pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
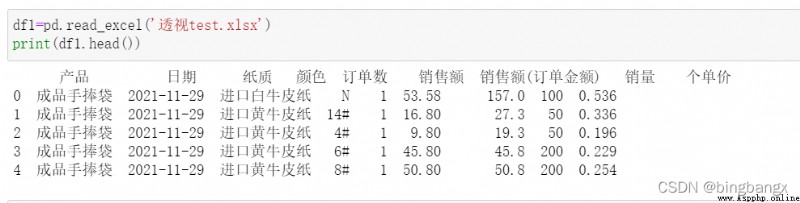
1、data
數據源
2、index
相當於sql 中group by後面的用於分組的列,在這裡是行索引.
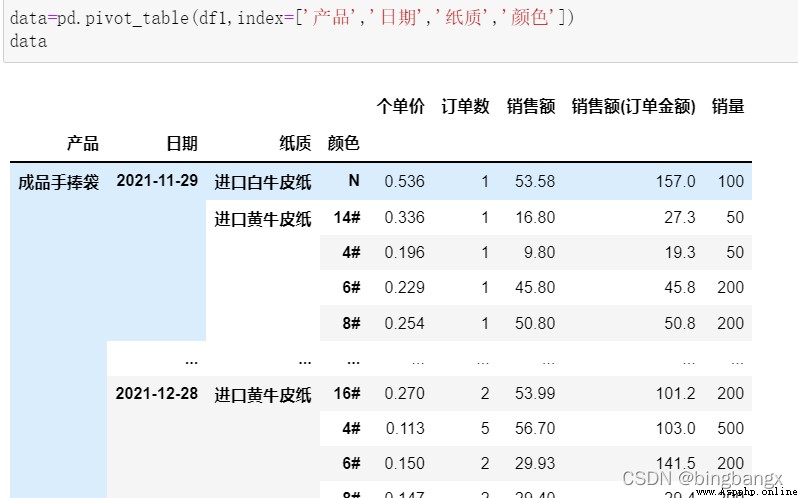
如果賦值的是列表,那麼從左到右依次聚合,會自動合並第一列相同的值
3、values
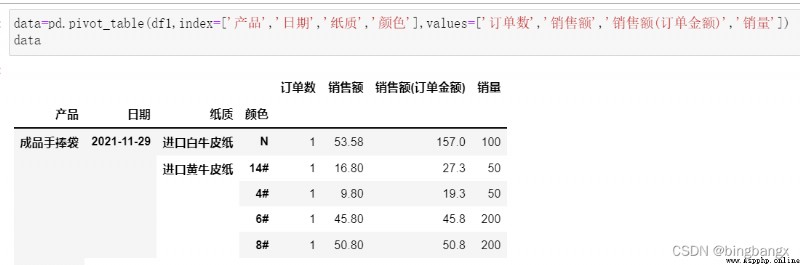
相當於聚合函數操作的列。上面說明是對Price聚合,如果不指定其他參數 ,默認聚合是求平均。
4、aggfunc
對於aggfunc,操作的是values後面的值,而不是columns後面的值.
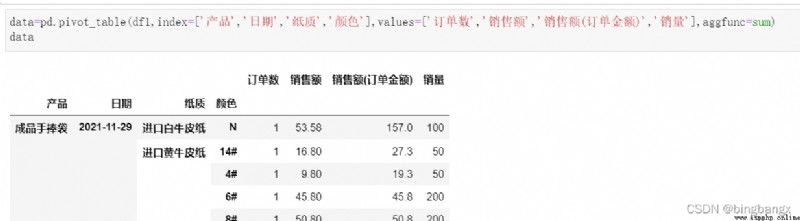
5、columns
相當於列索引,就是更細化地展示一些內容.
6、fill_value
用來填充NAN的.
7、margins
為True時會添加行/列的總計.
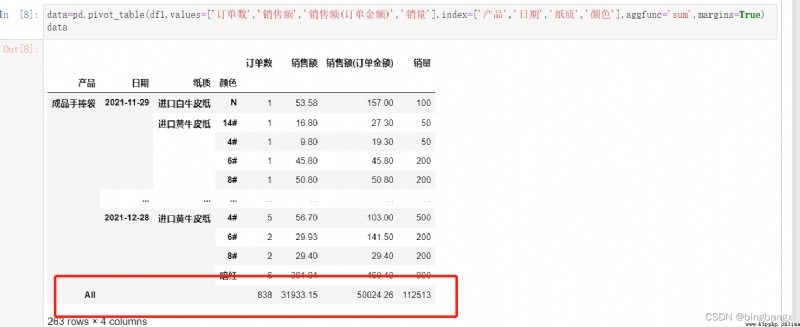
最最最最後,使用reset.index(),重置索引。將行索引轉為列。
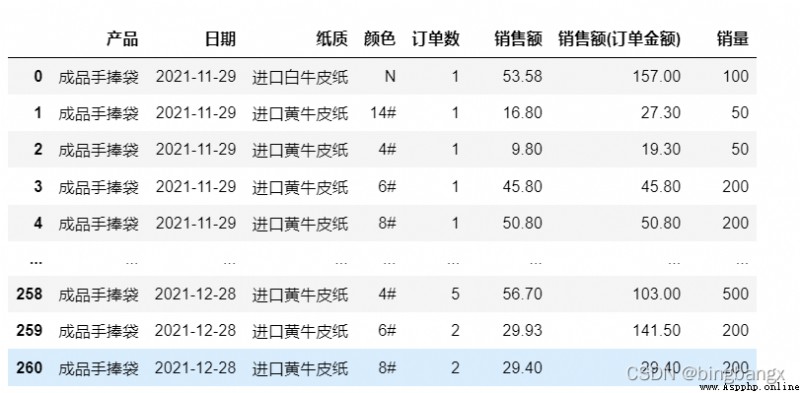
data=pd.pivot_table(df1,values=['訂單數','銷售額','銷售額(訂單金額)','銷量'],index=['產品','日期','紙質','顏色'],aggfunc='sum',margins=True).reset_index()
data