List built-in methods
Dictionary built in method
Tuple built-in method
Set built-in methods
Variable type and immutable type
The list does not produce new values after calling the built-in method
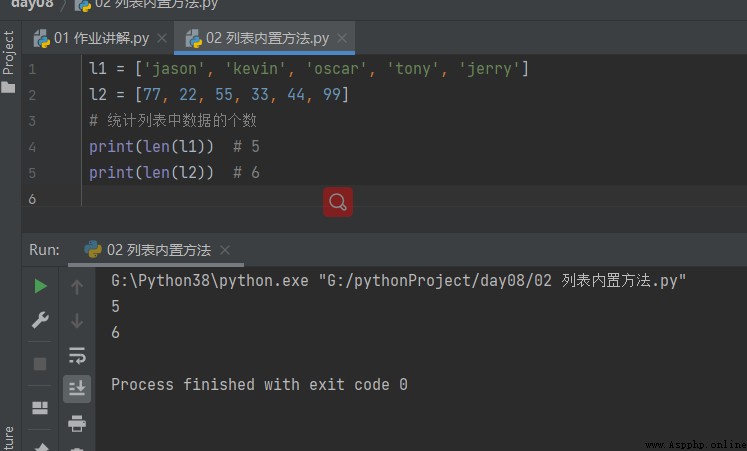
1.1 Count the number of data values in the list
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry'] l2 = [77, 22, 55, 33, 44, 99] # Count the number of data in the list print(len(l1)) # 5 print(len(l2)) # 6
2. increase
2.1 Append data value to the tail append() No matter what data type is written in brackets All of them are regarded as a data value increase
# 2.1 Append data value to the tail append() No matter what data type is written in brackets Are added as a data value
res = l1.append('owen')
print(res) # None empty
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', 'owen']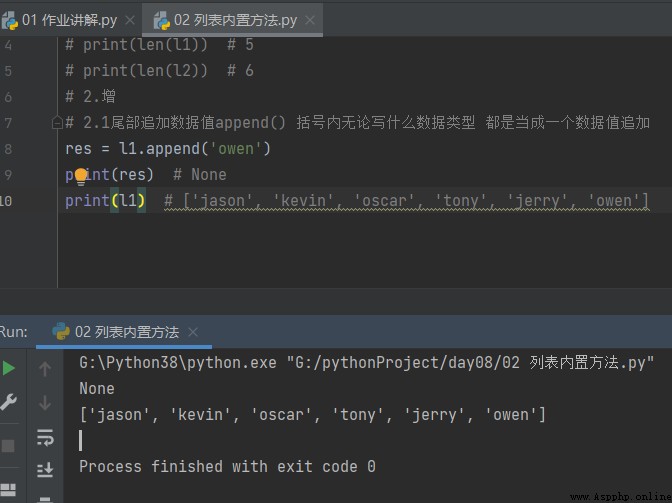
s1 = '$hello$'
res1 = s1.split('$')
print(res1) # ['', 'hello', '']
print(s1) # $hello$
l1.append([1, 2, 3, 4, 5])
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', [1, 2, 3, 4, 5]]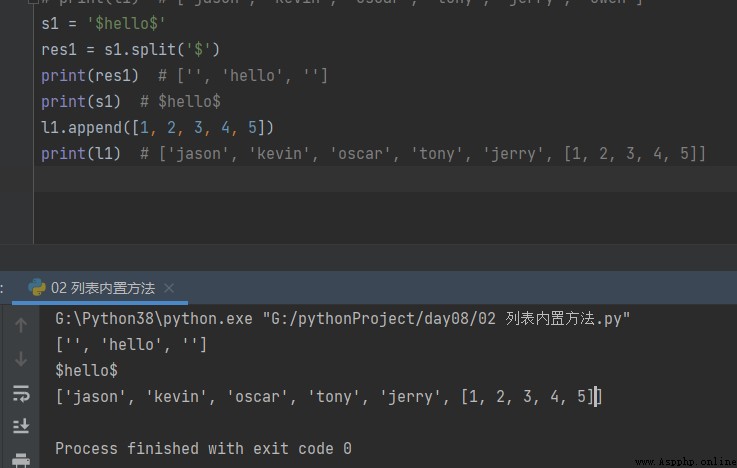
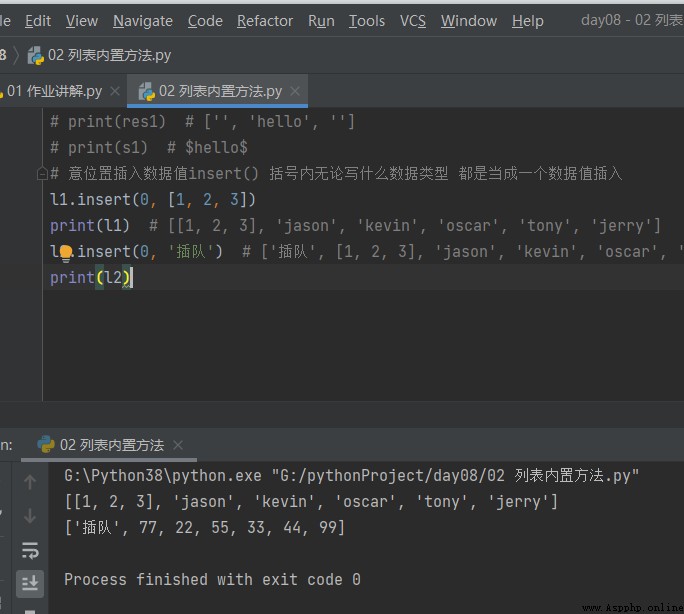
2.2 Insert data values anywhere insert In brackets i And what data types All of them are regarded as a data subset
# Insert the data value at the desired position insert() No matter what data type is written in brackets Are inserted as a data value l1.insert(0, [1, 2, 3]) print(l1) # [[1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry'] l2.insert(0, ' Jump the queue ') # [' Jump the queue ', [1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry'] print(l2)
2.3 Extended list
The way 1
# 2.3 Extended list new_1 = [11, 22, 33, 44, 55] new_2 = [1, 2, 3] # The way 1 for i in new_1: new_2.append(i) print(new_2) # [1, 2, 3, 11, 22, 33, 44, 55

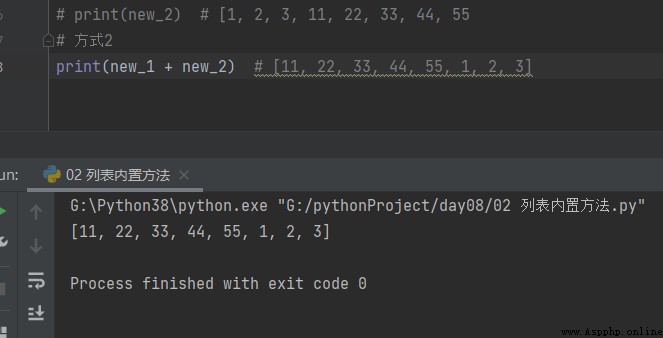
The way 2
# The way 2 print(new_1 + new_2) # [11, 22, 33, 44, 55, 1, 2, 3]
The way 3( Recommended ) extend
# The way 3( Recommended ) new_1.extend(new_2) # The brackets must support for The data type of the loop for loop +append() print(new_1) # [11, 22, 33, 44, 55, 1, 2, 3]
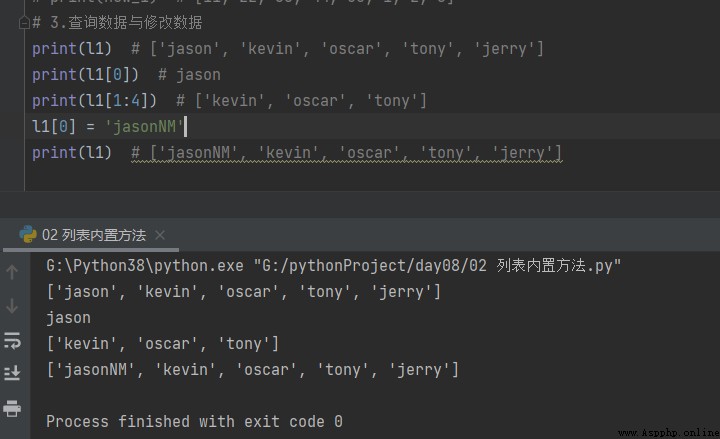
3. Query data and modify data
# 3. Query data and modify data print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry'] print(l1[0]) # jason print(l1[1:4]) # ['kevin', 'oscar', 'tony'] l1[0] = 'jasonNM' print(l1) # ['jasonNM', 'kevin', 'oscar', 'tony', 'jerry']
4. Delete data
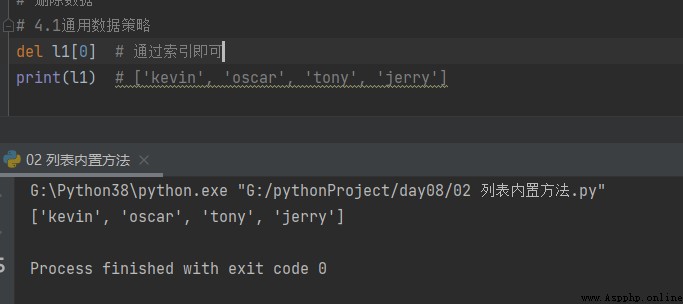
4.1 Common data policy
# 4.1 Common data policy del l1[0] # Through the index print(l1) # ['kevin', 'oscar', 'tony', 'jerry']
4.2 Deleting by name remove
# 4.2 Delete by name
res = l1.remove('jason') # Clear data values must be filled in brackets
print(l1, res) # ['kevin', 'oscar', 'tony', 'jerry'] None
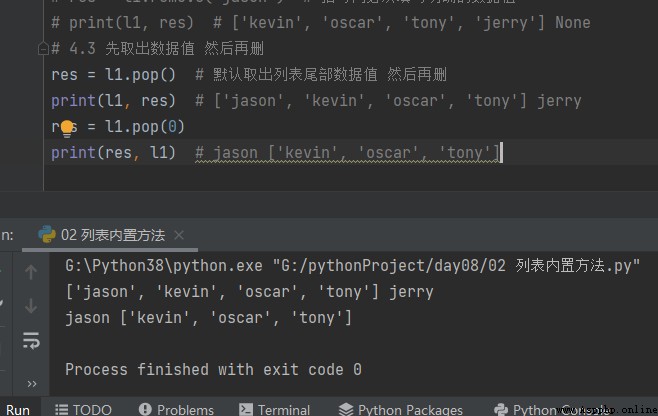
4.3 Take out the value first In the delete pop
# 4.3 Take out the data value first And then delete res = l1.pop() # By default, the data value at the end of the list is retrieved And then delete print(l1, res) # ['jason', 'kevin', 'oscar', 'tony'] jerry res = l1.pop(0) print(res, l1) # jason ['kevin', 'oscar', 'tony']
5. Look at the index values index
# 5. View the index value of the data value
print(l1.index('jason'))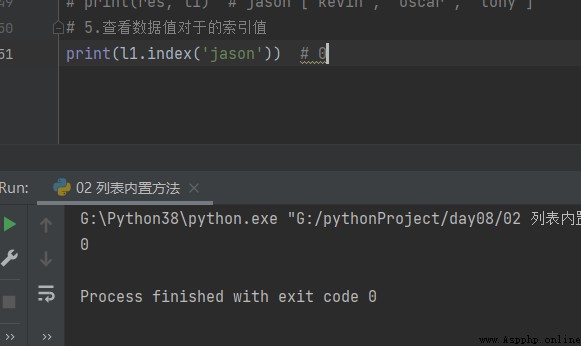
6. Statistics on the occurrence of a certain data value append
# 6. Count the number of occurrences of a data value
l1.append('jason')
print(l1.count('jason')) # 2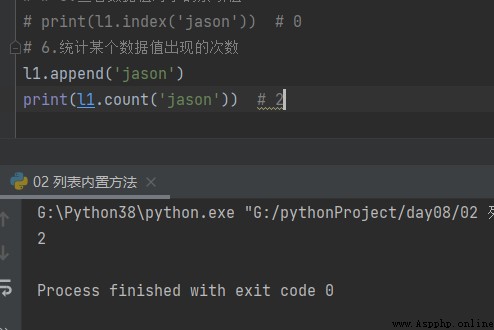
7. Sort sort Ascending sort(reverse=True) Descending b.sort(key=a.index) duplicate removal b Press a List sort for
l2.sort() # Ascending [22, 33, 44, 55, 77, 99] print(l2)
l2.sort(reverse=True) # Descending print(l2) # [99, 77, 55, 44, 33, 22]
8. Flip reverse
l1.reverse() # Fall back and forth print(l1) # ['jerry', 'tony', 'oscar', 'kevin', 'jason']
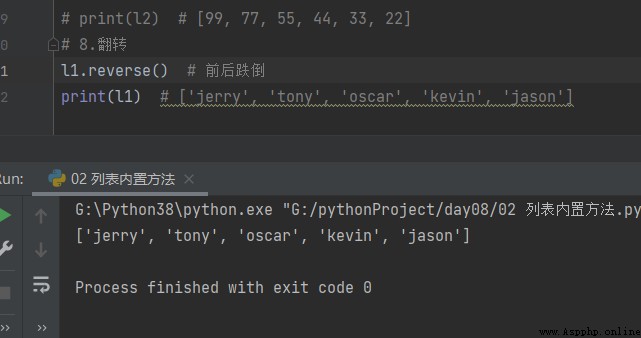
9. Comparison operations
new_1 = [99, 22] new_2 = [11, 22, 33, 44] print(new_1 > new_2) # True It is to compare one by one according to the position order
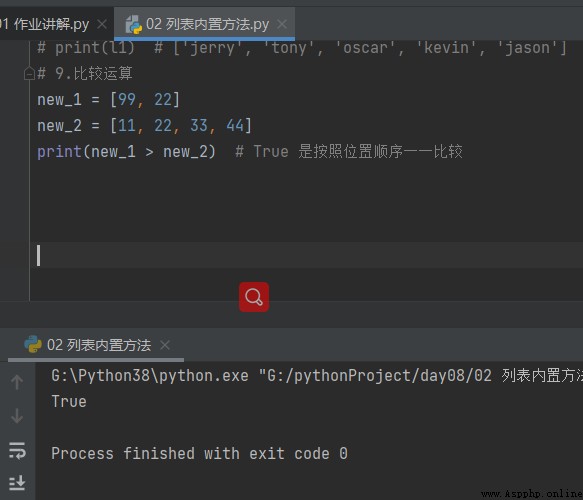
new_1 = ['a', 11] new_2 = [11, 22, 33, 44] print(new_1 > new_2) # Different data types cannot be operated directly by default
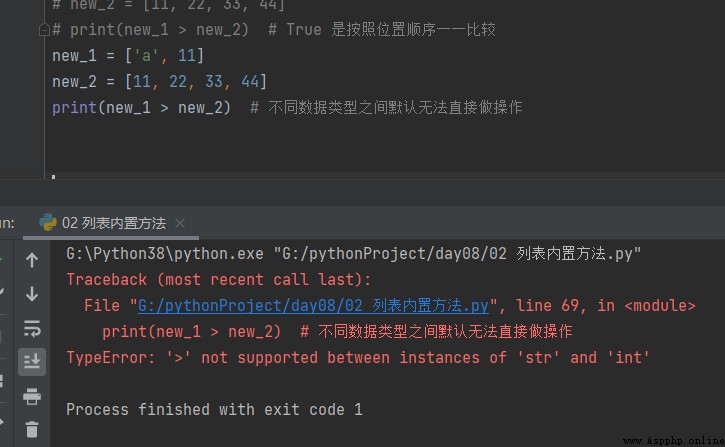
new_1 = ['a', 11] # a 97 new_2 = ['A', 22, 33, 44] # A 65 print(new_1 > new_2) # True new_1 = [' you ', 11] # a 97 new_2 = [' I ', 22, 33, 44] # A 65 print(new_1 > new_2) # False
Dictionaries rarely involve type conversions Are directly defined and used
# Type conversion ( Understanding can ) Dictionaries rarely involve type conversions Are directly defined and used
print(dict([('name', 'jason'), ('pwd', 123)])) # {'name': 'jason', 'pwd': 123}
print(dict(name='jason', pwd=123)) # {'name': 'jason', 'pwd': 123}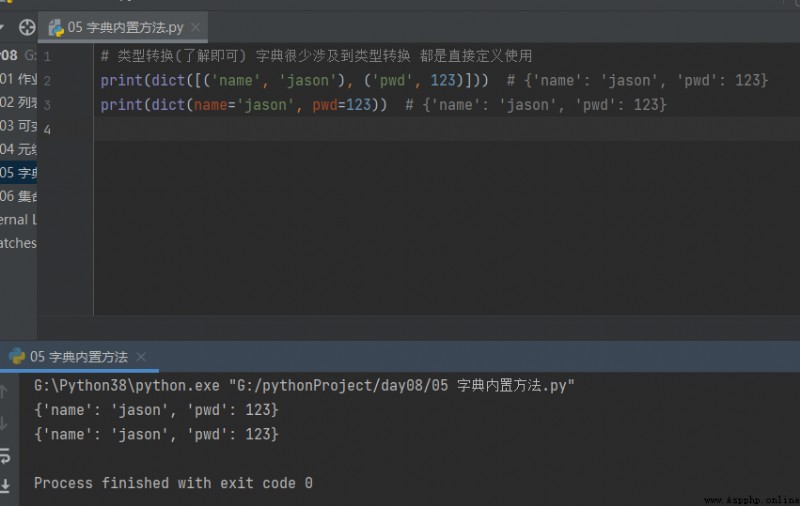
1. In dictionary k:v Key value pairs are unordered
2. Value
# 2. Value operation
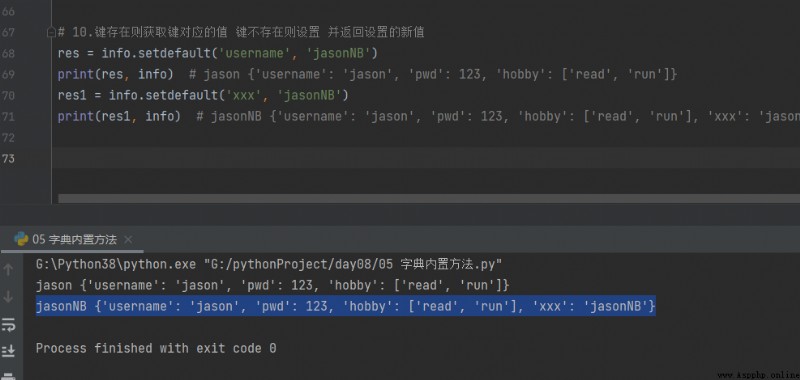
print(info['username']) # It is not recommended to use If the key does not exist, an error will be reported directly
print(info['xxx']) # It is not recommended to use If the key does not exist, an error will be reported directly
print(info.get('username')) # jason
print(info.get('xxx')) # None
print(info.get('username', ' The key does not have a returned value Default return None')) # jason
print(info.get('xxx', ' The key does not have a returned value Default return None')) # The key does not have a returned value Default return None
print(info.get('xxx', 123)) # 123
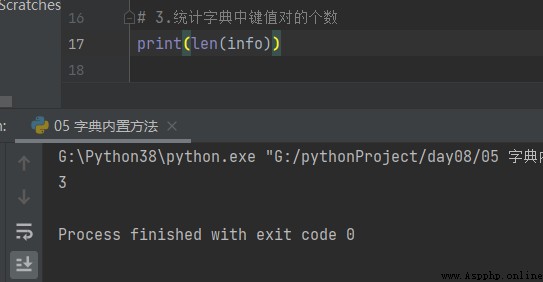
print(info.get('xxx')) # None3. A dictionary of key pairs in the len
print(len(info)) # 3
4. Modifying data info
info['username'] = 'jasonNB' # If the key exists, it is modified
print(info) # {'username': 'jasonNB', 'pwd': 123, 'hobby': ['read', 'run']}
5. The new data info
# 5. The new data
info['salary'] = 6 # If the key does not exist, it is added
print(info) # {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}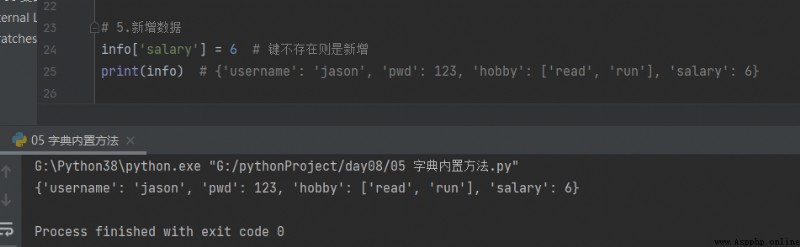
6. Delete data
The way 1
# The way 1
del info['username']
print(info) # {'pwd': 123, 'hobby': ['read', 'run']}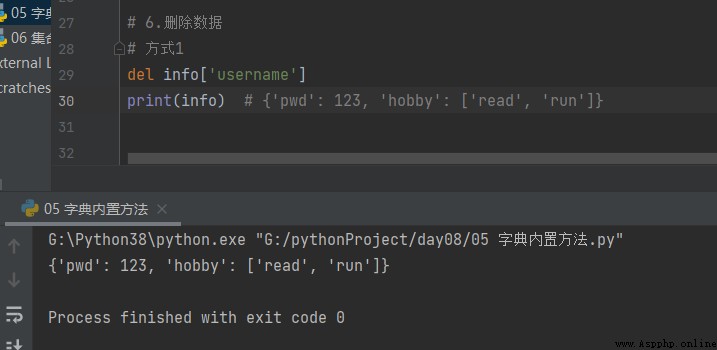
The way 2
res = info.pop('username')
print(info, res) # {'pwd': 123, 'hobby': ['read', 'run']} jason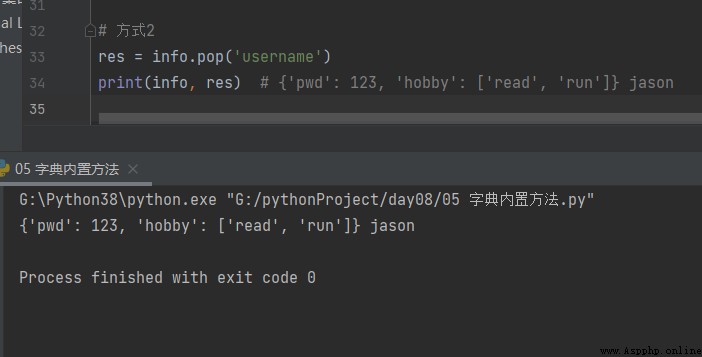
The way 3
# The way 3
info.popitem() # Random delete
print(info) # {'username': 'jason', 'pwd': 123}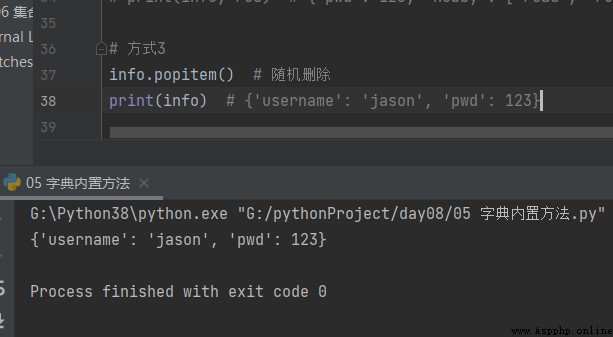
7. Quick access key value Key value pair data
print(info.keys()) # Get all the dictionary's k value The result can be regarded as a list dict_keys(['username', 'pwd', 'hobby'])
print(info.values()) # Get all the dictionary's v value The result can be regarded as a list dict_values(['jason', 123, ['read', 'run']])
print(info.items()) # Get the dictionary kv Key value pair data Organize into list tuples dict_items([('username', 'jason'), ('pwd', 123), ('hobby', ['read', 'run'])])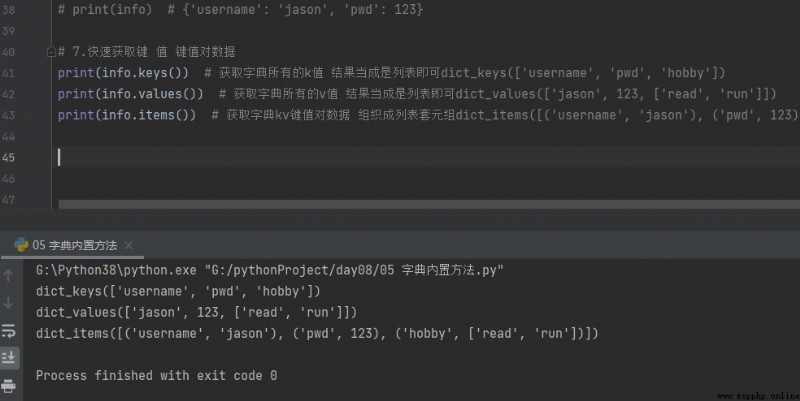
8. Modify dictionary data If the key exists, it is modified If the key does not exist, it is added
# 8. Modify dictionary data If the key exists, it is modified If the key does not exist, it is added
info.update({'username':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run']}
info.update({'xxx':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run'], 'xxx': 'jason123'}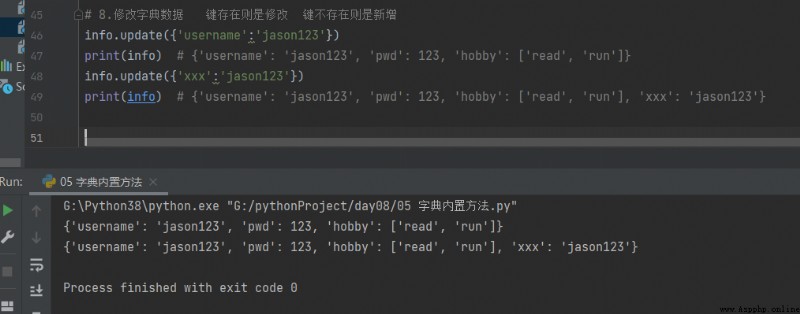
9. Quickly construct a dictionary Given a value, by default, all keys use a
# 9. Quickly construct a dictionary Given a value, by default, all keys use a
res = dict.fromkeys([1, 2, 3], None)
print(res) # {1: None, 2: None, 3: None}
new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}
new_dict['name'] = []
new_dict['name'].append(123)
new_dict['pwd'].append(123)
new_dict['hobby'].append('read')
print(new_dict) # {'name': [123], 'pwd': [123, 'read'], 'hobby': [123, 'read']}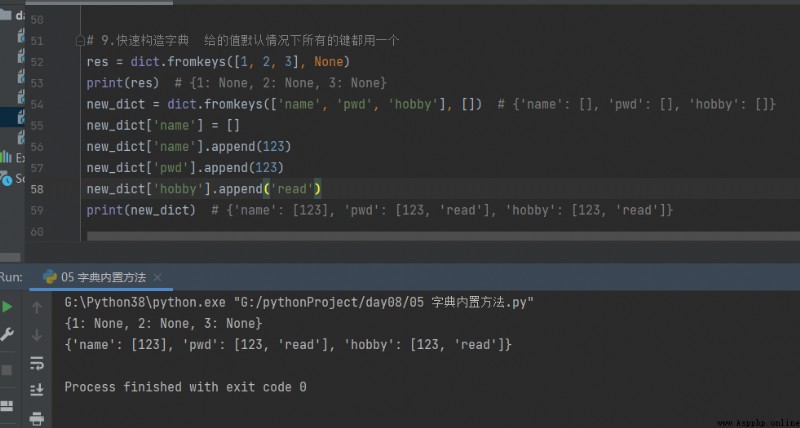
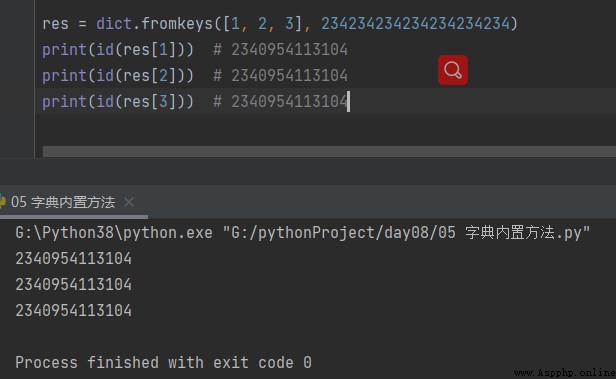
res = dict.fromkeys([1, 2, 3], 234234234234234234234) print(id(res[1])) # 2340954113104 print(id(res[2])) # 2340954113104 print(id(res[3])) # 2340954113104
10. If the key exists, get the value corresponding to the key If the key does not exist, set And return the new value set
# keyword tuple
# Type conversion Support for All data types of a loop can be converted to tuples
print(tuple(123)) # Can not be
print(tuple(123.11)) # Can not be
print(tuple('zhang')) # Sure t1 = () # tuple
print(type(t1))
t2 = (1) # int
print(type(t2))
t3 = (11.11) # float
print(type(t3))
t4 = ('jason') # str
print(type(t4))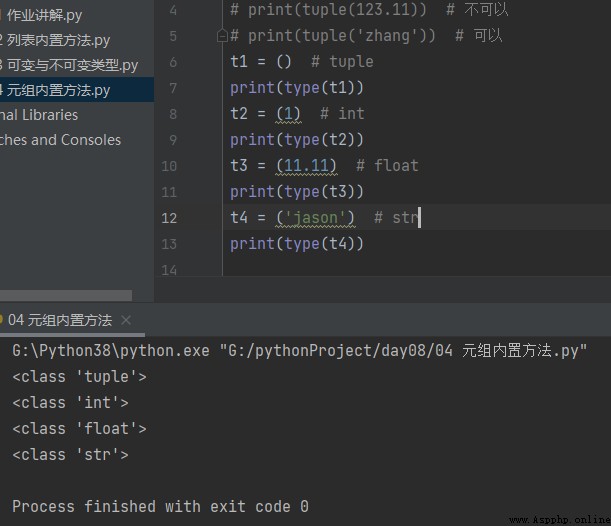
When there is only one data value in a tuple Commas cannot be omitted , If you omit The data type in the brackets is the data type
Suggest : Write tuples Comma plus Even if there is only one data (111, ) ('jason', )ps: In the future, you will encounter data types that can store multiple data values If there is only one data The comma also took the opportunity to add
t2 = (1,) # tuple
print(type(t2))
t3 = (11.11,) # tuple
print(type(t3))
t4 = ('jason',) # tuple
print(type(t4))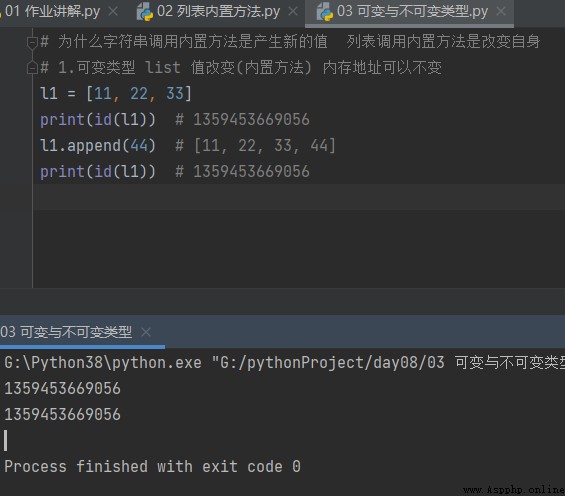
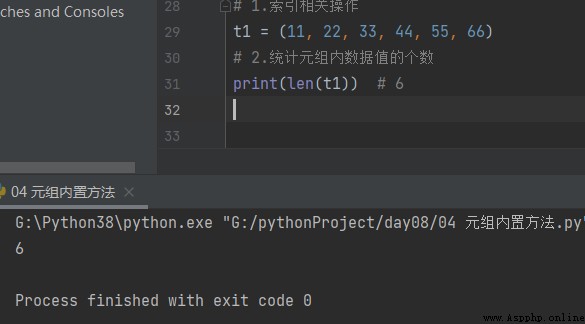
1. Count the number of tuples
t1 = (11, 22, 33, 44, 55, 66) # 1. Count the number of data values in the tuple print(len(t1)) # 6
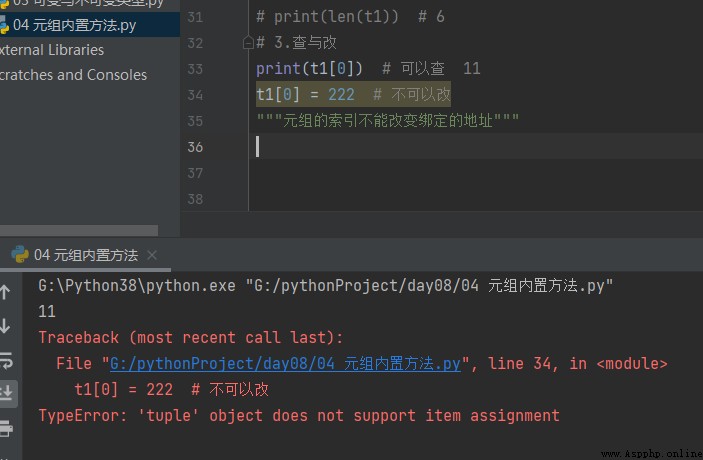
2. Check and correct
# 2. Check and correct print(t1[0]) # You can check 11 t1[0] = 222 # It can't be changed """ The index of tuples cannot change the bound address """
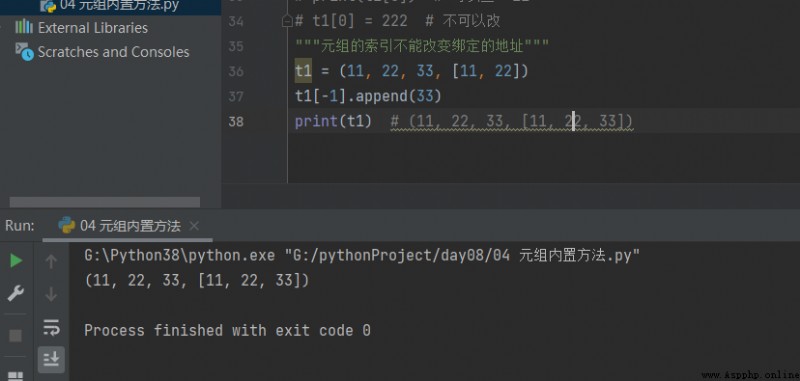
t1 = (11, 22, 33, [11, 22]) t1[-1].append(33) print(t1) # (11, 22, 33, [11, 22, 33])
set() Type conversion Support for Cyclic And the data must be immutable
1. To define an empty collection, you need to use keywords
2. Data in a collection must be of immutable type ( integer floating-point character string Tuples Boolean value )
3. duplicate removal
# duplicate removal
s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
print(s1) # {1, 2, 3, 4, 5, 12}
l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
s2 = set(l1)
l1 = list(s2)
print(l1) # ['jason', 'tony', 'oscar']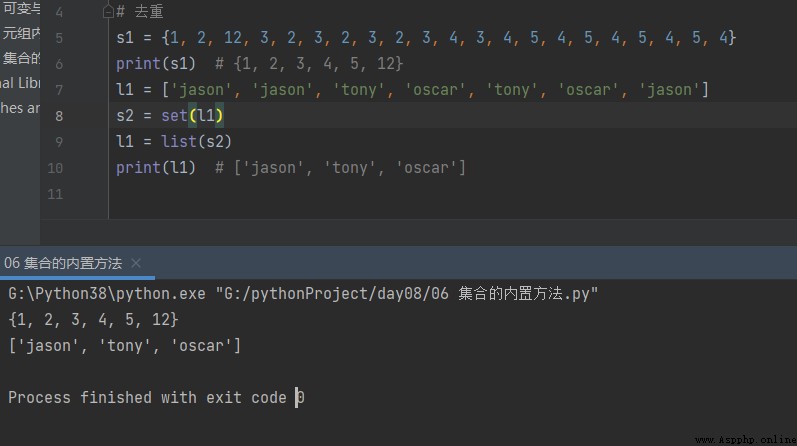
4. Simulate two people's friend collection
1. seek f1 and f2 Our mutual friends
f1 = {'jason', 'tony', 'oscar', 'jerry'}
f2 = {'kevin', 'jerry', 'jason', 'lili'}
# 1. seek f1 and f2 Our mutual friends
print(f1 & f2) # {'jason', 'jerry'}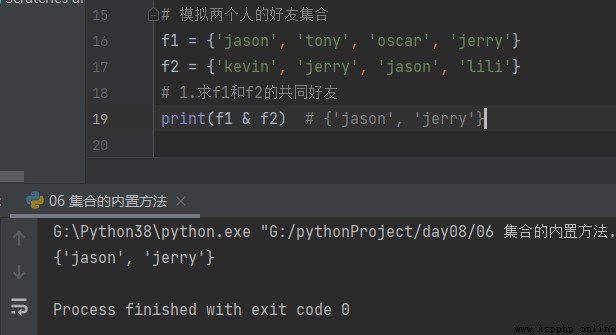
2. seek f1/f2 Unique friends
print(f1 - f2) # {'oscar', 'tony'}
print(f2 - f1) # {'lili', 'kevin'}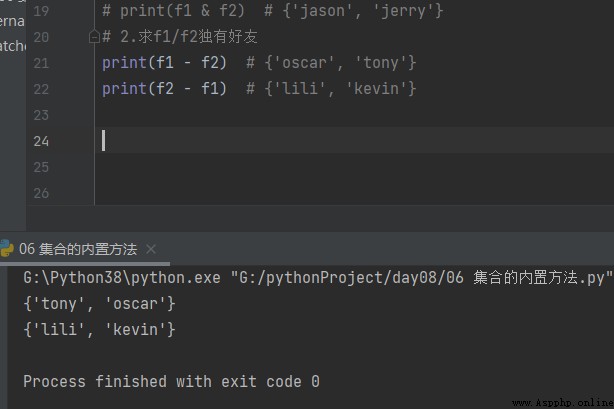
3. seek f1 and f2 All friends
print(f1 | f2) # {'jason', 'kevin', 'lili', 'oscar', 'jerry', 'tony'}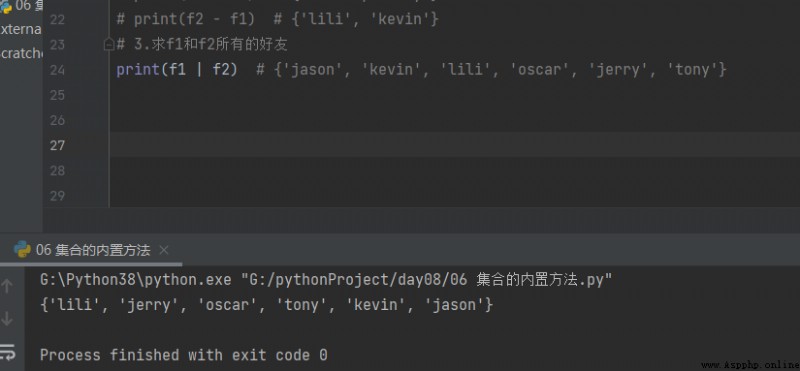
4. seek f1 and f2 Their own unique friends ( Exclude common friends )
print(f1 ^ f2) # {'kevin', 'lili', 'tony', 'oscar'}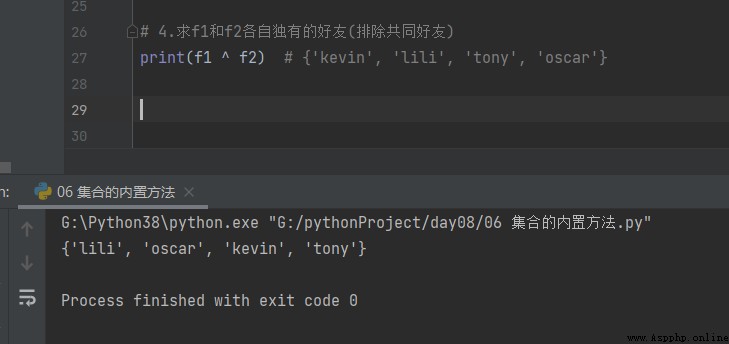
5. Superset A subset of
# 5. Superset A subset of
s1 = {1, 2, 3, 4, 5, 6, 7}
s2 = {3, 2, 1}
print(s1 > s2) # s1 Whether it is s2 A set of parent s2 Is it right? s1 Subset
print(s1 < s2)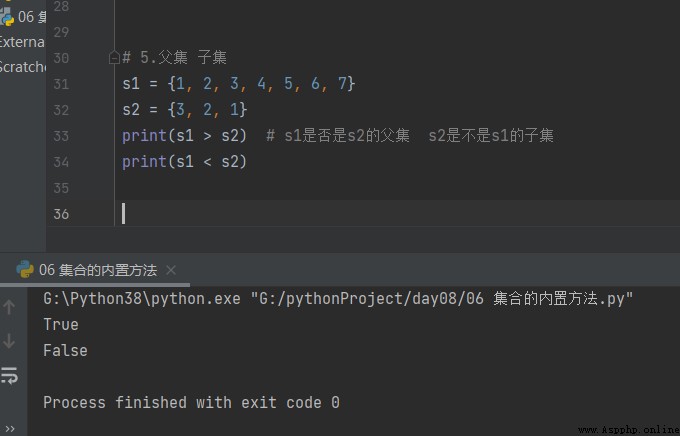
Why do string calls to built-in methods generate new values The list calls built-in methods to change itself
1. Variable type list Value change ( Built-in methods ) The memory address can remain unchanged
# Why do string calls to built-in methods generate new values The list calls built-in methods to change itself # 1. Variable type list Value change ( Built-in methods ) The memory address can remain unchanged l1 = [11, 22, 33] print(id(l1)) # 1359453669056 l1.append(44) # [11, 22, 33, 44] print(id(l1)) # 1359453669056
2. Immutable type str int float Value change ( Built-in methods ), The memory address must have changed
# 2. Immutable type str int float Value change ( Built-in methods ), The memory address must have changed
s1 = '$hello$'
print(id(s1)) # 2807369626992#
s1 = s1.strip('$')
print(id(s1)) # 2807369039344
ccc = 666
print(id(ccc)) # 2807369267664
ccc = 990
print(id(ccc)) # 2807374985904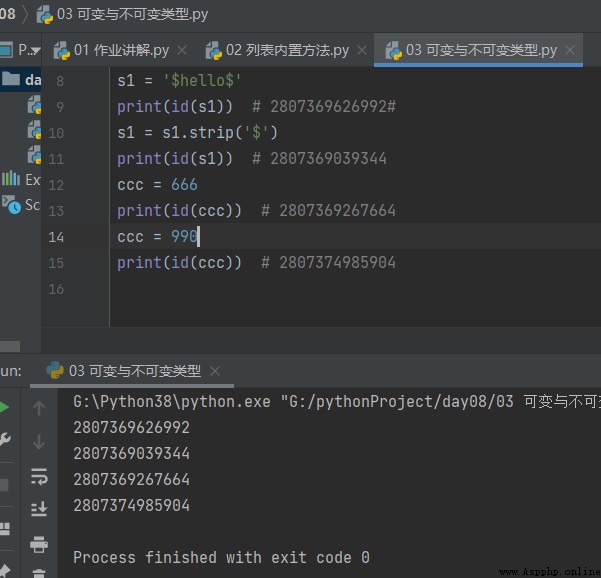
# 1.
# Use the list to write an employee name management system
# Input 1 Execute the function of adding user name
# Input 2 Perform the view all user names function
# Input 3 Execute the function of deleting the specified user name
# ps: Think about how to make the program loop and perform different operations according to different instructions
# Tips : Loop structure + Branching structure
# Elevation : Whether it can be replaced by dictionary or nested use of data to complete more perfect employee management rather than a simple user name ( It doesn't matter if you can write )
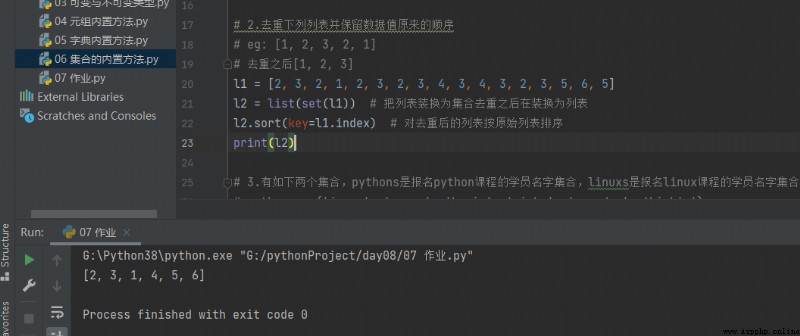
# 2. Remove the following list and keep the original order of data values
# eg: [1, 2, 3, 2, 1]
# After de duplication [1, 2, 3]
l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] l2 = list(set(l1)) # Replace the list with a set, and then replace it with a list l2.sort(key=l1.index) # Sort the de duplicated list according to the original list print(l2)
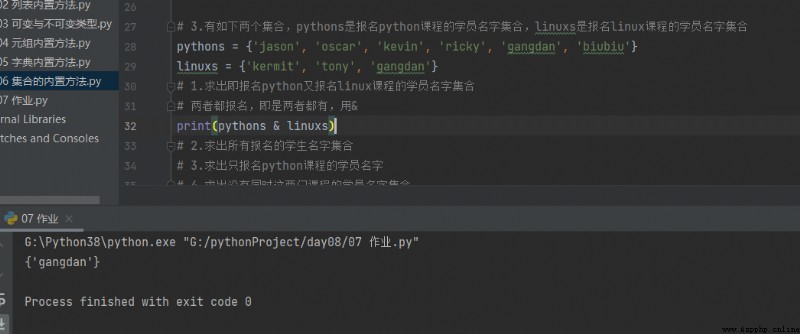
3. There are two sets ,pythons It's registration python A collection of student names for the course ,linuxs It's registration linux A collection of student names for the course
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
1. Find out and sign up python Sign up again linux A collection of student names for the course
print(pythons & linuxs)
2. Find out the name set of all registered students
print(pythons | linuxs) # {'kevin', 'gangdan', 'jason', 'biubiu', 'kermit', 'tony', 'ricky', 'oscar'}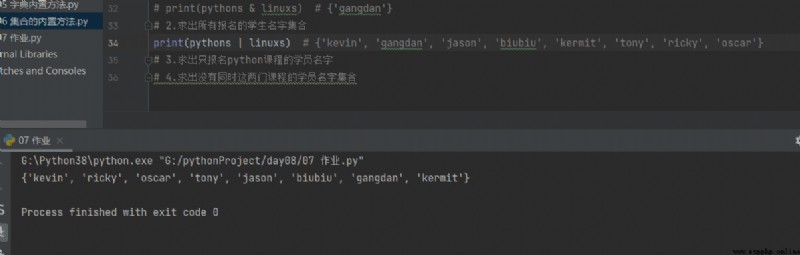
3. Only sign up python The names of the participants in the course
print(pythons - linuxs) # {'kevin', 'oscar', 'ricky', 'jason', 'biubiu'}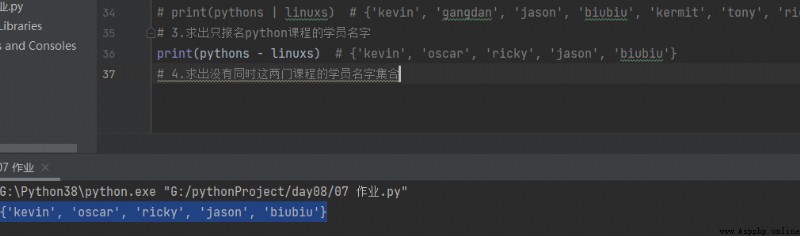
4. Find out the students' name set without the two courses at the same time
print(pythons ^ linuxs) # {'biubiu', 'tony', 'kermit', 'jason', 'ricky', 'oscar', 'kevin'}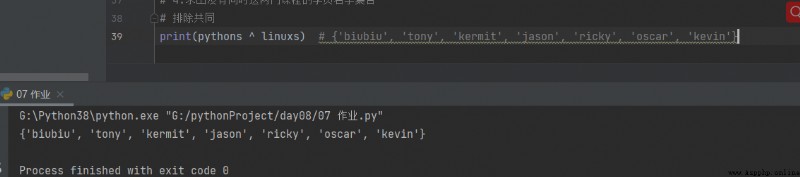
 Force deduction longest palindrome substring Python -- sometimes DFS is better than DP
Force deduction longest palindrome substring Python -- sometimes DFS is better than DP
Given first dp Code for (clock