列表內置方法
字典內置方法
元組內置方法
集合內置方法
可變類型與不可變類型
列表在調用內置方法之後不會產生新的值
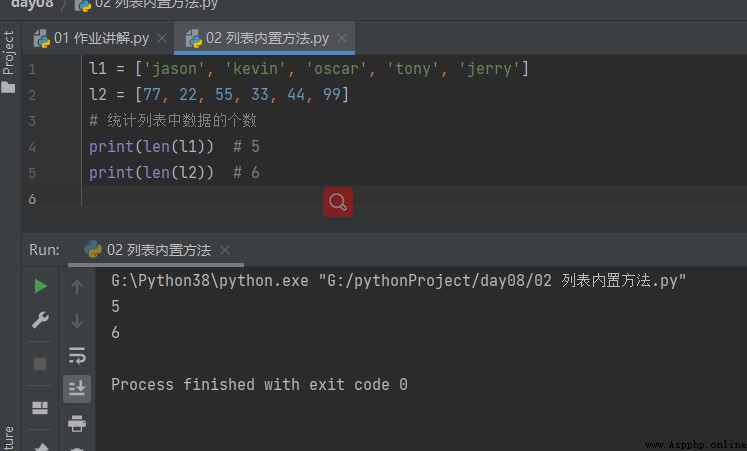
1.1 統計列表中的數據值的個數
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry'] l2 = [77, 22, 55, 33, 44, 99] # 統計列表中數據的個數 print(len(l1)) # 5 print(len(l2)) # 6
2.增
2.1 尾部追加數據值append() 括號內無論寫什麼數據類型 都是當成一個數據值增加
# 2.1尾部追加數據值append() 括號內無論寫什麼數據類型 都是當成一個數據值追加
res = l1.append('owen')
print(res) # None 空
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', 'owen']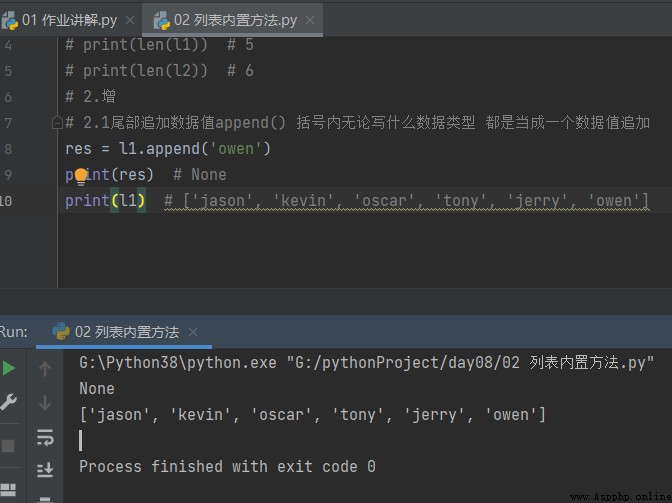
s1 = '$hello$'
res1 = s1.split('$')
print(res1) # ['', 'hello', '']
print(s1) # $hello$
l1.append([1, 2, 3, 4, 5])
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', [1, 2, 3, 4, 5]]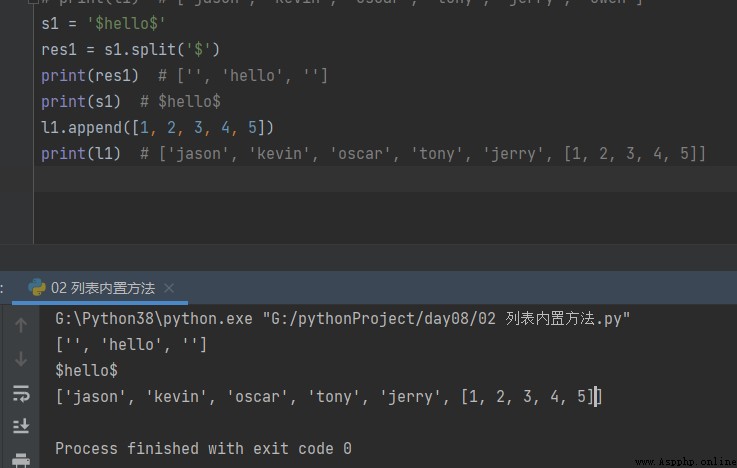
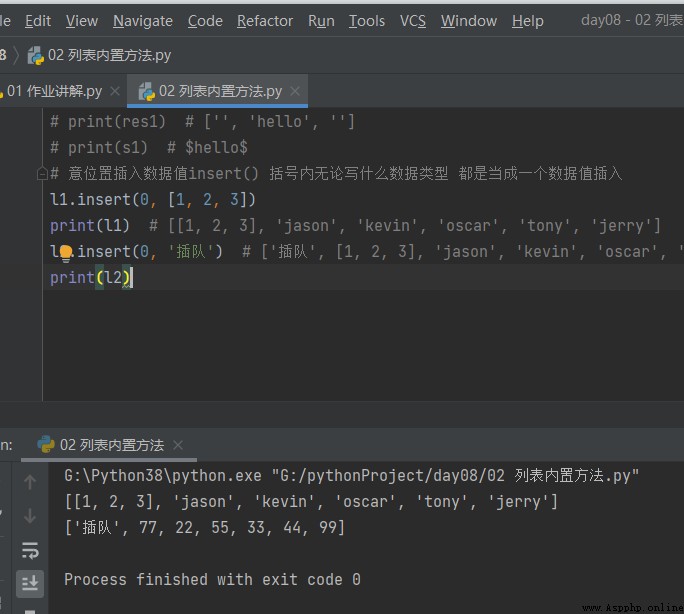
2.2 任意位置插入數據值insert 括號內i而什麼數據類型 都是當成一數據子方恆
# 意位置插入數據值insert() 括號內無論寫什麼數據類型 都是當成一個數據值插入 l1.insert(0, [1, 2, 3]) print(l1) # [[1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry'] l2.insert(0, '插隊') # ['插隊', [1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry'] print(l2)
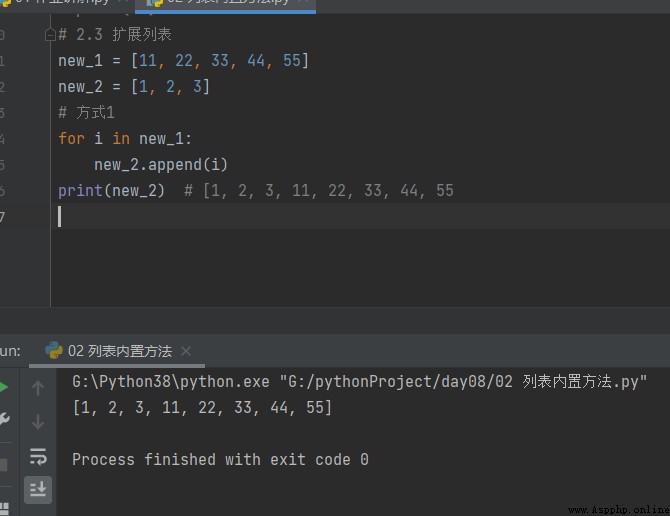
2.3 擴展列表
方式1
# 2.3 擴展列表 new_1 = [11, 22, 33, 44, 55] new_2 = [1, 2, 3] # 方式1 for i in new_1: new_2.append(i) print(new_2) # [1, 2, 3, 11, 22, 33, 44, 55
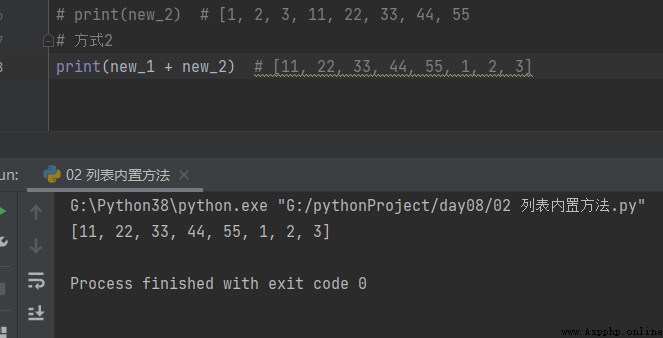
方式2
# 方式2 print(new_1 + new_2) # [11, 22, 33, 44, 55, 1, 2, 3]
方式3(推薦使用) extend
# 方式3(推薦使用) new_1.extend(new_2) # 括號裡面必須是支持for循環的數據類型 for循環+append() print(new_1) # [11, 22, 33, 44, 55, 1, 2, 3]
3.查詢數據與修改數據
# 3.查詢數據與修改數據 print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry'] print(l1[0]) # jason print(l1[1:4]) # ['kevin', 'oscar', 'tony'] l1[0] = 'jasonNM' print(l1) # ['jasonNM', 'kevin', 'oscar', 'tony', 'jerry']
4.刪除數據
4.1通用數據策略
# 4.1通用數據策略 del l1[0] # 通過索引即可 print(l1) # ['kevin', 'oscar', 'tony', 'jerry']
4.2指名道姓的刪除 remove
# 4.2 指名道姓刪除
res = l1.remove('jason') # 括號內必須填寫明確的數據值
print(l1, res) # ['kevin', 'oscar', 'tony', 'jerry'] None
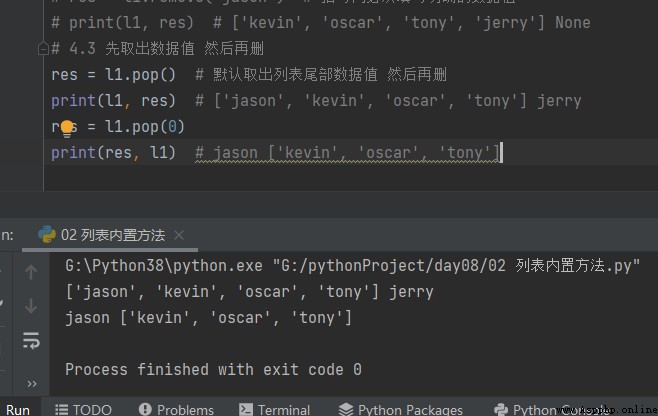
4.3 先取出數值 在刪除 pop
# 4.3 先取出數據值 然後再刪 res = l1.pop() # 默認取出列表尾部數據值 然後再刪 print(l1, res) # ['jason', 'kevin', 'oscar', 'tony'] jerry res = l1.pop(0) print(res, l1) # jason ['kevin', 'oscar', 'tony']
5.查看索引值 index
# 5.查看數據值對於的索引值
print(l1.index('jason'))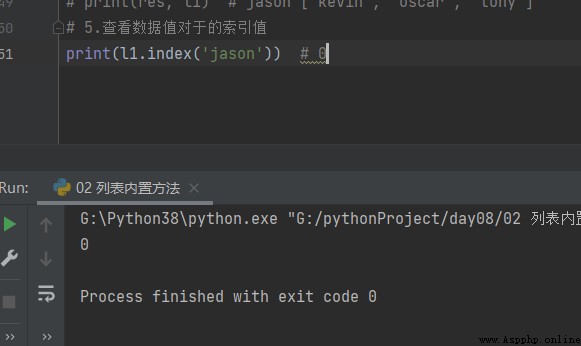
6.統計某個數據值出現的數據 append
# 6.統計某個數據值出現的次數
l1.append('jason')
print(l1.count('jason')) # 2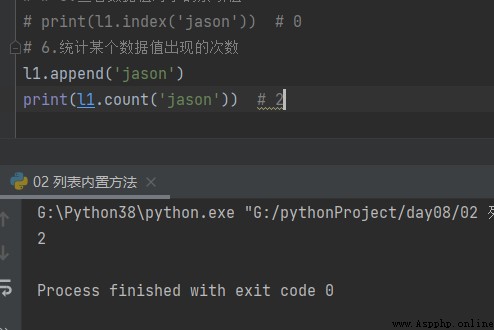
7.排序 sort 升序 sort(reverse=True) 降序 b.sort(key=a.index) 去重b按a的列表排序
l2.sort() # 升序 [22, 33, 44, 55, 77, 99] print(l2)
l2.sort(reverse=True) # 降序 print(l2) # [99, 77, 55, 44, 33, 22]
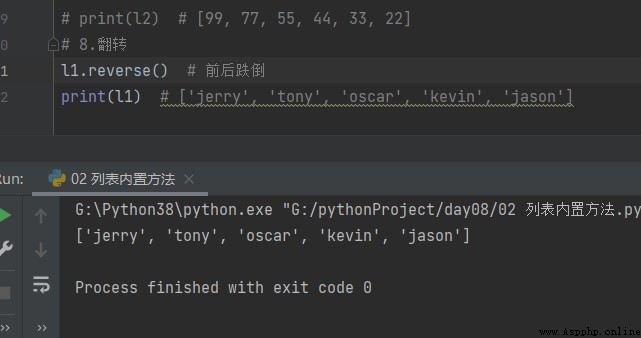
8.翻轉 reverse
l1.reverse() # 前後跌倒 print(l1) # ['jerry', 'tony', 'oscar', 'kevin', 'jason']
9.比較運算
new_1 = [99, 22] new_2 = [11, 22, 33, 44] print(new_1 > new_2) # True 是按照位置順序一一比較
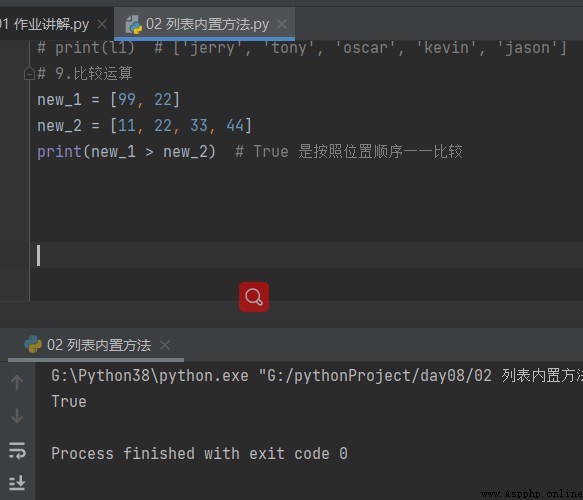
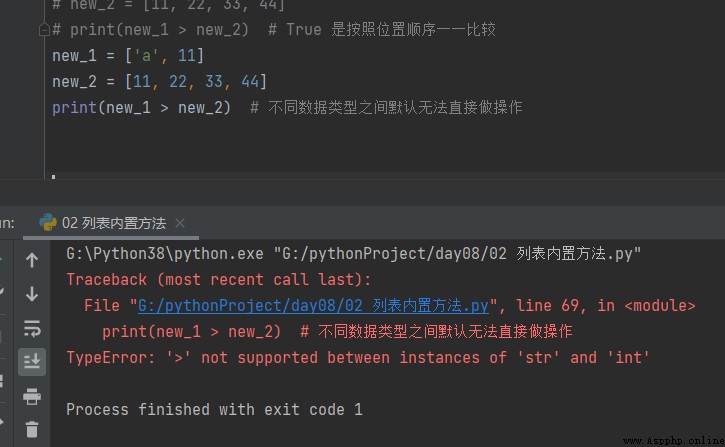
new_1 = ['a', 11] new_2 = [11, 22, 33, 44] print(new_1 > new_2) # 不同數據類型之間默認無法直接做操作
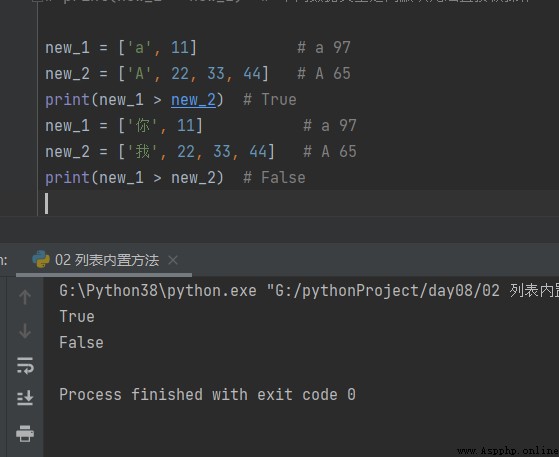
new_1 = ['a', 11] # a 97 new_2 = ['A', 22, 33, 44] # A 65 print(new_1 > new_2) # True new_1 = ['你', 11] # a 97 new_2 = ['我', 22, 33, 44] # A 65 print(new_1 > new_2) # False
字典很少涉及到類型轉換 都是直接定義使用
# 類型轉換(了解即可) 字典很少涉及到類型轉換 都是直接定義使用
print(dict([('name', 'jason'), ('pwd', 123)])) # {'name': 'jason', 'pwd': 123}
print(dict(name='jason', pwd=123)) # {'name': 'jason', 'pwd': 123}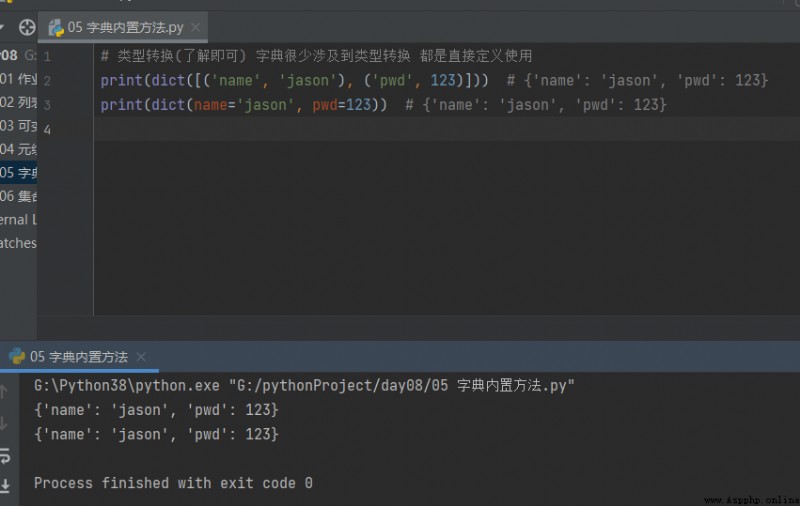
1.字典內k:v鍵值對是無序的
2.取值
# 2.取值操作
print(info['username']) # 不推薦使用 鍵不存在會直接報錯
print(info['xxx']) # 不推薦使用 鍵不存在會直接報錯
print(info.get('username')) # jason
print(info.get('xxx')) # None
print(info.get('username', '鍵不存在返回的值 默認返回None')) # jason
print(info.get('xxx', '鍵不存在返回的值 默認返回None')) # 鍵不存在返回的值 默認返回None
print(info.get('xxx', 123)) # 123
print(info.get('xxx')) # None3.統計字典中鍵值對的個數 len
print(len(info)) # 3
4.修改數據 info
info['username'] = 'jasonNB' # 鍵存在則是修改
print(info) # {'username': 'jasonNB', 'pwd': 123, 'hobby': ['read', 'run']}
5.新增數據 info
# 5.新增數據
info['salary'] = 6 # 鍵不存在則是新增
print(info) # {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}
6.刪除數據
方式1
# 方式1
del info['username']
print(info) # {'pwd': 123, 'hobby': ['read', 'run']}
方式2
res = info.pop('username')
print(info, res) # {'pwd': 123, 'hobby': ['read', 'run']} jason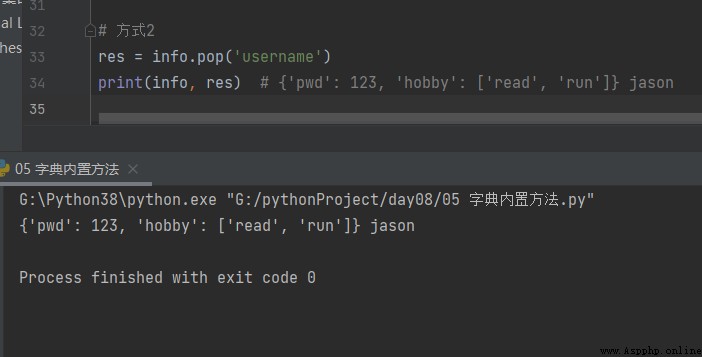
方式3
# 方式3
info.popitem() # 隨機刪除
print(info) # {'username': 'jason', 'pwd': 123}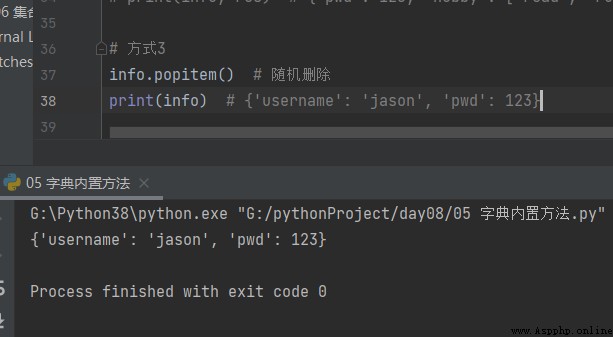
7.快速獲取鍵 值 鍵值對數據
print(info.keys()) # 獲取字典所有的k值 結果當成是列表即可dict_keys(['username', 'pwd', 'hobby'])
print(info.values()) # 獲取字典所有的v值 結果當成是列表即可dict_values(['jason', 123, ['read', 'run']])
print(info.items()) # 獲取字典kv鍵值對數據 組織成列表套元組dict_items([('username', 'jason'), ('pwd', 123), ('hobby', ['read', 'run'])])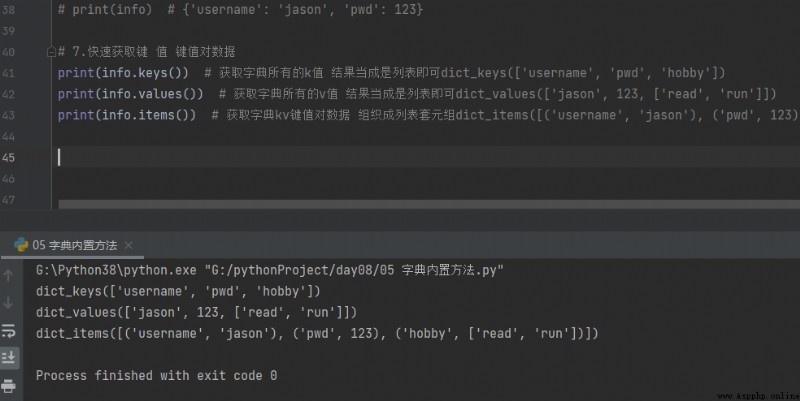
8.修改字典數據 鍵存在則是修改 鍵不存在則是新增
# 8.修改字典數據 鍵存在則是修改 鍵不存在則是新增
info.update({'username':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run']}
info.update({'xxx':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run'], 'xxx': 'jason123'}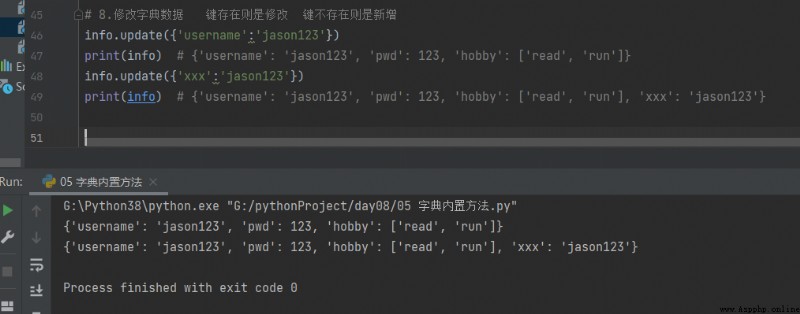
9.快速構造字典 給的值默認情況下所有的鍵都用一個
# 9.快速構造字典 給的值默認情況下所有的鍵都用一個
res = dict.fromkeys([1, 2, 3], None)
print(res) # {1: None, 2: None, 3: None}
new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}
new_dict['name'] = []
new_dict['name'].append(123)
new_dict['pwd'].append(123)
new_dict['hobby'].append('read')
print(new_dict) # {'name': [123], 'pwd': [123, 'read'], 'hobby': [123, 'read']}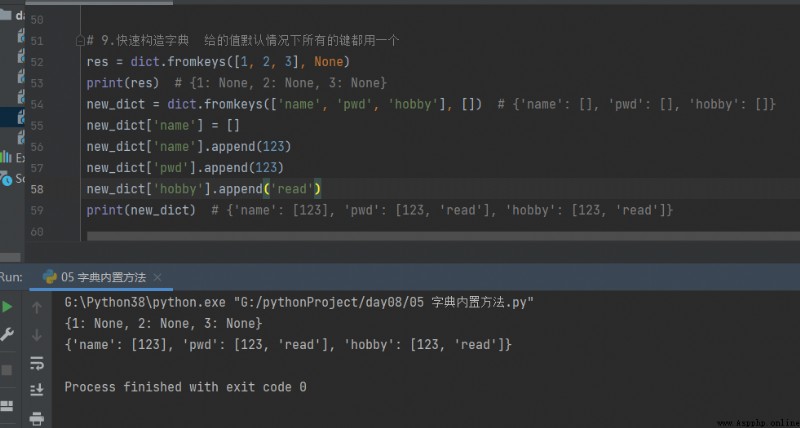
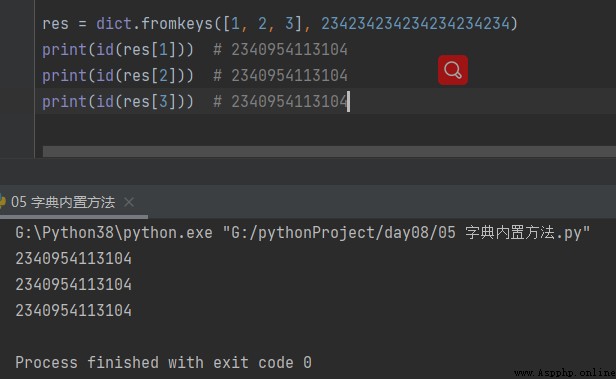
res = dict.fromkeys([1, 2, 3], 234234234234234234234) print(id(res[1])) # 2340954113104 print(id(res[2])) # 2340954113104 print(id(res[3])) # 2340954113104
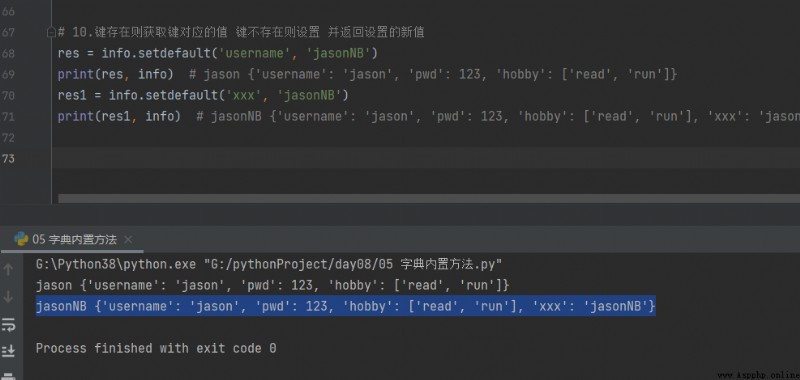
10.鍵存在則獲取鍵對應的值 鍵不存在則設置 並返回設置的新值
# 關鍵字 tuple
# 類型轉換 支持for循環的數據類型都可以轉元組
print(tuple(123)) # 不可以
print(tuple(123.11)) # 不可以
print(tuple('zhang')) # 可以t1 = () # tuple
print(type(t1))
t2 = (1) # int
print(type(t2))
t3 = (11.11) # float
print(type(t3))
t4 = ('jason') # str
print(type(t4))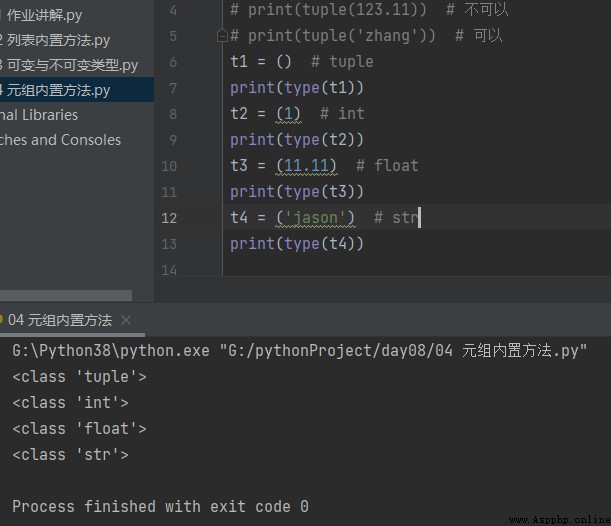
當元組內只有一個數據值的時候 逗號不能省略,如果省略了 那麼括號裡面是什麼數據類型就是什麼數據類型
建議:編寫元組 逗號加上 哪怕只有一個數據(111, ) ('jason', )ps:以後遇到可以存儲多個數據值的數據類型 如果裡面只有一個數據 逗號也趁機加上
t2 = (1,) # tuple
print(type(t2))
t3 = (11.11,) # tuple
print(type(t3))
t4 = ('jason',) # tuple
print(type(t4))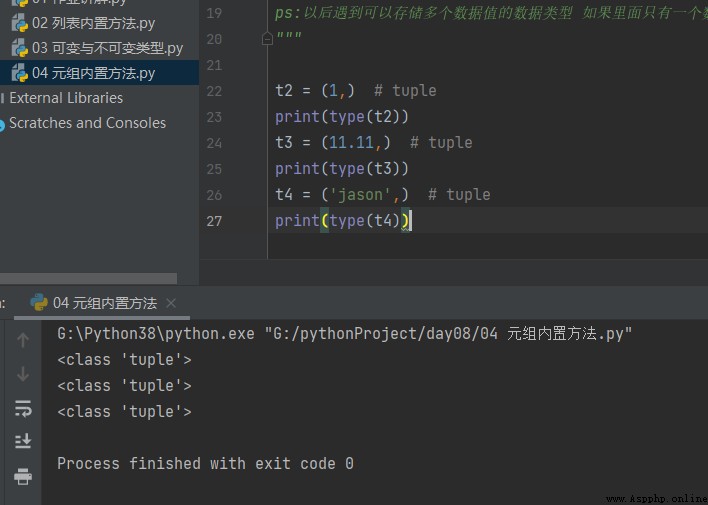
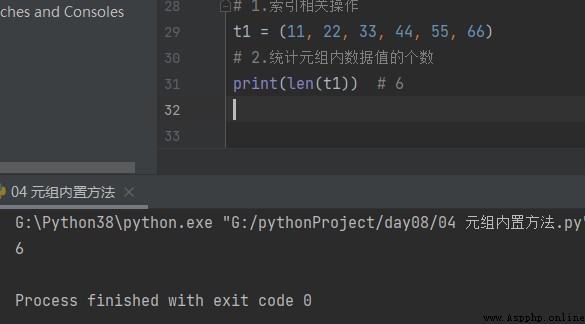
1.統計元組內個數
t1 = (11, 22, 33, 44, 55, 66) # 1.統計元組內數據值的個數 print(len(t1)) # 6
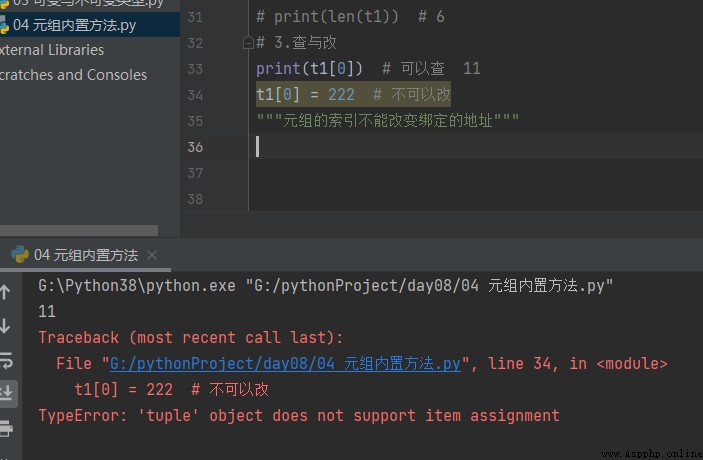
2.查與改
# 2.查與改 print(t1[0]) # 可以查 11 t1[0] = 222 # 不可以改 """元組的索引不能改變綁定的地址"""
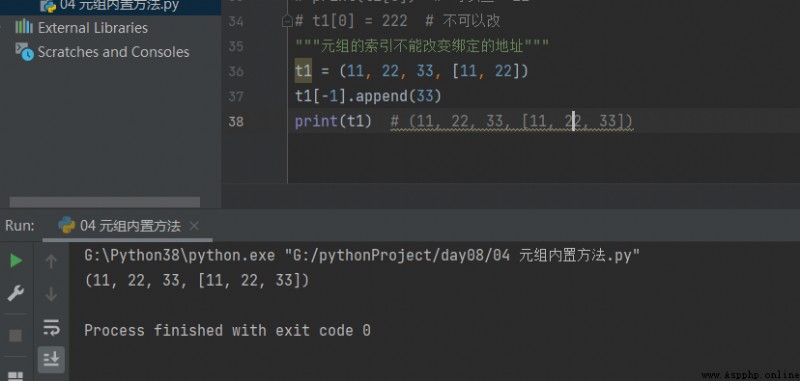
t1 = (11, 22, 33, [11, 22]) t1[-1].append(33) print(t1) # (11, 22, 33, [11, 22, 33])
set() 類型轉換 支持for循環的 並且數據必須是不可變類型
1.定義空集合需要使用關鍵字才可以
2.集合內數據必須是不可變類型(整型 浮點型 字符串 元組 布爾值)
3.去重
# 去重
s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
print(s1) # {1, 2, 3, 4, 5, 12}
l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
s2 = set(l1)
l1 = list(s2)
print(l1) # ['jason', 'tony', 'oscar']
4.模擬兩個人的好友集合
1.求f1和f2的共同好友
f1 = {'jason', 'tony', 'oscar', 'jerry'}
f2 = {'kevin', 'jerry', 'jason', 'lili'}
# 1.求f1和f2的共同好友
print(f1 & f2) # {'jason', 'jerry'}
2.求f1/f2獨有好友
print(f1 - f2) # {'oscar', 'tony'}
print(f2 - f1) # {'lili', 'kevin'}
3.求f1和f2所有的好友
print(f1 | f2) # {'jason', 'kevin', 'lili', 'oscar', 'jerry', 'tony'}
4.求f1和f2各自獨有的好友(排除共同好友)
print(f1 ^ f2) # {'kevin', 'lili', 'tony', 'oscar'}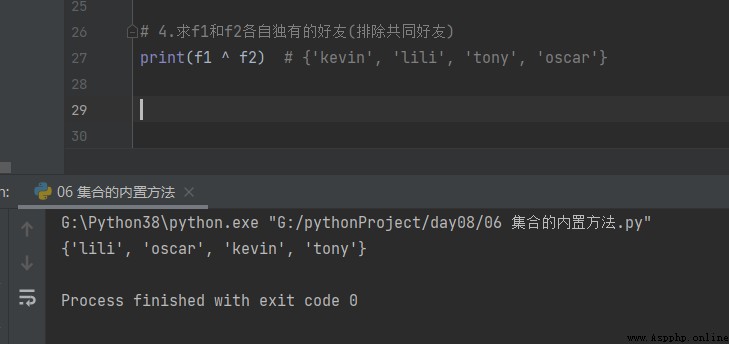
5.父集 子集
# 5.父集 子集
s1 = {1, 2, 3, 4, 5, 6, 7}
s2 = {3, 2, 1}
print(s1 > s2) # s1是否是s2的父集 s2是不是s1的子集
print(s1 < s2)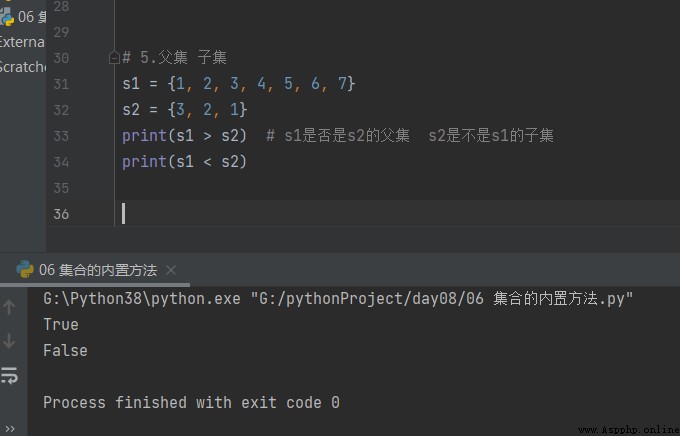
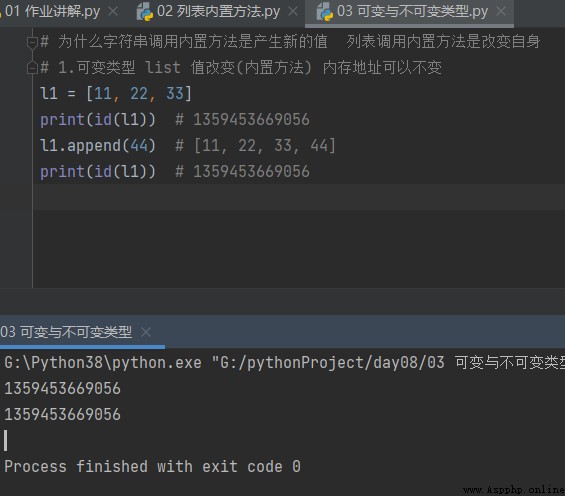
為什麼字符串調用內置方法是產生新的值 列表調用內置方法是改變自身
1.可變類型 list 值改變(內置方法) 內存地址可以不變
# 為什麼字符串調用內置方法是產生新的值 列表調用內置方法是改變自身 # 1.可變類型 list 值改變(內置方法) 內存地址可以不變 l1 = [11, 22, 33] print(id(l1)) # 1359453669056 l1.append(44) # [11, 22, 33, 44] print(id(l1)) # 1359453669056
2.不可變類型 str int float 值改變(內置方法),內存地址肯定變
# 2.不可變類型 str int float 值改變(內置方法),內存地址肯定變
s1 = '$hello$'
print(id(s1)) # 2807369626992#
s1 = s1.strip('$')
print(id(s1)) # 2807369039344
ccc = 666
print(id(ccc)) # 2807369267664
ccc = 990
print(id(ccc)) # 2807374985904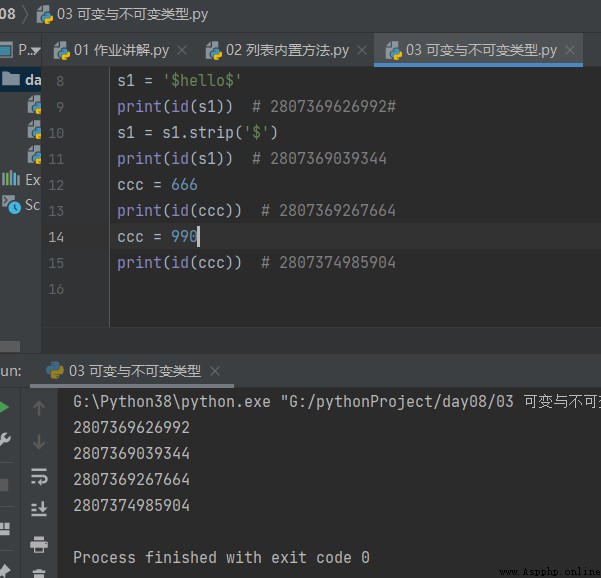
# 1.
# 利用列表編寫一個員工姓名管理系統
# 輸入1執行添加用戶名功能
# 輸入2執行查看所有用戶名功能
# 輸入3執行刪除指定用戶名功能
# ps: 思考如何讓程序循環起來並且可以根據不同指令執行不同操作
# 提示: 循環結構 + 分支結構
# 拔高: 是否可以換成字典或者數據的嵌套使用完成更加完善的員工管理而不是簡簡單單的一個用戶名(能寫就寫不會沒有關系)
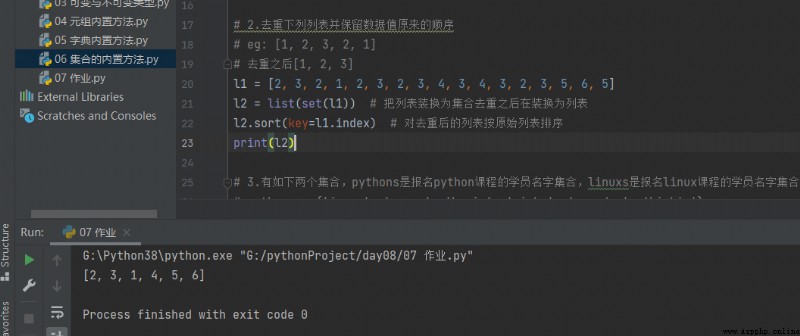
# 2.去重下列列表並保留數據值原來的順序
# eg: [1, 2, 3, 2, 1]
# 去重之後[1, 2, 3]
l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] l2 = list(set(l1)) # 把列表裝換為集合去重之後在裝換為列表 l2.sort(key=l1.index) # 對去重後的列表按原始列表排序 print(l2)
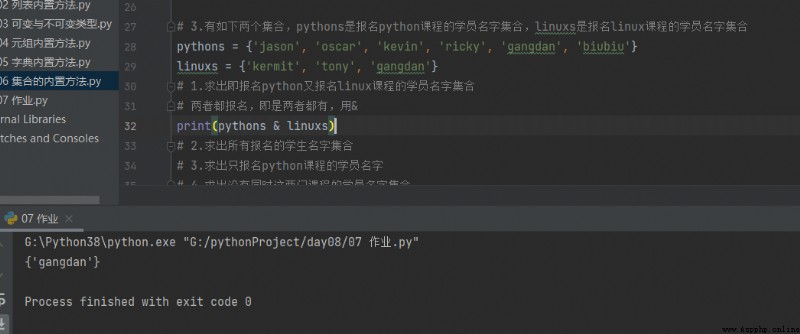
3.有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
1.求出即報名python又報名linux課程的學員名字集合
print(pythons & linuxs)
2.求出所有報名的學生名字集合
print(pythons | linuxs) # {'kevin', 'gangdan', 'jason', 'biubiu', 'kermit', 'tony', 'ricky', 'oscar'}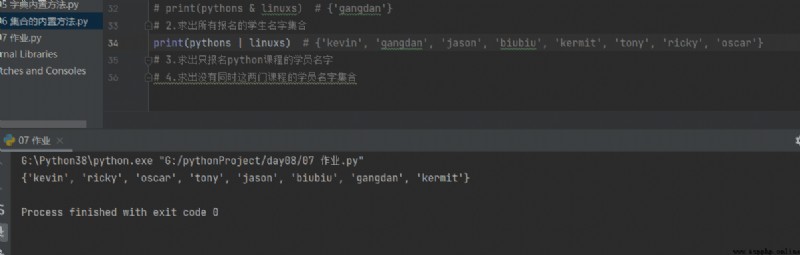
3.求出只報名python課程的學員名字
print(pythons - linuxs) # {'kevin', 'oscar', 'ricky', 'jason', 'biubiu'}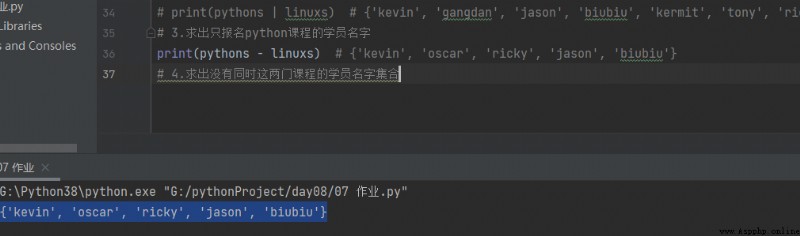
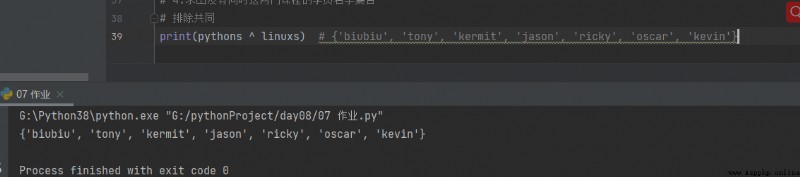
4.求出沒有同時這兩門課程的學員名字集合
print(pythons ^ linuxs) # {'biubiu', 'tony', 'kermit', 'jason', 'ricky', 'oscar', 'kevin'}