Liste des méthodes intégrées
Méthode intégrée au dictionnaire
Méthode intégrée Tuple
Collection de méthodes intégrées
Types variables et immuables
La liste ne produit pas de nouvelles valeurs après l'appel à la méthode intégrée
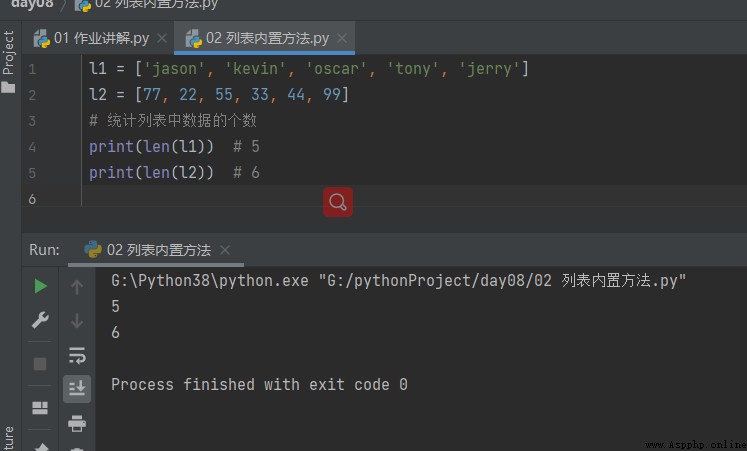
1.1 Nombre de valeurs de données dans la liste statistique
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry'] l2 = [77, 22, 55, 33, 44, 99] # Nombre de données dans la liste statistique print(len(l1)) # 5 print(len(l2)) # 6
2.Ajouter
2.1 Ajouter une valeur de données à la queueappend() Quel que soit le type de données entre parenthèses C'est comme une augmentation de la valeur des données
# 2.1Ajouter une valeur de données à la queueappend() Quel que soit le type de données entre parenthèses Tout est ajouté comme une valeur de données
res = l1.append('owen')
print(res) # None Vide
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', 'owen']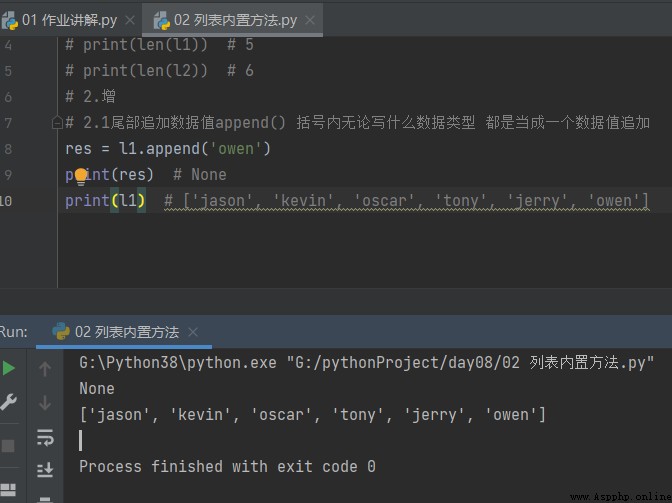
s1 = '$hello$'
res1 = s1.split('$')
print(res1) # ['', 'hello', '']
print(s1) # $hello$
l1.append([1, 2, 3, 4, 5])
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', [1, 2, 3, 4, 5]]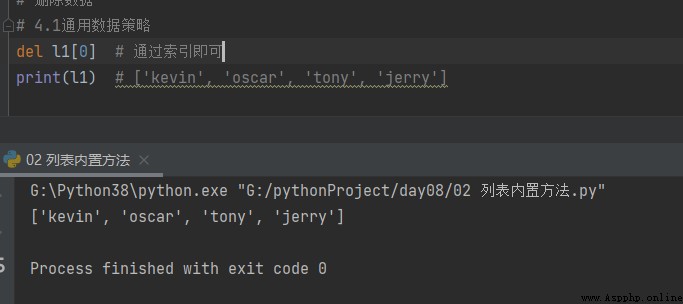
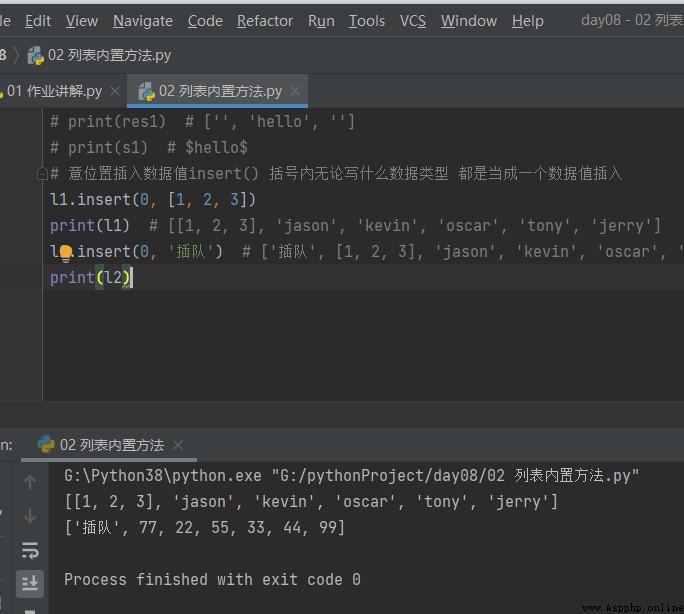
2.2 Insérer une valeur de données n'importe où insert Entre parenthèsesi Et quel type de données C'est comme un sous - ensemble de données, Fang Heng
# Insérer la valeur des données à la position souhaitée insert() Quel que soit le type de données entre parenthèses Tout est inséré comme une valeur de données l1.insert(0, [1, 2, 3]) print(l1) # [[1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry'] l2.insert(0, 'En ligne.') # ['En ligne.', [1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry'] print(l2)
2.3 Liste élargie
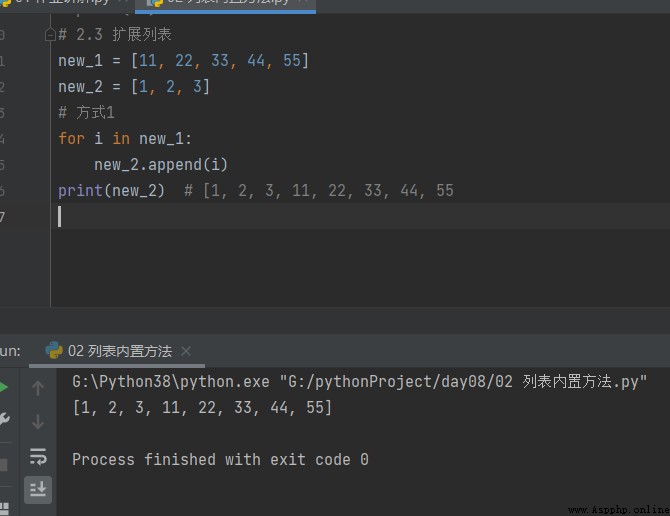
Comment1
# 2.3 Liste élargie new_1 = [11, 22, 33, 44, 55] new_2 = [1, 2, 3] # Comment1 for i in new_1: new_2.append(i) print(new_2) # [1, 2, 3, 11, 22, 33, 44, 55
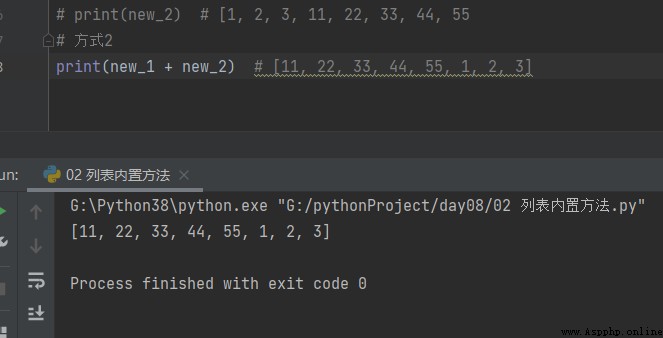
Comment2
# Comment2 print(new_1 + new_2) # [11, 22, 33, 44, 55, 1, 2, 3]
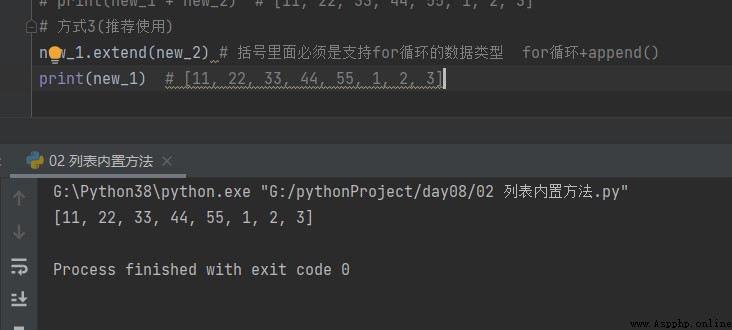
Comment3(Recommandé) extend
# Comment3(Recommandé) new_1.extend(new_2) # Le support doit être entre parenthèses forType de données pour la boucle forCycle+append() print(new_1) # [11, 22, 33, 44, 55, 1, 2, 3]
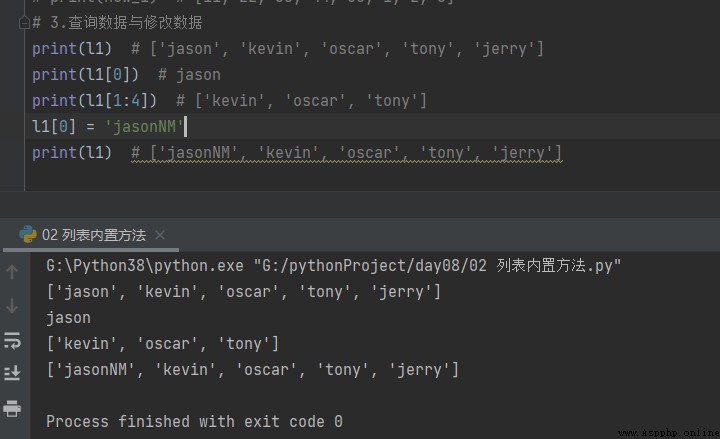
3. Interrogation et modification des données
# 3. Interrogation et modification des données print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry'] print(l1[0]) # jason print(l1[1:4]) # ['kevin', 'oscar', 'tony'] l1[0] = 'jasonNM' print(l1) # ['jasonNM', 'kevin', 'oscar', 'tony', 'jerry']
4.Supprimer les données
4.1 Politique générale en matière de données
# 4.1 Politique générale en matière de données del l1[0] # Grâce à l'index print(l1) # ['kevin', 'oscar', 'tony', 'jerry']
4.2 Suppression du nom de famille remove
# 4.2 Nom de famille supprimé
res = l1.remove('jason') # Les valeurs des données doivent être clairement indiquées entre parenthèses
print(l1, res) # ['kevin', 'oscar', 'tony', 'jerry'] None
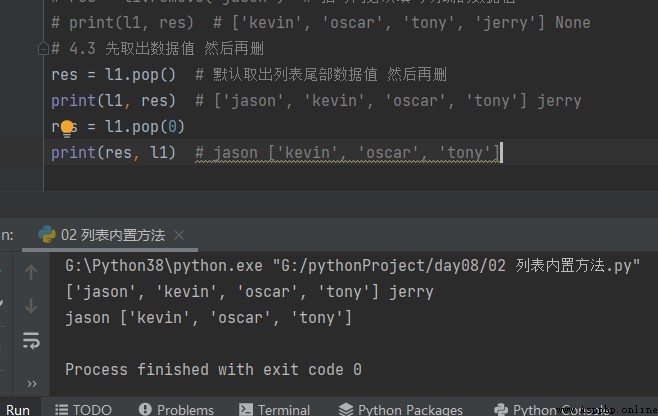
4.3 Prenez d'abord la valeur Supprimer pop
# 4.3 Extraire d'abord la valeur des données Et puis supprimer res = l1.pop() # Valeur par défaut des données de fin de liste Et puis supprimer print(l1, res) # ['jason', 'kevin', 'oscar', 'tony'] jerry res = l1.pop(0) print(res, l1) # jason ['kevin', 'oscar', 'tony']
5.Afficher les valeurs de l'index index
# 5. Voir la valeur index de la valeur de données pour
print(l1.index('jason'))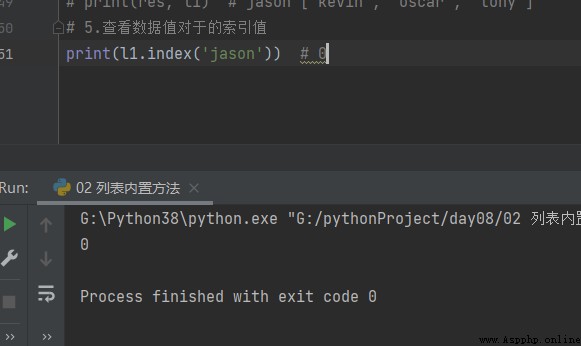
6. Compter les données dans lesquelles une valeur de données apparaît append
# 6. Compte le nombre d'occurrences d'une valeur de données
l1.append('jason')
print(l1.count('jason')) # 2
7.Trier sort Ordre croissant sort(reverse=True) Ordre décroissant b.sort(key=a.index) Poids mortbAppuyez.aTrier la liste pour
l2.sort() # Ordre croissant [22, 33, 44, 55, 77, 99] print(l2)
l2.sort(reverse=True) # Ordre décroissant print(l2) # [99, 77, 55, 44, 33, 22]
8.Flip reverse
l1.reverse() # Chutes avant et arrière print(l1) # ['jerry', 'tony', 'oscar', 'kevin', 'jason']
9.Comparer les opérations
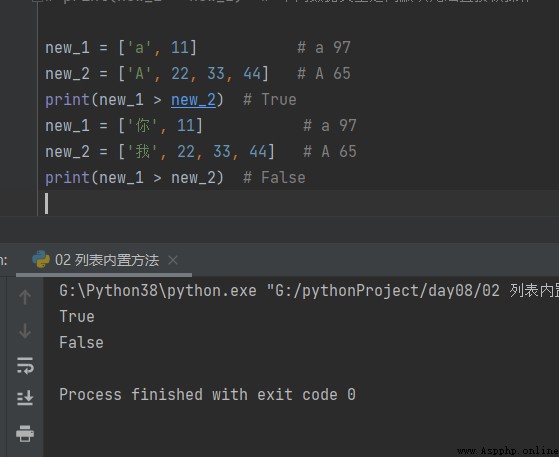
new_1 = [99, 22] new_2 = [11, 22, 33, 44] print(new_1 > new_2) # True Est comparé un par un dans l'ordre de position
new_1 = ['a', 11] new_2 = [11, 22, 33, 44] print(new_1 > new_2) # Par défaut, les opérations directes ne peuvent pas être effectuées entre différents types de données
new_1 = ['a', 11] # a 97 new_2 = ['A', 22, 33, 44] # A 65 print(new_1 > new_2) # True new_1 = ['Toi.', 11] # a 97 new_2 = ['- moi.', 22, 33, 44] # A 65 print(new_1 > new_2) # False
Les dictionnaires traitent rarement de la conversion de type Sont définis directement en utilisant
# Conversion de type(Compris.) Les dictionnaires traitent rarement de la conversion de type Sont définis directement en utilisant
print(dict([('name', 'jason'), ('pwd', 123)])) # {'name': 'jason', 'pwd': 123}
print(dict(name='jason', pwd=123)) # {'name': 'jason', 'pwd': 123}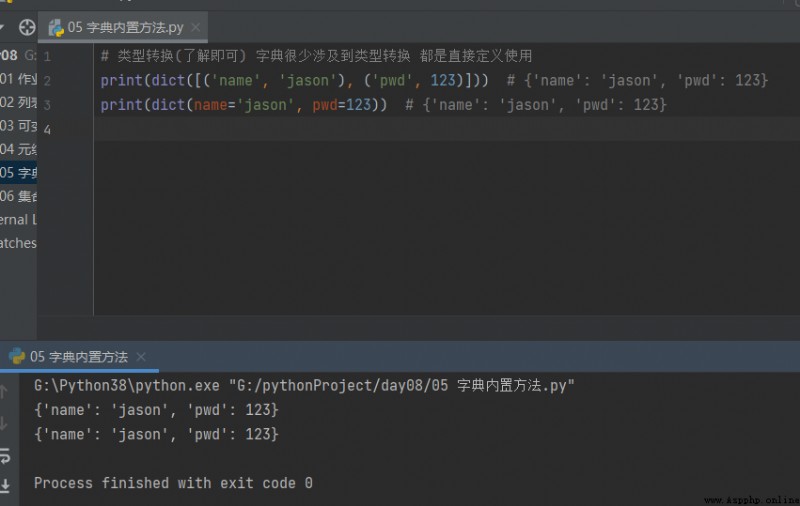
1.Dans le Dictionnairek:vLes paires de clés sont désordonnées
2.Valeur
# 2.Opération de valeur
print(info['username']) # Non recommandé Si la clé n'existe pas, une erreur sera signalée directement
print(info['xxx']) # Non recommandé Si la clé n'existe pas, une erreur sera signalée directement
print(info.get('username')) # jason
print(info.get('xxx')) # None
print(info.get('username', ' La clé n'a pas de valeur retournée Retour par défautNone')) # jason
print(info.get('xxx', ' La clé n'a pas de valeur retournée Retour par défautNone')) # La clé n'a pas de valeur retournée Retour par défautNone
print(info.get('xxx', 123)) # 123
print(info.get('xxx')) # None3. Compter le nombre de paires de valeurs clés dans le Dictionnaire len
print(len(info)) # 3

4.Modifier les données info
info['username'] = 'jasonNB' # Si la clé existe, elle est modifiée.
print(info) # {'username': 'jasonNB', 'pwd': 123, 'hobby': ['read', 'run']}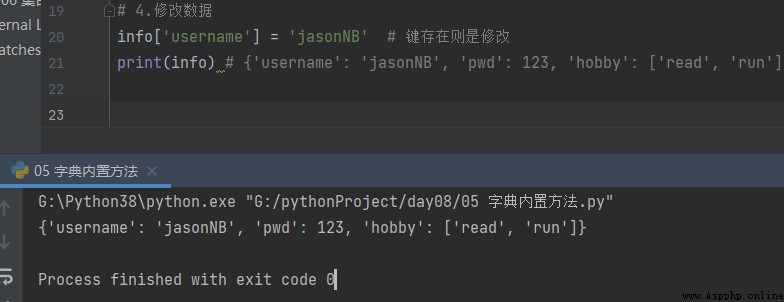
5.Nouvelles données info
# 5.Nouvelles données
info['salary'] = 6 # La clé n'existe pas est nouvelle
print(info) # {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}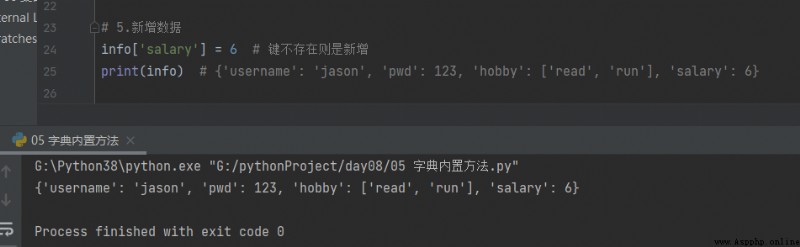
6.Supprimer les données
Comment1
# Comment1
del info['username']
print(info) # {'pwd': 123, 'hobby': ['read', 'run']}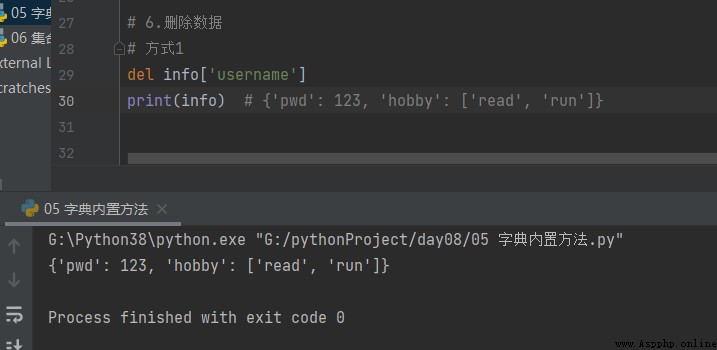
Comment2
res = info.pop('username')
print(info, res) # {'pwd': 123, 'hobby': ['read', 'run']} jason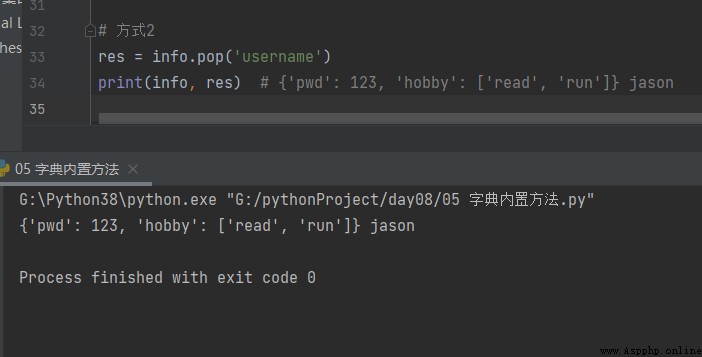
Comment3
# Comment3
info.popitem() # Suppression aléatoire
print(info) # {'username': 'jason', 'pwd': 123}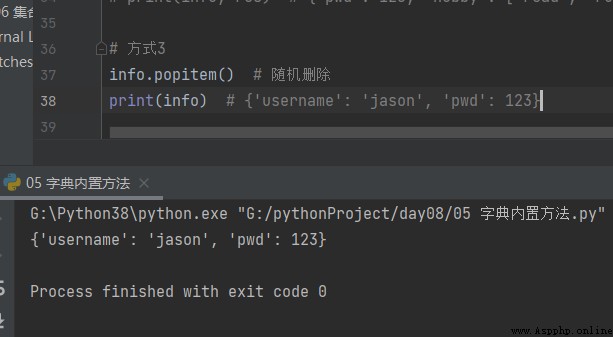
7. Clé d'accès rapide Valeur Valeurs clés par rapport aux données
print(info.keys()) # Obtenez tous leskValeur Le résultat est une liste dict_keys(['username', 'pwd', 'hobby'])
print(info.values()) # Obtenez tous lesvValeur Le résultat est une liste dict_values(['jason', 123, ['read', 'run']])
print(info.items()) # Obtenir un dictionnairekvValeurs clés par rapport aux données Organiser en tuples de liste dict_items([('username', 'jason'), ('pwd', 123), ('hobby', ['read', 'run'])])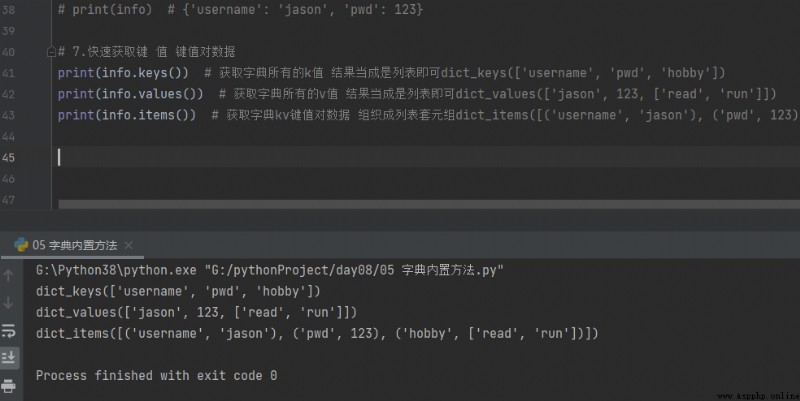
8.Modifier les données du dictionnaire Si la clé existe, elle est modifiée. La clé n'existe pas est nouvelle
# 8.Modifier les données du dictionnaire Si la clé existe, elle est modifiée. La clé n'existe pas est nouvelle
info.update({'username':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run']}
info.update({'xxx':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run'], 'xxx': 'jason123'}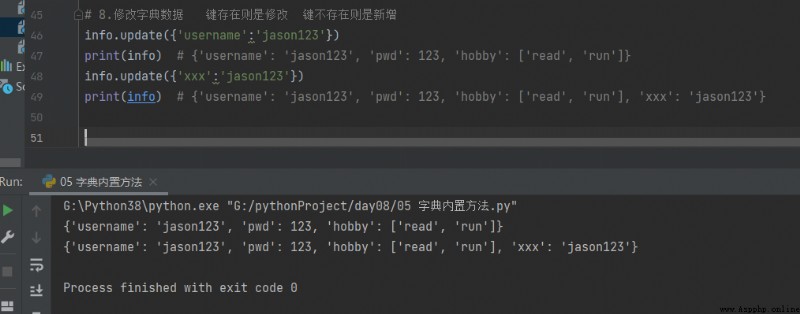
9. Dictionnaire de construction rapide Par défaut, toutes les touches utilisent une
# 9. Dictionnaire de construction rapide Par défaut, toutes les touches utilisent une
res = dict.fromkeys([1, 2, 3], None)
print(res) # {1: None, 2: None, 3: None}
new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}
new_dict['name'] = []
new_dict['name'].append(123)
new_dict['pwd'].append(123)
new_dict['hobby'].append('read')
print(new_dict) # {'name': [123], 'pwd': [123, 'read'], 'hobby': [123, 'read']}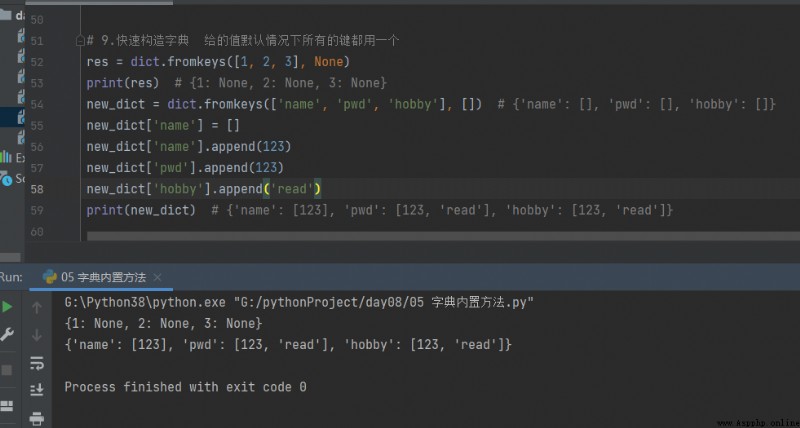
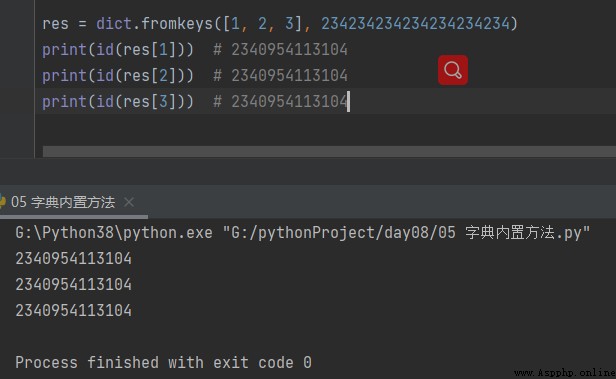
res = dict.fromkeys([1, 2, 3], 234234234234234234234) print(id(res[1])) # 2340954113104 print(id(res[2])) # 2340954113104 print(id(res[3])) # 2340954113104
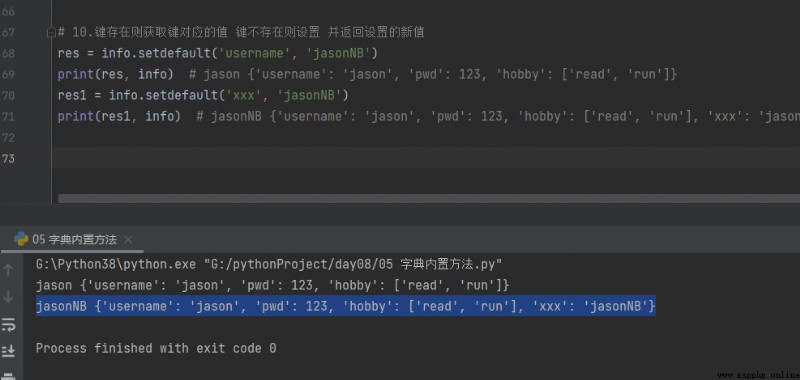
10. Si la clé existe, la valeur correspondant à la clé est obtenue Définir si la clé n'existe pas Et renvoie la nouvelle valeur définie
# Mots clés tuple
# Conversion de type Soutienfor Les types de données de la boucle peuvent être convertis en tuples
print(tuple(123)) # Je ne peux pas
print(tuple(123.11)) # Je ne peux pas
print(tuple('zhang')) # C'est bon.t1 = () # tuple
print(type(t1))
t2 = (1) # int
print(type(t2))
t3 = (11.11) # float
print(type(t3))
t4 = ('jason') # str
print(type(t4))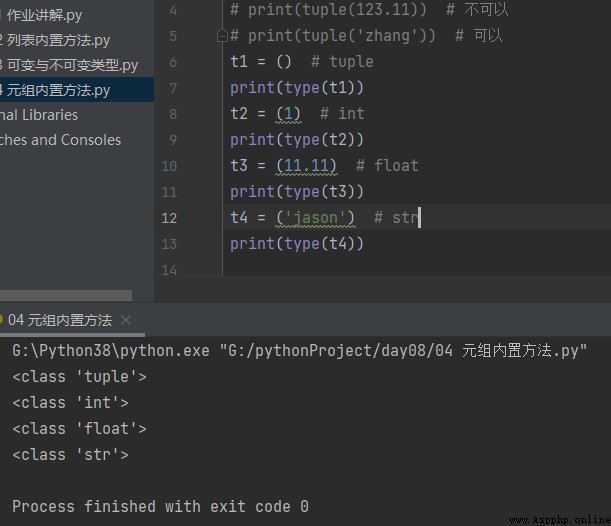
Quand il n'y a qu'une seule valeur de données dans le Tuple Les virgules ne peuvent pas être omises,Si omis Alors quel type de données est entre parenthèses est quel type de données
Suggestion: Écrire des tuples Virgule plus Même s'il n'y a qu'une seule donnée (111, ) ('jason', )ps: Les types de données qui peuvent stocker plus d'une valeur de données sont rencontrés plus tard S'il n'y a qu'une seule donnée La virgule profite de l'occasion pour ajouter
t2 = (1,) # tuple
print(type(t2))
t3 = (11.11,) # tuple
print(type(t3))
t4 = ('jason',) # tuple
print(type(t4))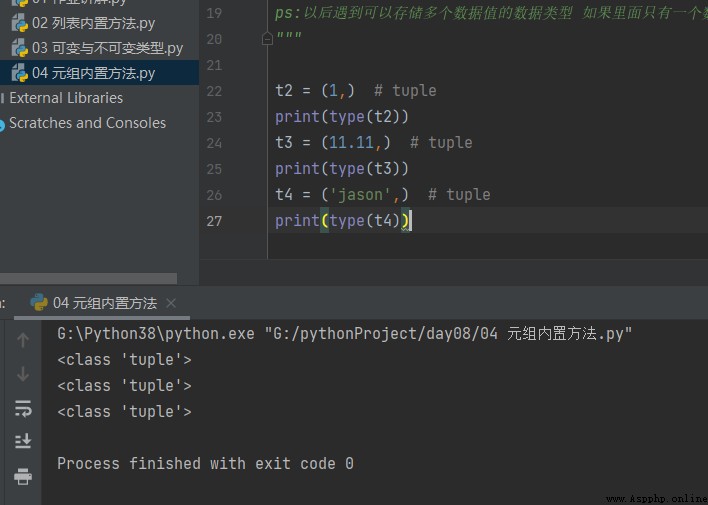
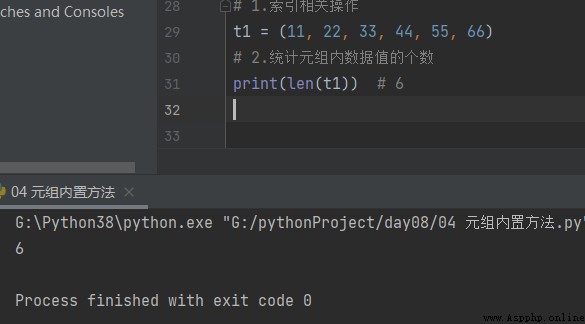
1. Compter le nombre de tuples
t1 = (11, 22, 33, 44, 55, 66) # 1. Compter le nombre de valeurs de données dans un Tuple print(len(t1)) # 6
2. Vérification et modification
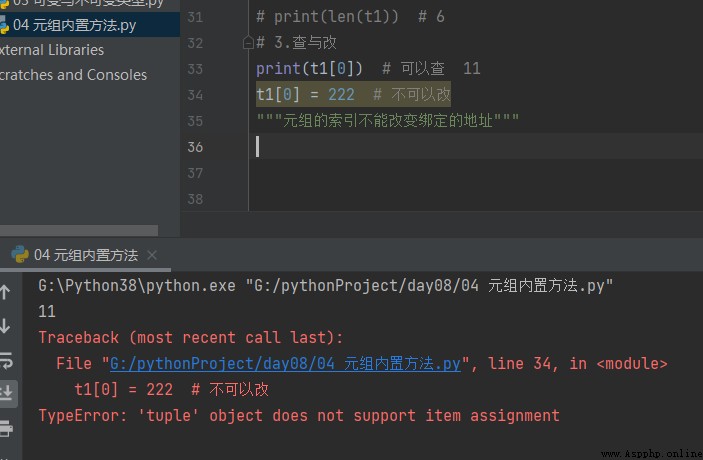
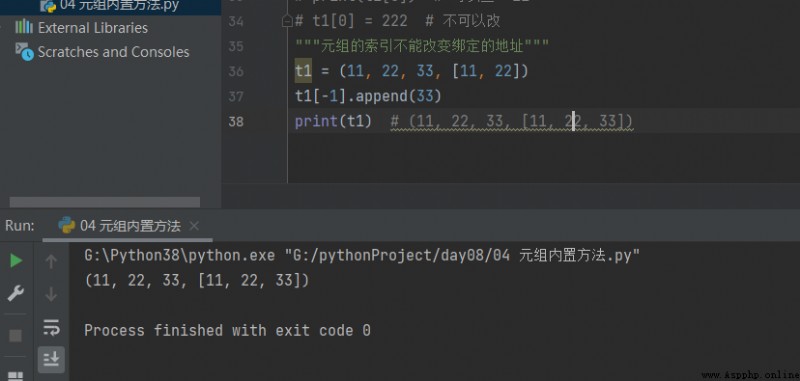
# 2. Vérification et modification print(t1[0]) # On peut vérifier 11 t1[0] = 222 # Je ne peux pas le changer. """ L'index du Tuple ne peut pas changer l'adresse de la liaison """
t1 = (11, 22, 33, [11, 22]) t1[-1].append(33) print(t1) # (11, 22, 33, [11, 22, 33])
set() Conversion de type SoutienforCyclique Et les données doivent être de type immuable
1. La définition d'une collection vide nécessite l'utilisation de mots clés pour
2. Les données de la collection doivent être de type immuable (Taille Type de point flottant String Tuple Booléen)
3.Poids mort
# Poids mort
s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
print(s1) # {1, 2, 3, 4, 5, 12}
l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
s2 = set(l1)
l1 = list(s2)
print(l1) # ['jason', 'tony', 'oscar']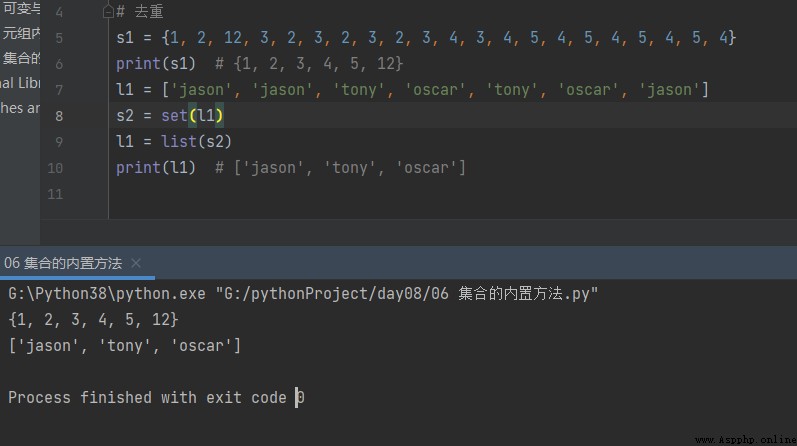
4. Simuler une collection d'amis de deux personnes
1.S'il te plaît.f1Etf2Amis communs
f1 = {'jason', 'tony', 'oscar', 'jerry'}
f2 = {'kevin', 'jerry', 'jason', 'lili'}
# 1.S'il te plaît.f1Etf2Amis communs
print(f1 & f2) # {'jason', 'jerry'}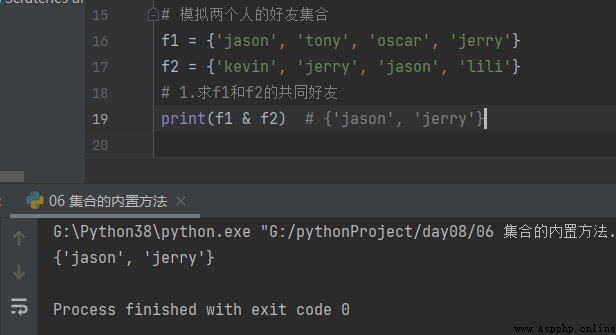
2.S'il te plaît.f1/f2 Amis uniques
print(f1 - f2) # {'oscar', 'tony'}
print(f2 - f1) # {'lili', 'kevin'}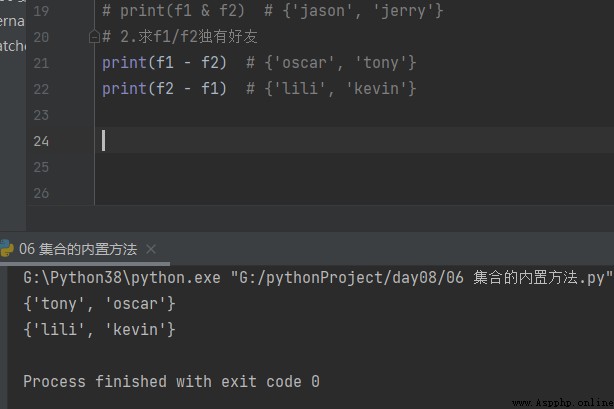
3.S'il te plaît.f1Etf2 Tous les amis
print(f1 | f2) # {'jason', 'kevin', 'lili', 'oscar', 'jerry', 'tony'}
4.S'il te plaît.f1Etf2 Leurs amis uniques ( Exclure les amis communs )
print(f1 ^ f2) # {'kevin', 'lili', 'tony', 'oscar'}
5.Ensemble de parents Sous - ensemble
# 5.Ensemble de parents Sous - ensemble
s1 = {1, 2, 3, 4, 5, 6, 7}
s2 = {3, 2, 1}
print(s1 > s2) # s1Oui Nons2Parent set of s2C'est ça?s1Un sous - ensemble de
print(s1 < s2)
Pourquoi une chaîne appelle une méthode intégrée pour générer une nouvelle valeur La liste appelle la méthode intégrée pour se changer
1.Type variable list Changement de valeur(Méthode intégrée) L'adresse mémoire peut rester la même
# Pourquoi une chaîne appelle une méthode intégrée pour générer une nouvelle valeur La liste appelle la méthode intégrée pour se changer # 1.Type variable list Changement de valeur(Méthode intégrée) L'adresse mémoire peut rester la même l1 = [11, 22, 33] print(id(l1)) # 1359453669056 l1.append(44) # [11, 22, 33, 44] print(id(l1)) # 1359453669056
2.Type immuable str int float Changement de valeur(Méthode intégrée),L'adresse mémoire doit changer
# 2.Type immuable str int float Changement de valeur(Méthode intégrée),L'adresse mémoire doit changer
s1 = '$hello$'
print(id(s1)) # 2807369626992#
s1 = s1.strip('$')
print(id(s1)) # 2807369039344
ccc = 666
print(id(ccc)) # 2807369267664
ccc = 990
print(id(ccc)) # 2807374985904
# 1.
# Écrire un système de gestion des noms d'employés à l'aide d'une liste
# Entrée1 Exécuter la fonction ajouter un nom d'utilisateur
# Entrée2 Exécuter la fonction afficher tous les noms d'utilisateurs
# Entrée3 Exécuter la fonction supprimer le nom d'utilisateur spécifié
# ps: Pensez à la façon de faire circuler le programme et d'effectuer différentes opérations selon différentes instructions
# Conseils: Structure du cycle + Structure des branches
# Éloignez - vous.: Est - il possible d'utiliser un dictionnaire ou des données imbriquées pour une meilleure gestion des employés plutôt qu'un simple nom d'utilisateur ( Ça n'a pas d'importance si tu peux écrire )
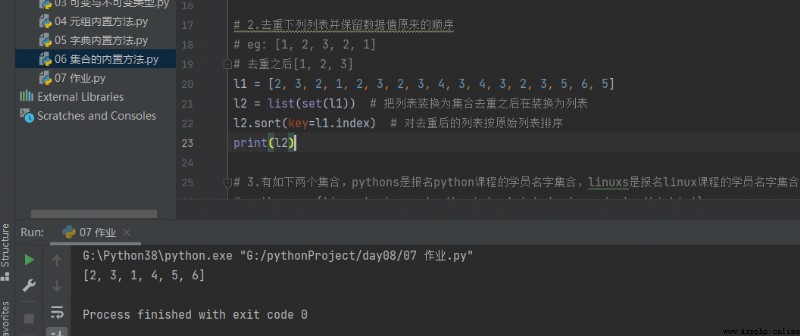
# 2. Répétez la liste ci - dessous et conservez l'ordre original des valeurs de données
# eg: [1, 2, 3, 2, 1]
# Après avoir pris du poids[1, 2, 3]
l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] l2 = list(set(l1)) # Remplacer la liste par la liste après avoir retiré la collection l2.sort(key=l1.index) # Trier la liste désdupliquée par la liste originale print(l2)
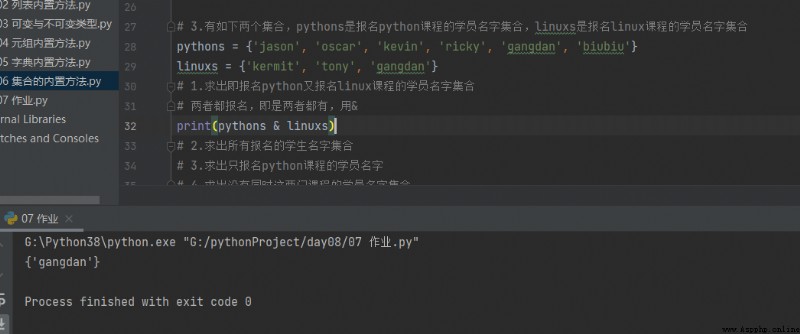
3. Il y a deux collections ,pythons C'est l'inscription python Collection de noms de participants pour le cours ,linuxs C'est l'inscription linux Collection de noms de participants pour le cours
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
1. Inscrivez - vous dès que possible python Encore une inscription linux Collection de noms de participants pour le cours
print(pythons & linuxs)
2. Trouvez une collection de noms pour tous les étudiants inscrits
print(pythons | linuxs) # {'kevin', 'gangdan', 'jason', 'biubiu', 'kermit', 'tony', 'ricky', 'oscar'}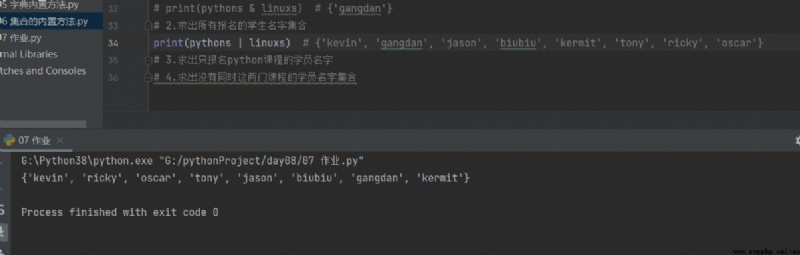
3. S'il vous plaît, inscrivez - vous seulement python Nom du participant au cours
print(pythons - linuxs) # {'kevin', 'oscar', 'ricky', 'jason', 'biubiu'}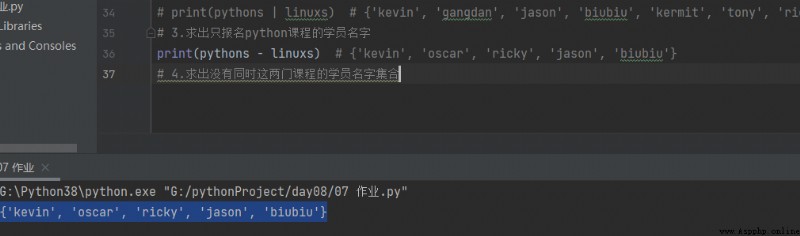
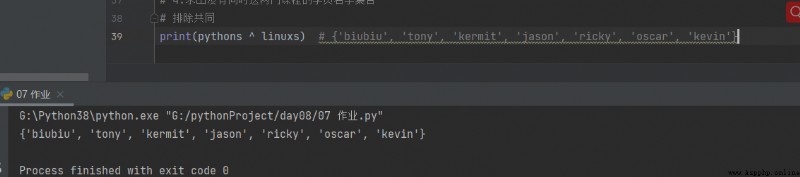
4. Trouvez une collection de noms d'étudiants qui n'ont pas les deux cours en même temps
print(pythons ^ linuxs) # {'biubiu', 'tony', 'kermit', 'jason', 'ricky', 'oscar', 'kevin'}