編譯正則表達式模式,返回一個對象的模式(可以把那些常用的正則表達式編譯成正則表達式對象,這樣可以提高一點效率)。
格式:
re.compile(pattern,flags=0)
例如:
import re
text = "The moment you think about giving up,think of the reason why you held on so long."
text1 = "Life is a journey,not the destination,but the scenery along the should be and the mood at the view."
rr = re.compile(r'\w*o\w*')
print(rr.findall(text)) #查找text中所有包含'o'的單詞
print(rr.findall(text1)) #查找text1中所有包含'o'的單詞
運行結果如下:
['moment', 'you', 'about', 'of', 'reason', 'you', 'on', 'so', 'long']
['journey', 'not', 'destination', 'along', 'should', 'mood']
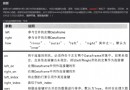
常用的flags有:
在字符串剛開始的位置匹配,在開頭匹配到目的字符便返回,如果開頭沒有目的字符將匹配失敗,返回None。
格式:
re.match(pattern, string, flags=0)
例如:
print(re.match('edu','educoder.net').group())
print(re.match('edu','www.educoder.net').group())
運行結果如下:
注:match()函數返回的是一個match object對象,而match object對象有以下方法:
re.search()函數會在字符串內查找模式匹配,只要找到第一個匹配然後返回。如果字符串沒有匹配,則返回None。
格式:
re.search(pattern, string, flags=0)
print(re.search('edu','www.educoderedu.net').group())
print(re.search('eduaaa','www.educoderedu.net').group())
運行結果如下: