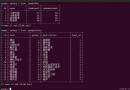
【導語】:Memray是一個可以檢查Python代碼內存分配情況的工具,我們可以使用它對Python解釋器或擴展模塊中的代碼進行分析,並生成多種統計報告,從而更直觀的看到代碼的內存分配。
開發者可以根據需要,生成多種統計報告,觀察程序的內存分配。
總結報告
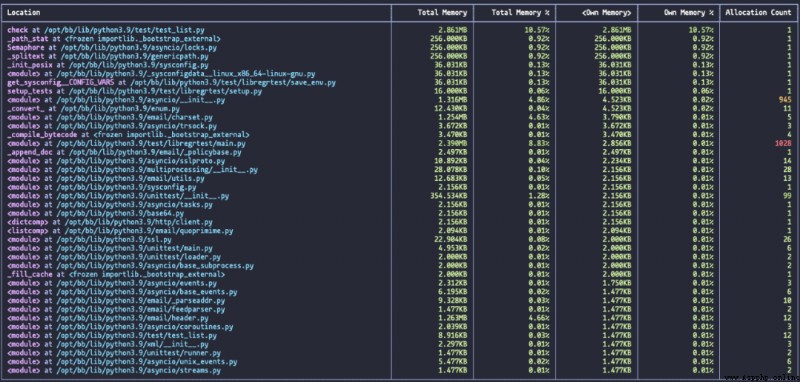
該報告會把多個線程的內存分配情況顯示到同一個表格中,own memory表示每個函數占用的內存,total memory表示函數本身及其調用其他函數所占用的內存總量,allocation count表示暫時未釋放的內存個數。
火焰圖報告
該報告可以將內存分配數據可視化展示。火焰圖的第一層是占用內存的函數, 寬度越大,則占用的內存越多;每一層的函數都被其下一層的函數所調用,依次類推。
示例代碼:
def a(n):
return b(n)
def b(n):
return [c(n), d(n)]
def c(n):
return "a" * n
def d(n):
return "a" * n
a(100000)生成的火焰圖

由該圖可以看出,函數a調用了函數b,函數b調用了函數c和函數d。且第一層函數c 和函數d所占的寬度相同,表示c和d占用的內存一樣。
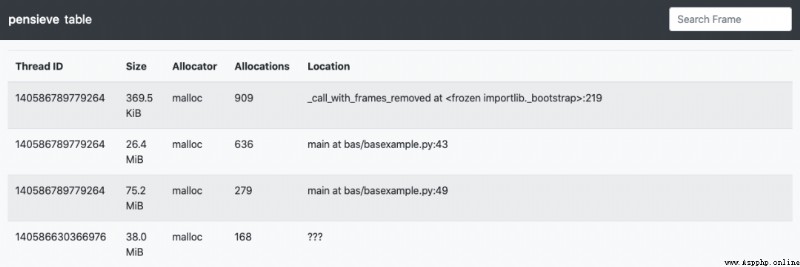
表格報告
該報告以表格的形式展示程序的內存使用情況。Thread ID表示對應的線程,Size表示占用的內存總數,Allocator表示占用內存的函數,Location表示函數所在的位置。同時,還可以對每一列的數據進行排序。
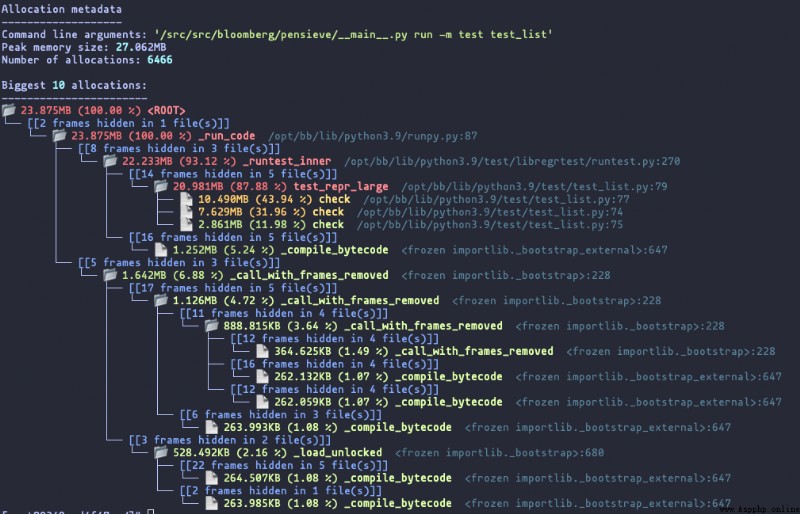
樹形報告
該報告可以清晰的顯示出程序的調用層次。樹形報告中根節點中的內存總量和所占百分比 只是針對於圖中展示的數據,占用內存小的不在圖中。
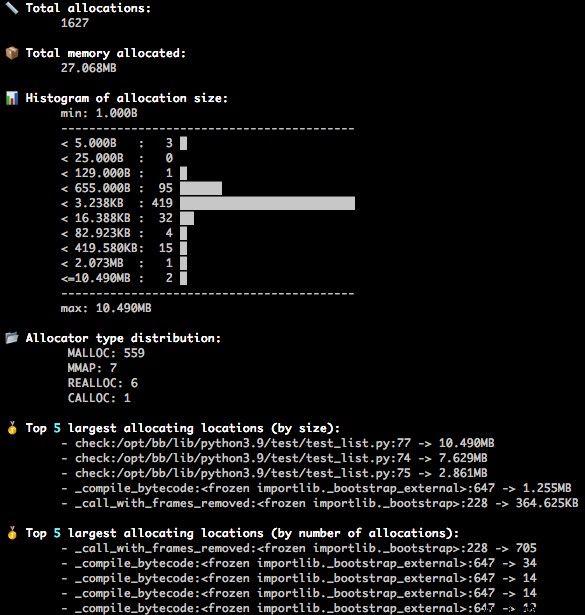
統計報告
該報告可以顯示程序內存使用情況的詳細信息,包括分配的內存總量、分配類型(例如MALLOC, CALLOC)等。
https://github.com/bloomberg/memray目前只能在Linux平台上使用Memray。由於Memray使用了C語言,發布的版本 是二進制的,所以得先在系統上安裝二進制編譯工具。隨後在Python3.7+的環境 下安裝Memray:
python3 -m pip install memray如果你想安裝開發版本的Memray,首先要在系統上安裝二進制工具:libunwind 和liblz4,隨後克隆項目並運行如下命令進行安裝:
git clone [email protected]:bloomberg/memray.git memray
cd memray
python3 -m venv ../memray-env/ # just an example, put this wherever you want
source ../memray-env/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install -e . -r requirements-test.txt -r requirements-extra.txt基本使用
我們可以通過以下命令來追蹤python代碼的內存分配情況,my_script.py就是要分析的文件:
python3 -m memray run my_script.py也可以把memray當作命令行工具使用,例如:
memray run my_script.py
memray run -m my_module以上命令會輸出一個二進制文件,隨後我們可以根據需要生成統計報告。假如我們想生成一個總結報告,那麼可以運行如下命令:
memray summary my_script.bin會生成程序內存分配的總結報告:
不同的報告形式在簡介部分都有展示,請讀者自行查看。
分析C/C++代碼的內存分配
當要使用Memray分析numpy或者pandas這種包含C代碼的模塊時,我們可以運行如下命令:
memray run --native my_script.py從而直觀的看到Python代碼分配了多少內存,擴展模塊分配了多少內存。
假如我們在一個文件中使用了Numpy,當我們不使用--native時,生成的統計報告如下圖:
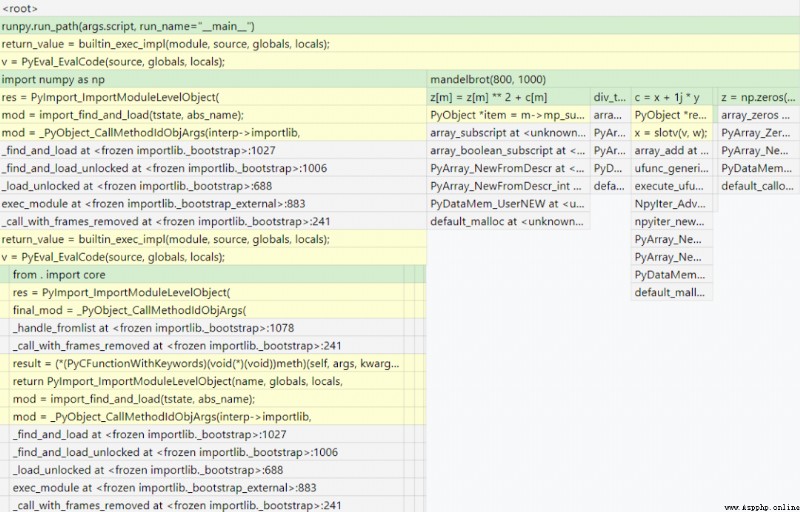
從圖中可以看出在計算Numpy數組時分配了內存,但不清楚是Numpy還是Python解釋器分配了內存。通過使用--native命令,就可以得到一個 更全面的報告,如圖所示:
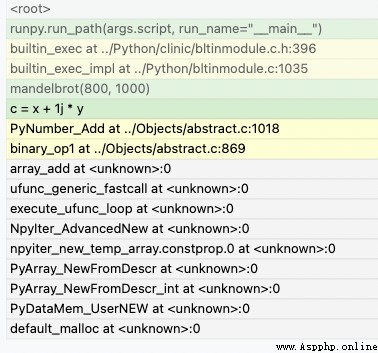
從圖中可以看到Numpy中C模塊的調用情況,當添加Numpy數組後,產生了內存分配。我們可以通過文件的後綴名區分Python模塊和C模塊。
在代碼運行時查看內存分配變化
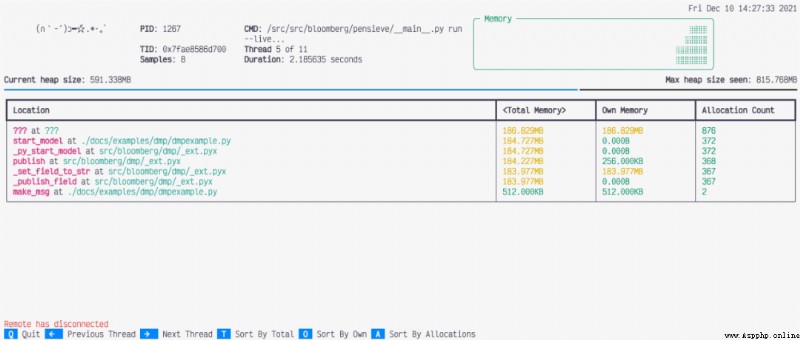
Memray還支持動態查看Python代碼的內存分配情況,我們只需使用以下命令:
memray run --live my_script.py在這種模式下,開發者可以調試運行時間較長的代碼。下圖即為文件運行時的內存分配情況:

結果排序
統計報告中的結果通常是根據分配的總內存,從大到小依次排列。我們可以改變排序條件:
t (默認): 根據總內存排列
o: 根據每個函數占用的內存排列
a: 根據未釋放的內存個數進行排列
查看其他線程
使用live命令默認展示的是主線程的內存分配情況,我們可以通過左右箭頭切換到其他線程。
API
除了使用memray run查看Python代碼的內存分配,還可以在Python程序中使用memray。
import memray
with memray.Tracker("output_file.bin"):
print("Allocations will be tracked until the with block ends")更多細節可以查看相關API文檔[1]。
在我們平時編寫 Python 代碼的過程中,有時候只考慮到了業務功能的實現,而忽視了代碼的合理性與規范性,例如內存分配就是一個很重要的點,合理的內存分配有助於 提升項目的運行速度。
Memray 就是一個支持查看Python代碼內存分配的工具,它的便捷之處在於:我們可以根據需要,生成多種分析報告,從而直觀的了解到自己代碼的內存分配情況,避免發生內存洩露現象。
你寫 Python 代碼時關注過內存使用情況嗎?
參考資料:
[1]
API文檔: https://bloomberg.github.io/memray/api.html

Python貓技術交流群開放啦!群裡既有國內一二線大廠在職員工,也有國內外高校在讀學生,既有十多年碼齡的編程老鳥,也有中小學剛剛入門的新人,學習氛圍良好!想入群的同學,請在公號內回復『交流群』,獲取貓哥的微信(謝絕廣告黨,非誠勿擾!)~
還不過瘾?試試它們
▲如何用 Docker 構建企業級 PyPi 服務?
▲Python 函數為什麼會默認返回 None?
▲在 Google 工作十年後的感悟
▲Python 程序調試分析大殺器合集
▲Python 工匠:寫好面向對象代碼的原則(中)
▲Python在計算內存時應該注意的問題?
如果你覺得本文有幫助
請慷慨分享和點贊,感謝啦!