pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
1、data
data source
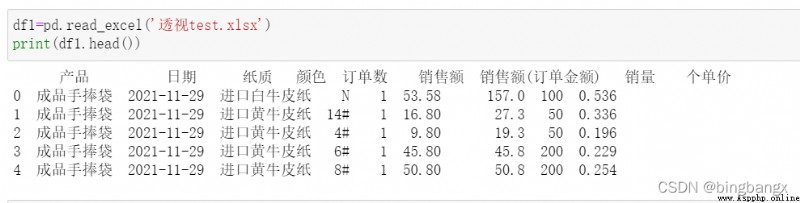
2、index
amount to sql in group by The following columns for grouping , Here is the row index .
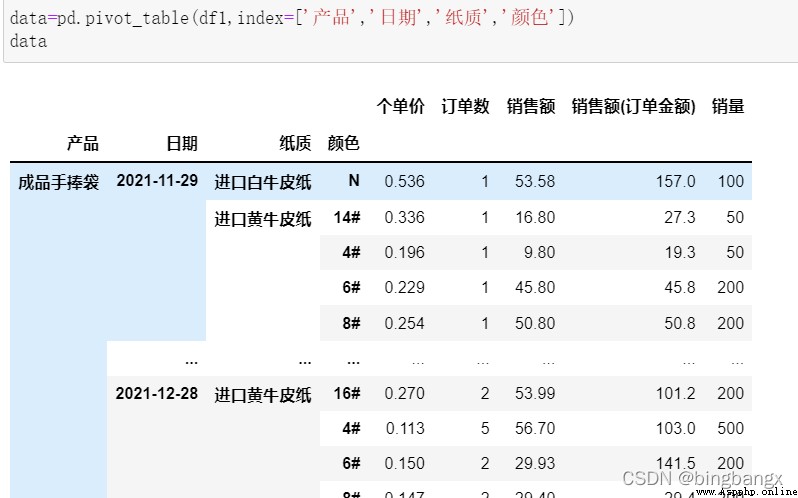
If the assignment is a list , Then aggregate from left to right , The same values in the first column are automatically merged
3、values
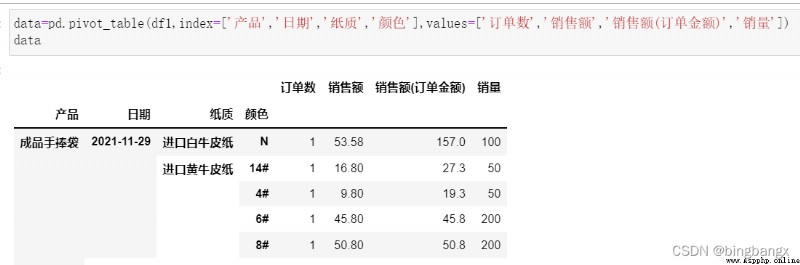
It is equivalent to the column of aggregate function operation . The above description is correct Price polymerization , If no other parameters are specified , The default aggregation is averaging .
4、aggfunc
about aggfunc, The operation is values Value after , instead of columns Value after .
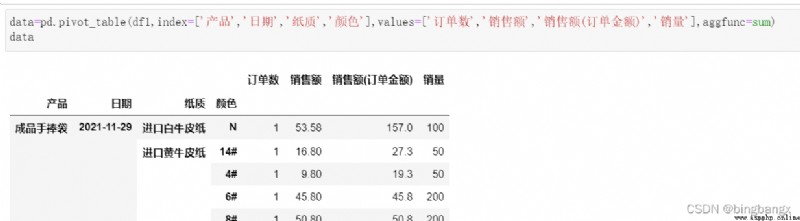
5、columns
Equivalent to column index , Is to show some content in more detail .
6、fill_value
To fill in NAN Of .
7、margins
by True Add row when / Total of columns .
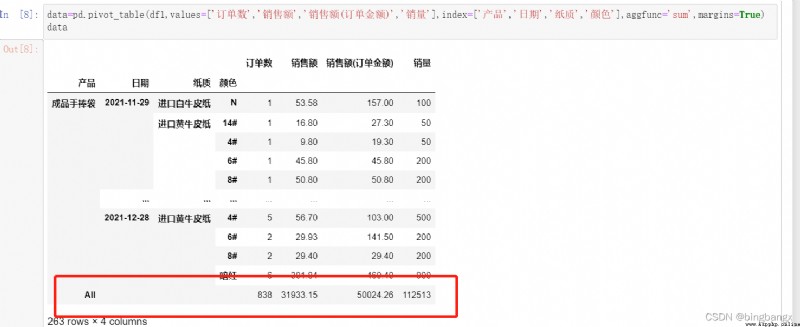
Last , Use reset.index(), Reset index . Convert row index to column .
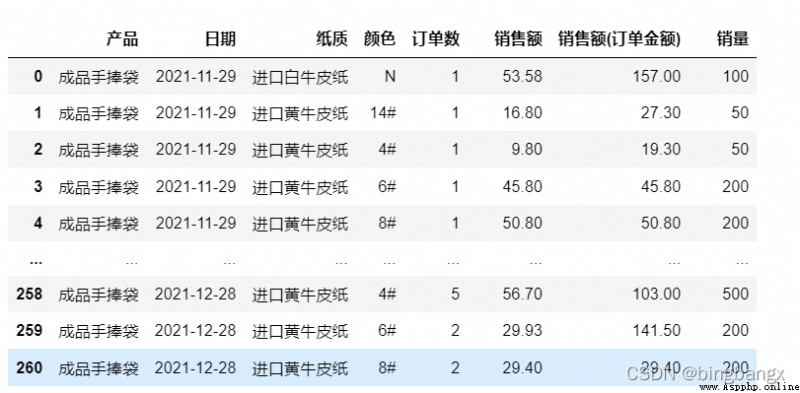
data=pd.pivot_table(df1,values=[' Number of orders ',' sales ',' sales ( Order amount )',' sales '],index=[' product ',' date ',' Paper quality ',' Color '],aggfunc='sum',margins=True).reset_index()
data