.com)J.py (github.com)
做出來的到這兒就結束了,剩下的三道題沒做出來,懇請賜教哇。
【問題描述】
LQ 市的交通系統可以看成由 n 個結點和 m 條有向邊組成的有向圖。在每條邊上有一個信號燈,會不斷按綠黃紅黃綠黃紅黃… 的順序循環 (初始時剛好變到綠燈)
。當信號燈為綠燈時允許正向通行,紅燈時允許反向通行,黃燈時不允許通行。每條邊上的信號燈的三種顏色的持續時長都互相獨立,其中黃燈的持續時長等同於走完路徑的耗時。當走到一條邊上時,需要觀察邊上的信號燈,如果允許通行則可以通過此邊,在通行過程中不再受信號燈的影響;否則需要等待,直到允許通行。
請問從結點 s 到結點 t 所需的最短時間是多少,如果 s 無法到達 t 則輸出−1。
【輸入格式】
輸入的第一行包含四個整數 n , m , s , t n, m, s, t n,m,s,t,相鄰兩個整數之間用一個空格分隔。接下來 m 行,每行包含五個整數 u i , v i , g i , r i , d i u_i, v_i, g_i, r_i, d_i ui,vi,gi,ri,di
,相鄰兩個整數之間用一個空格分隔,分別表示一條邊的起點,終點,綠燈、紅燈的持續時長和距離(黃燈的持續時長)。
【輸出格式】
輸出一行包含一個整數表示從結點 s 到達 t 所需的最短時間。
【樣例輸入】
4 4 1 4
1 2 1 2 6
4 2 1 1 5
1 3 1 1 1
3 4 1 99 1
【樣例輸出】
11
【評測用例規模與約定】
對於 40% 的評測用例, n ≤ 500 , 1 ≤ g i , r i , d i ≤ 100 n ≤ 500 ,1 ≤ g_i, r_i, d_i ≤ 100 n≤500,1≤gi,ri,di≤100;
對於 70% 的評測用例, n ≤ 5000 n ≤ 5000 n≤5000;
對於所有評測用例, 1 ≤ n ≤ 100000 , 1 ≤ m ≤ 200000 , 1 ≤ s , t ≤ n , 1 ≤ u i , v i ≤ n , 1 ≤ g i , r i , d i ≤ 1 0 9 1 ≤ n ≤ 100000 ,1 ≤ m ≤ 200000 ,1 ≤ s, t ≤ n ,1 ≤ u_i, v_i ≤ n ,1 ≤ g_i, r_i, d_i ≤ 10^9 1≤n≤100000,1≤m≤200000,1≤s,t≤n,1≤ui,vi≤n,1≤gi,ri,di≤109。
【思路分析】
emmm,這個題說實話,題都有點沒讀明白。。
【問題描述】
小藍最近迷上了一款名為《點亮》的謎題游戲,游戲在一個 n × n
的格子棋盤上進行,棋盤由黑色和白色兩種格子組成,玩家在白色格子上放置燈泡,確保任意兩個燈泡不會相互照射,直到整個棋盤上的白色格子都被點亮(每個謎題均為唯一解)。燈泡只會往水平和垂直方向發射光線,照亮整行和整列,除非它的光線被黑色格子擋住。黑色格子上可能有從
0 到 4 的整數數字,表示與其上下左右四個相鄰的白色格子共有幾個燈泡;也可能沒有數字,這表示可以在上下左右四個相鄰的白色格子處任意選擇幾個位置放置燈泡。游戲的目標是選擇合適的位置放置燈泡,使得整個棋盤上的白色格子都被照亮。
例如,有一個黑色格子處數字為 4,這表示它周圍必須有 4 個燈泡,需要在他的上、下、左、右處分別放置一個燈泡;如果一個黑色格子處數字為 2,它的上下左右相鄰格子只有 3
個格子是白色格子,那麼需要從這三個白色格子中選擇兩個來放置燈泡;如果一個黑色格子沒有標記數字,且其上下左右相鄰格子全是白色格子,那麼可以從這 4 個白色格子中任選出 0 至 4 個來放置燈泡。
題目保證給出的數據是合法的,黑色格子周圍一定有位置可以放下對應數量的燈泡。且保證所有謎題的解都是唯一的。
現在,給出一個初始的棋盤局面,請在上面放置好燈泡,使得整個棋盤上的白色格子被點亮。
【輸入格式】
輸入的第一行包含一個整數 n,表示棋盤的大小。
接下來 n 行,每行包含 n 個字符,表示給定的棋盤。字符 . 表示對應的格子為白色,數字字符 0、1、2、3、4 表示一個有數字標識的黑色格子,大寫字母 X 表示沒有數字標識的黑色格子。
【輸出格式】
輸出 n 行,每行包含 n 個字符,表示答案。大寫字母 O 表示對應的格子包含燈泡,其它字符的意義與輸入相同。
【樣例輸入】
5
.....
.2.4.
..4..
.2.X.
.....
【樣例輸出】
...O.
.2O4O
.O4O.
.2OX.
O....
【樣例說明】
答案對應的棋盤布局如下圖所示:

【評測用例規模與約定】
對於所有評測用例, 2 ≤ n ≤ 5 2 \le n \le 5 2≤n≤5,且棋盤上至少有 15 15% 15的格子是黑色格子。
【思路分析】
深搜?動規??不會,,要不是時間太緊,差點寫爆破
【問題描述】
小藍打算采購 n 種物品,每種物品各需要 1 個。
小藍所住的位置附近一共有 m 個店鋪,每個店鋪都出售著各種各樣的物品。
第 i 家店鋪會在第 s i s_i si天至第 t i t_i ti天打折,折扣率為 p i p_i pi,對於原件為 b 的物品,折後價格為 ⌊ b ⋅ p j 100 ⌋ \lfloor \frac{b·p_j}{100} \rfloor ⌊100b⋅pj⌋。其它時間需按原價購買。
小藍很忙,他只能選擇一天的時間去采購這些物品。請問,他最少需要花多少錢才能買到需要的所有物品。
題目保證小藍一定能買到需要的所有物品。
【輸入格式】
輸入的第一行包含兩個整數 n, m,用一個空格分隔,分別表示物品的個數和店鋪的個數。
接下來依次包含每個店鋪的描述。每個店鋪由若干行組成,其中第一行包含四個整數 s i , t i , p i , c i s_i, t_i, p_i, c_i si,ti,pi,ci,相鄰兩個整數之間用一個空格分隔,分別表示商店優惠的起始和結束時間、折扣率以及商店內的商品總數。之後接 c i c_i ci
行,每行包含兩個整數 a j , b j a_j, b_j aj,bj,用一個空格分隔,分別表示該商店的第 j 個商品的類型和價格。商品的類型由 1 至 n 編號。
【輸出格式】
輸出一行包含一個整數表示小藍需要花費的最少的錢數。
【樣例輸入】
2 2
1 2 89 1
1 97
3 4 77 1
2 15
【樣例輸出】
101
【評測用例規模與約定】
對於 40% 的評測用例, n , m ≤ 500 , s i ≤ t i ≤ 100 , c i ≤ 2000 n, m ≤ 500 ,s_i ≤ t_i ≤ 100 , c_i ≤ 2000 n,m≤500,si≤ti≤100,ci≤2000;
對於 70% 的評測用例, n , m ≤ 5000 , c i ≤ 20000 n, m ≤ 5000 , c_i ≤ 20000 n,m≤5000,ci≤20000;
對於所有評測用例, 1 ≤ n , m ≤ 100000 , 1 ≤ c i ≤ n , c i ≤ 400000 , 1 ≤ s i ≤ t i ≤ 1 0 9 , 1 < p i < 100 , 1 ≤ a j ≤ n , 1 ≤ b j ≤ 1 0 9 1 ≤ n, m ≤ 100000 ,1 ≤ ci ≤ n , ci ≤ 400000 ,1 ≤ s_i ≤ t_i ≤ 10^9 ,1 < p_i < 100 ,1 ≤ a_j ≤ n ,1 ≤ b_j ≤ 10^9 1≤n,m≤100000,1≤ci≤n,ci≤400000,1≤si≤ti≤109,1<pi<100,1≤aj≤n,1≤bj≤109。
【思路分析】
又是一道看題目都費勁的題,,不過盲猜應該類似於背包問題。