1.圖像金字塔理論基礎
2.向下取樣函數及使用
3.向上取樣函數及使用
4.采樣可逆性研究
5.拉普拉斯金字塔
6.圖像輪廓介紹
輪廓近似

圖像金字塔是圖像多尺度表達的一種,是一種以多分辨率來解釋圖像的有效但概念簡單的結構。一幅圖像的金字塔是一系列以金字塔形狀排列的分辨率逐步降低,且來源於同一張原始圖的圖像集合。其通過梯次向下采樣獲得,直到達到某個終止條件才停止采樣。我們將一層一層的圖像比喻成金字塔,層級越高,則圖像越小,分辨率越低。
那我們為什麼要做圖像金字塔呢?這就是因為改變像素大小有時候並不會改變它的特征,比方說給你看1000萬像素的圖片,你能知道裡面有個人,給你看十萬像素的,你也能知道裡面有個人,但是對計算機而言,處理十萬像素可比處理1000萬像素要容易太多了。就是為了讓計算機識別特征這個事變得更加簡便,後期我們也會講到識別特征這個實戰項目,大概就是說比如你在高中打籃球,遠遠的看見你班主任出來了,你們離500米,你依然可以根據特征取認識出來你的老師,和你班主任離你2米的時候一樣。
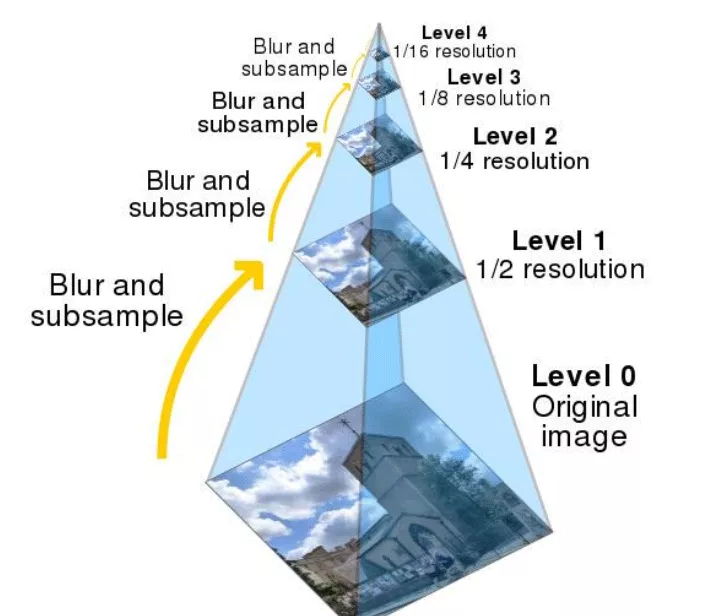
也就是說圖像金字塔式同一個圖像不同分辨率子圖的集合。在這裡我們可以舉一個例子就是原始圖像是一個400400的圖像,那麼向上取就可以是200200的一張圖像然後100*100,這樣分辨率降低,但是始終是同一個圖像。
那麼從第i層到第i+1層,他具體是怎麼做的呢?
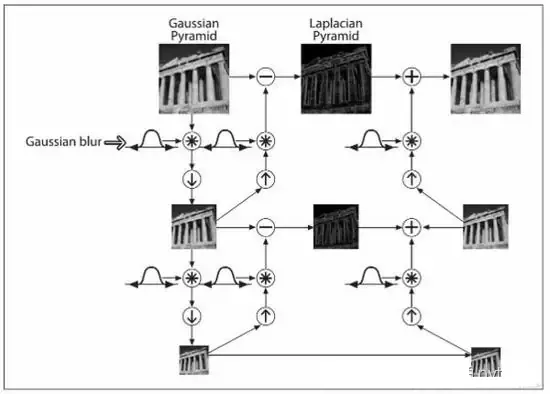
1.計算輸入圖像減少的分辨率的近似值。這可以通過對輸入進行濾波並以2為步長進行抽樣(即子抽樣)。可以采用的濾波操作有很多,如鄰域平均(可生成平均值金字塔),高斯低通濾波器(可生成高斯金字塔),或者不進行濾波,生成子抽樣金字塔。生成近似值的質量是所選濾波器的函數。沒有濾波器,在金字塔的上一層中的混淆變得很顯著,子抽樣點對所選取的區域沒有很好的代表性。
2.對上一步的輸出進行內插(因子仍為2)並進行過濾。這將生成與輸入等分辨率的預測圖像。由於在步驟1的輸出像素之間進行插值運算,所以插入濾波器決定了預測值與步驟1的輸入之間的近似程度。如果插入濾波器被忽略了,則預測值將是步驟1輸出的內插形式,復制像素的塊效應將變得很明顯。
3.計算步驟2的預測值和步驟1的輸入之間的差異。以j級預測殘差進行標識的這個差異將用於原始圖像的重建。在沒有量化差異的情況下,預測殘差金字塔可以用於生成相應的近似金字塔(包括原始圖像),而沒有誤差。
執行上述過程P次將產生密切相關的P+1級近似值和預測殘差金字塔。j-1級近似值的輸出用於提供近似值金字塔,而j級預測殘差的輸出放在預測殘差金字塔中。如果不需要預測殘差金字塔,則步驟2和3、內插器、插入濾波器以及圖中的加法器都可以省略。
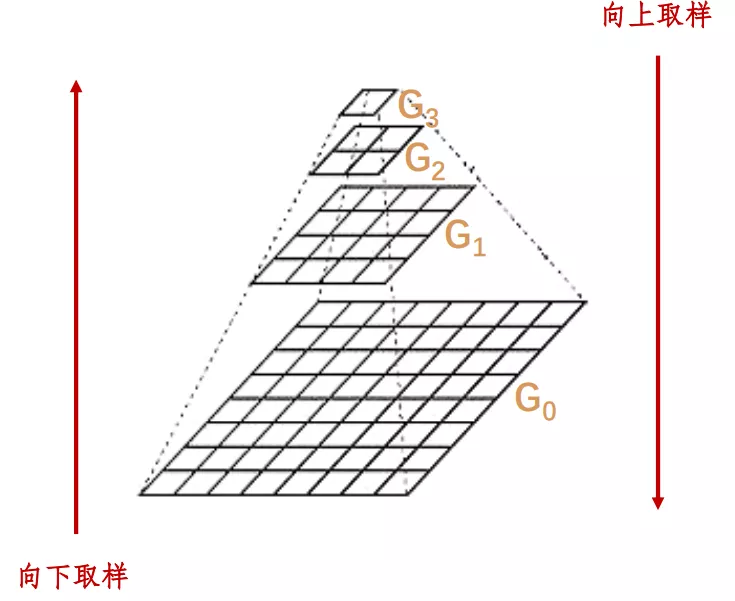
這裡面下取樣表示圖像的縮小。向上取樣表示的是圖像的增大。
1.對圖像Gi進行高斯核卷積。
高斯核卷積就是我們所說的高斯濾波操縱,我們之前就已經講過,使用一個高斯卷積核,讓臨近的像素值所占的權重較大,然後和目標圖像做相關操作。
2.刪除所有的偶數行和列。
原始圖像 M * N 處理結果 M/2 * N/2。每次處理後,結果圖像是原來的1/4。這個操作被稱為Octave。重復執行該過程,構造圖像金字塔。直至圖像不能繼續下分為止。這個過程會丟失圖像信息。
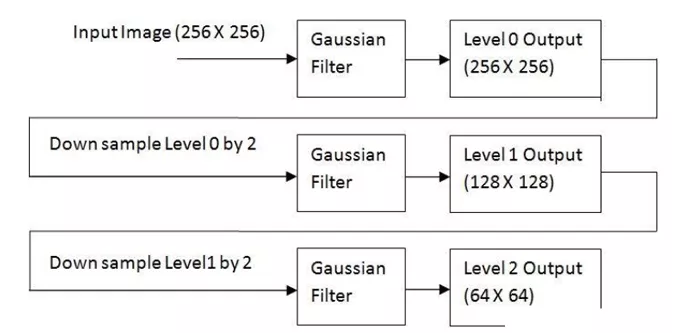
而向上取樣恰恰和向下取樣相反,是在原始圖像上,**在每個方向上擴大為原來的2倍,新增的行和列以0填充。使用與“向下采用”同樣的卷積核乘以4,獲取“新增像素”的新值。**經過向上取樣後的圖像會模糊。
向上采樣、向下采樣不是互逆操作。經過兩種操作後,無法恢復原有圖像。
圖像金字塔向下取樣函數:
dst=cv2.pyrDown(src)import cv2import numpy as npo=cv2.imread("image\\man.bmp")r1=cv2.pyrDown(o)r2=cv2.pyrDown(r1)r3=cv2.pyrDown(r2)cv2.imshow("original",o)cv2.imshow("PyrDown1",r1)cv2.imshow("PyrDown2",r2)cv2.imshow("PyrDown3",r3)cv2.waitKey()cv2.destroyAllWindows()這裡我們對圖像做三次向下取樣,結果為:

向下取樣會丟失信息!!!
3.向上取樣函數及使用圖像金字塔向上取樣函數:
dst=cv2.pyrUp(src)這裡代碼我們就不做介紹了。
直接看一下我們的結果:

這裡我們具體看一下圖像進行向下取樣然後進行向上取樣操作後,是不是一致的。還有就是圖像進行向上取樣然後向下取樣後,是不是一致的呢?這裡我們以小女孩的圖像做一下研究。
首先我們來分析一下:當圖像做向下取樣一次之後,圖像由MN變成了M/2N/2,然後再次經過向上取樣之後又變成了M*N。那麼可以證明對於圖片的size是不發生變化的。
import cv2o=cv2.imread("image\\girl.bmp")down=cv2.pyrDown(o)up=cv2.pyrUp(down)cv2.imshow("original",o)cv2.imshow("down",down)cv2.imshow("up",up)cv2.waitKey()cv2.destroyAllWindows()那麼我們來看一下到底發生了什麼變化呢?

這裡可以很清晰的看出來小女孩的照片變得模糊了,那麼是為什麼呢?因為我們上面說到了就是當圖像變小的時候,那麼就會損失一些信息,再次放大之後,由於卷積核變大了,那麼圖像會變模糊。所以不會和原始圖像保持一致。
然後我們再來看一下先進行向上取樣操作,然後進行向下取樣操作會是什麼樣子呢?由於圖像變大太大所以我們省去中間圖像向上取樣的圖片。

那麼我們用肉眼也不是特別容易發現差異,那麼我們用圖像減法去看一下。
import cv2o=cv2.imread("image\\girl.bmp")up=cv2.pyrUp(o)down=cv2.pyrDown(up)diff=down-o #構造diff圖像,查看down與o的區別cv2.imshow("difference",diff)cv2.waitKey()cv2.destroyAllWindows()
我們先來看一下拉普拉斯金字塔是一個什麼東西:
Li = Gi - PyrUp(PyrDown(Gi))
我們根據他這個式子可以知道,拉普拉斯金字塔就是使用原始圖像減去圖像向下取樣然後向上取樣的這樣一個過程。
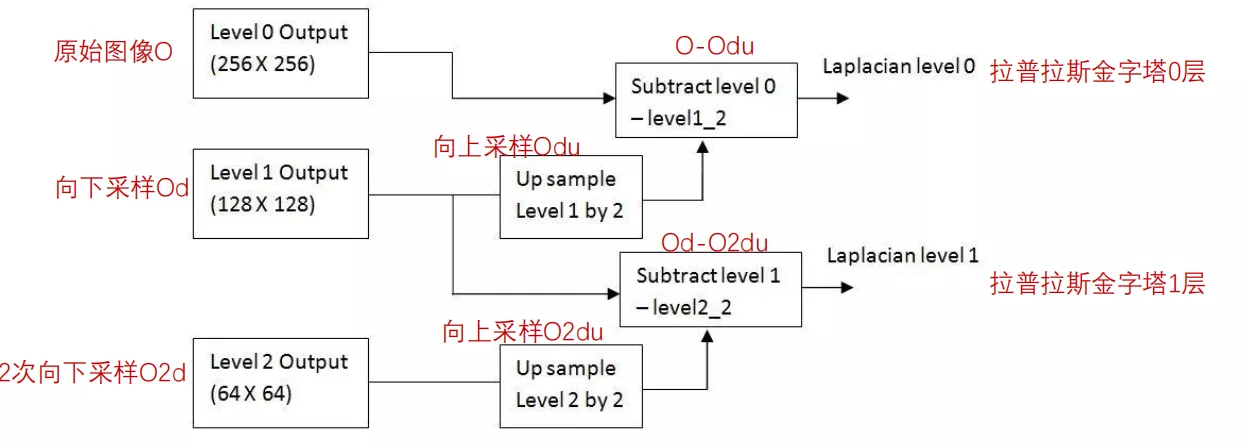
展示在圖像當中就是:
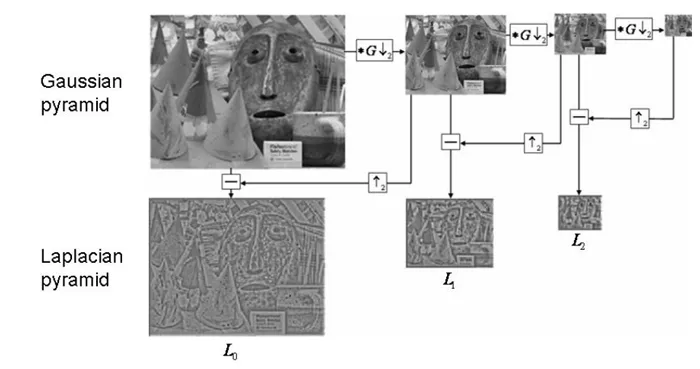
核心函數就是:
od=cv2.pyrDown(o)odu=cv2.pyrUp(od)lapPyr=o-odu6.圖像輪廓介紹首先我們先要說明這樣一個事情就是彼圖像輪廓和圖像的邊緣是不一樣的,邊緣是零零散散的,但是輪廓是一個整體。

邊緣檢測能夠測出邊緣,但是邊緣是不連續的。將邊緣連接為一個整體,構成輪廓。
注意:
對象是二值圖像。所以需要預先進行阈值分割或者邊緣檢測處理。查找輪廓需要更改原始圖像。因此,通常使用原始圖像的一份拷貝操作。在OpenCV中,是從黑色背景中查找白色對象。因此,對象必須是白色的,背景必須是黑色的。
對於圖像輪廓的檢測需要的函數是:
cv2.findContours( )和cv2.drawContours( )
查找圖像輪廓的函數是cv2.findContours(),通過cv2.drawContours()將查找到的輪廓繪制到圖像上。
對於cv2.findContours( )函數:
image, contours, hierarchy = cv2.findContours( image, mode, method)
這裡需要注意在最新的版本中,查找輪廓中的返回函數只有兩個即可:
contours, hierarchy = cv2.findContours( image, mode, method)
contours ,輪廓
hierarchy ,圖像的拓撲信息(輪廓層次)
image ,原始圖像
mode ,輪廓檢索模式
method ,輪廓的近似方法
這裡我們需要介紹mode:也就是輪廓檢索模式:
cv2.RETR_EXTERNAL :表示只檢測外輪廓
cv2.RETR_LIST :檢測的輪廓不建立等級關系
cv2.RETR_CCOMP :建立兩個等級的輪廓,上面的一層為外邊界,裡面的一層為內孔的邊 界信息。如果內孔內還有一
個連通物體,這個物體的邊界也在頂層
cv2.RETR_TREE :建立一個等級樹結構的輪廓。
然後我們介紹一下method ,輪廓的近似方法:
cv2.CHAIN_APPROX_NONE :存儲所有的輪廓點,相鄰的兩個點的像素位置差不超過1, 即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE:壓縮水平方向,垂直方向,對角線方向的元素, 只保留該方向的終點坐標,例如一個矩形輪廓只需4個點來保存輪廓信息
cv2.CHAIN_APPROX_TC89_L1:使用teh-Chinl chain 近似算法
cv2.CHAIN_APPROX_TC89_KCOS:使用teh-Chinl chain 近似算法
比如對一個矩形做輪廓檢測,使用cv2.CHAIN_APPROX_NONE和cv2.CHAIN_APPROX_SIMPLE得結果是這樣:
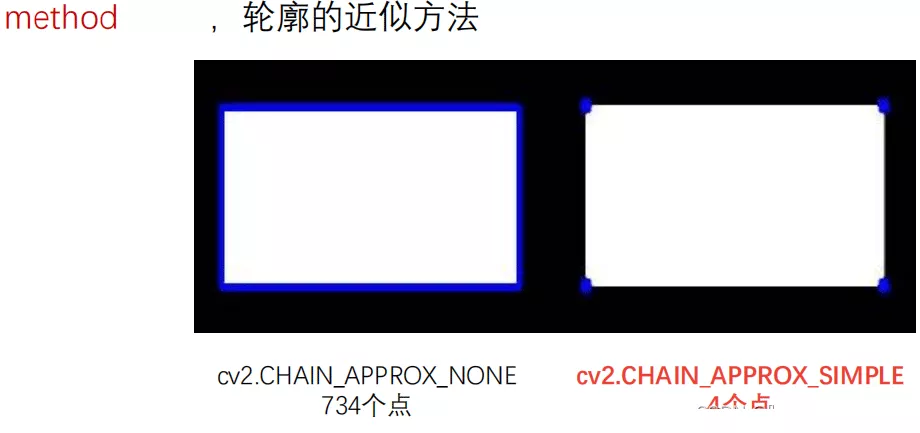
可以看出後者省出來很多計算空間。
對於cv2.drawContours( ):
r=cv2.drawContours(o, contours, contourIdx, color[, thickness])
r :目標圖像,直接修改目標的像素點,實現繪制。
o :原始圖像
contours :需要繪制的邊緣數組。
contourIdx :需要繪制的邊緣索引,如果全部繪制則為 -1。
color :繪制的顏色,為 BGR 格式的 Scalar 。
thickness :可選,繪制的密度,即描繪輪廓時所用的畫筆粗細。
import cv2import numpy as npo = cv2.imread('image\\boyun.png') gray = cv2.cvtColor(o,cv2.COLOR_BGR2GRAY) ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY) image,contours, hierarchy =cv2.findContours(binary,cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) co=o.copy()r=cv2.drawContours(co,contours,-1,(0,0,255),1) cv2.imshow("original",o)cv2.imshow("result",r)cv2.waitKey()cv2.destroyAllWindows()
對於多個輪廓,我們也可以指定畫哪一個輪廓。
gray = cv2.cvtColor(o,cv2.COLOR_BGR2GRAY) ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY) image,contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE) co=o.copy()r=cv2.drawContours(co,contours,0,(0,0,255),6)
如果設置成-1,那麼就是全部顯示!!!
輪廓近似當輪廓有毛刺的時候,我們希望能夠做輪廓近似,將毛刺去掉,大體思想是將曲線用直線代替,但是有個長度的阈值需要自己設定。

我們還可以做額外的操作,比如外接矩形,外接圓,外界橢圓等等。
img = cv2.imread('contours.png')gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)cnt = contours[0]x,y,w,h = cv2.boundingRect(cnt)img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)cv_show(img,'img')area = cv2.contourArea(cnt)x, y, w, h = cv2.boundingRect(cnt)rect_area = w * hextent = float(area) / rect_areaprint ('輪廓面積與邊界矩形比',extent)外接圓(x,y),radius = cv2.minEnclosingCircle(cnt)center = (int(x),int(y))radius = int(radius)img = cv2.circle(img,center,radius,(0,255,0),2)cv_show(img,'img')模板匹配和卷積原理很像,模板在原圖像上從原點開始滑動,計算模板與(圖像被模板覆蓋的地方)的差別程度,這個差別程度的計算方法在opencv裡有六種,然後將每次計算的結果放入一個矩陣裡,作為結果輸出。假如原圖形是AXB大小,而模板是axb大小,則輸出結果的矩陣是(A-a+1)x(B-b+1)。
TM_SQDIFF:計算平方不同,計算出來的值越小,越相關
TM_CCORR:計算相關性,計算出來的值越大,越相關
TM_CCOEFF:計算相關系數,計算出來的值越大,越相關
TM_SQDIFF_NORMED:計算歸一化平方不同,計算出來的值越接近0,越相關
TM_CCORR_NORMED:計算歸一化相關性,計算出來的值越接近1,越相關
TM_CCOEFF_NORMED:計算歸一化相關系數,計算出來的值越接近1,越相關

到此這篇關於python OpenCV圖像金字塔的文章就介紹到這了,更多相關python OpenCV金字塔內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!