1. brief introduction
The laida rule (Pau’ta Criteron) First, assume that a set of data contains only random errors , First, calculate the standard deviation according to certain criteria , Determine a certain interval according to a certain probability , Those not in this interval are considered as outliers . It can be used when the data is in a positive or approximate positive distribution
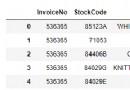
2. Sample dataset 
3. Complete processing code
import numpy as np
import pandas as pd
# Set the path of the file to be read
datapath = "traning Before processing .xlsx"
data = pd.read_excel(datapath)
# Record variance greater than 3 Times value
#shape[0] Record the number of lines ,shape[1] Number of record Columns
sigmayb = [0]*data.shape[0]
for i in range(1,data.shape[1]):
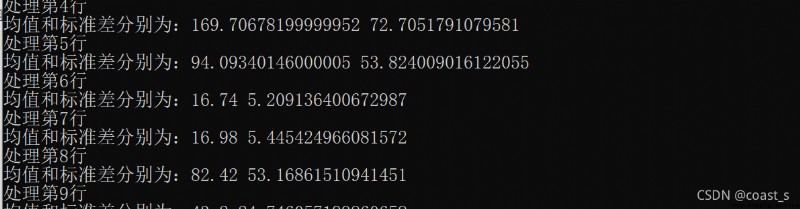
print(" To deal with the first "+str(i)+" That's ok ")
# loop Each column
lie = data.iloc[:, i].to_numpy()
#print(lie)
mea = np.mean(lie)
s = np.std(lie, ddof=1)
# Calculate each column mean value mea Standard deviation s
print(" The mean and standard deviation are respectively :"+str(mea)+" "+str(s))
# Count the rows with more than three times variance
for t in range(1,data.shape[0]):
if (abs(lie[t]-mea) > 3*s):
print(">3sigma"+" "+str(t)+" "+str(i))
# Set the outlier to null
data.iloc[t,i]=' '
# Store the processed data in the original file
data.to_excel(datapath)
4. Running results