本文我們詳細介紹一下 Python 中現有的全部序列類型以及一些較為高級的用法。
以上這些序列中存儲的是對象的引用,因此他們不關心所引用的存儲對象的類型,也就是說,在一個序列中可以放入不同類型的對象。
上述這些序列類型存儲的是對象的值,他們是一段連續的存儲空間,只能容納一種類型。
下面的代碼把一個字符串轉換成 unicode 碼存儲在 list 中並輸出:
>>> symbols = '$¢£¥€¤'
>>> codes = []
>>> for symbol in symbols:
... codes.append(ord(symbol))
...
>>> codes
[36, 162, 163, 165, 8364, 164]下面我們將他改成列表推導的形式:
>>> symbols = '$¢£¥€¤'
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 162, 163, 165, 8364, 164]顯然,列表推導的方法大大簡化了上述代碼,邏輯更加清晰簡練,他可以十分簡潔的實現可迭代類型的元素過濾或加工,並創建出一個新列表。
列表推導中我們是可以放入多個循環的,例如下面這個生成笛卡爾積的例子:
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> tshirts = [(color, size) for color in colors for size in sizes]
>>> tshirts
[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'),
('white', 'M'), ('white', 'L')]但需要注意的是,不要濫用列表推導:
filter 與 map 結合 lambda 表達式也可以做到和列表推導相同的功能,但可讀性大為下降。 下面的例子將 Unicode 值大於 127 的字符對應的 Unicode 值加入列表中:
>>> symbols = '$¢£¥€¤'
>>> beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
>>> beyond_ascii
[162, 163, 165, 8364, 164]上面所有例子中,我們都只生成了列表,如果我們要生成其他類型的序列,列表推導就不適用了,此時生成器表達式成為了更好的選擇。 簡單地說,把列表推導的方括號變成圓括號就是生成器表達式,但在用法上,生成器表達式通常用於生成序列作為方法的參數。 下面的例子用生成器表達式計算了一組笛卡爾積:
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes):
... print(tshirt)生成器與列表推導存在本質上的不同,生成器實際上是一種惰性實現,他不會一次產生整個序列,而是每次生成一個元素,這與迭代器的原理非常類似,如果列表元素非常多,使用列表生成器可以在很大程度上節約內存的開銷。
上一篇文章中,我們介紹了元組作為不可變列表的用法,但一個同樣重要的用法是把元組用作信息的記錄。
>>> city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)可以看到,上面的例子中只用一行代碼,就讓元組中的每個元素都被賦值給不同的變量,這個過程就被稱為元組拆包。
下面就是一個通過元組拆包實現的十分優雅的變量交換操作:
>>> b, a = a, b除了給變量賦值,只要可迭代對象的元素數與元組中元素數量一致,任何可迭代對象都可以用元組拆包來賦值。
可以用 * 運算符將任何一個可迭代對象拆包作為方法的參數:
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
(2, 4)Python 允許被拆包賦值的一系列變量中最多存在一個以 開始的變量,他用來接收所有拆包賦值後剩下的變量。args 用來獲取不確定參數是最經典的寫法了。
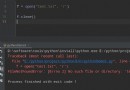
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])元組拆包是可以嵌套的,只要接受元組嵌套結構符合表達式本身的嵌套結構,Python 就可以做出正確的處理。
具名元組就是帶有名字和字段名的元組,他用元組模擬了一個簡易的類。 我們通過 collections.namedtuple 方法就可以構建一個具名元組:
>>> from collections import namedtuple
>>> City = namedtuple('City', 'name country population coordinates')
>>> tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
>>> tokyo
City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722, 139.691667))本質上,具名元組仍然是元組用於記錄元素的一種用法。
除了所有元組具有的屬性和方法,具名元組還具有下面三個有用的屬性和方法。
序列類型有很多,雖然大部分人在大部分時間都喜歡使用 list,但要知道某些時候你還有更好的選擇:
《流暢的 python》。