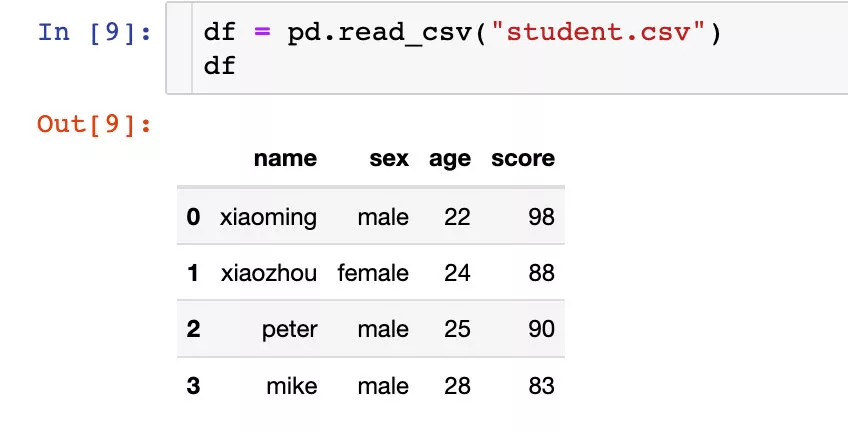
Compiling regular expression patterns , Returns the pattern of an object ( You can compile those commonly used regular expressions into regular expression objects , It's a little bit more efficient ).
Format :
re.compile(pattern,flags=0)
for example :
import re
text = "The moment you think about giving up,think of the reason why you held on so long."
text1 = "Life is a journey,not the destination,but the scenery along the should be and the mood at the view."
rr = re.compile(r'\w*o\w*')
print(rr.findall(text)) # lookup text All contained in 'o' 's words
print(rr.findall(text1)) # lookup text1 All contained in 'o' 's words
The operation results are as follows :
['moment', 'you', 'about', 'of', 'reason', 'you', 'on', 'so', 'long']
['journey', 'not', 'destination', 'along', 'should', 'mood']
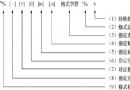
frequently-used flags Yes :
Match at the beginning of the string , Matches the destination character at the beginning and returns , If there is no destination character at the beginning, the matching will fail , return None.
Format :
re.match(pattern, string, flags=0)
for example :
print(re.match('edu','educoder.net').group())
print(re.match('edu','www.educoder.net').group())
The operation results are as follows :
notes :match() The function returns a match object object , and match object The object has the following methods :
re.search() Function to find a pattern match in a string , Just find the first match and go back . If the string doesn't match , Then return to None.
Format :
re.search(pattern, string, flags=0)
print(re.search('edu','www.educoderedu.net').group())
print(re.search('eduaaa','www.educoderedu.net').group())
The operation results are as follows :