前主流的Tracking By Detecting方式的多目標追蹤(Multi-Object Tracking, MOT)算法主要由兩部分組成:Detection+Embedding。Detection部分即針對視頻,檢測出每一幀中的潛在目標。Embedding部分則將檢出的目標分配和更新到已有的對應軌跡上(即ReID重識別任務)。根據這兩部分實現的不同,又可以劃分為SDE系列和JDE系列算法。
對於傳統的多目標跟蹤,使用到的數據集是MOT16,MOT17這樣的數據集格式,種類有如下這幾種:
dataset/mot
|——————image_lists
|——————caltech.10k.val
|——————caltech.all
|——————caltech.train
|——————caltech.val
|——————citypersons.train
|——————citypersons.val
|——————cuhksysu.train
|——————cuhksysu.val
|——————eth.train
|——————mot16.train
|——————mot17.train
|——————prw.train
|——————prw.val
|——————Caltech
|——————Cityscapes
|——————CUHKSYSU
|——————ETHZ
|——————MOT16
|——————MOT17
|——————PRW
其中數據格式如下:
MOT17
|——————images
| └——————train
| └——————test
└——————labels_with_ids
└——————train
所有數據集的標注是以統一數據格式提供的。各個數據集中每張圖片都有相應的標注文本。給定一個圖像路徑,可以通過將字符串images替換為labels_with_ids並將.jpg替換為.txt來生成標注文本路徑。在標注文本中,每行都描述一個邊界框,格式如下:
[class] [identity] [x_center] [y_center] [width] [height]
注意:
class為類別id,支持單類別和多類別,從0開始計,單類別即為0。identity是從1到num_identities的整數(num_identities是數據集中所有視頻或圖片序列的不同物體實例的總數),如果此框沒有identity標注,則為-1。[x_center] [y_center] [width] [height]是中心點坐標和寬高,注意他們的值是由圖片的寬度/高度標准化的,因此它們是從0到1的浮點數。這種數據從格式來看,似乎與目標檢測yolov格式相似,但其中的圖像,不是單一的場景下的一張圖片,而是一段連續視頻幀下,截取連續幾幀的圖片。
相對自定義數據集來說,做目標跟蹤的數據標注成本要大很多,因此本文介紹一種分二階段實現多目標跟蹤的方法,
分為目標檢測和目標跟蹤二步完成
完成多目標跟蹤,首先就是訓練一個目標檢測的模型,基於單幀檢測的目標,使用算法,來判斷其他幀檢測的對象是否為同一物體,進而實現持續的視頻跟蹤。
目標檢測模型使用cv2.dnn來加載這個模型,cv2.dnn可以加載多個類型的模型(格式),具體cv2.dnn模塊說明參考下面這個鏈接:
Opencv.dnn加載模型
這裡以PaddleDetection的模型為列,將模型轉為onnx
1.首先是下載必要的文件和框架。
git clone https://github.com.cnpmjs.org/PaddlePaddle/PaddleDetection --depth 1
cd PaddleDetection
python setup.py install
pip install pycocotools paddle2onnx onnxruntime onnx
快速目標檢測,主要用到這幾個文件: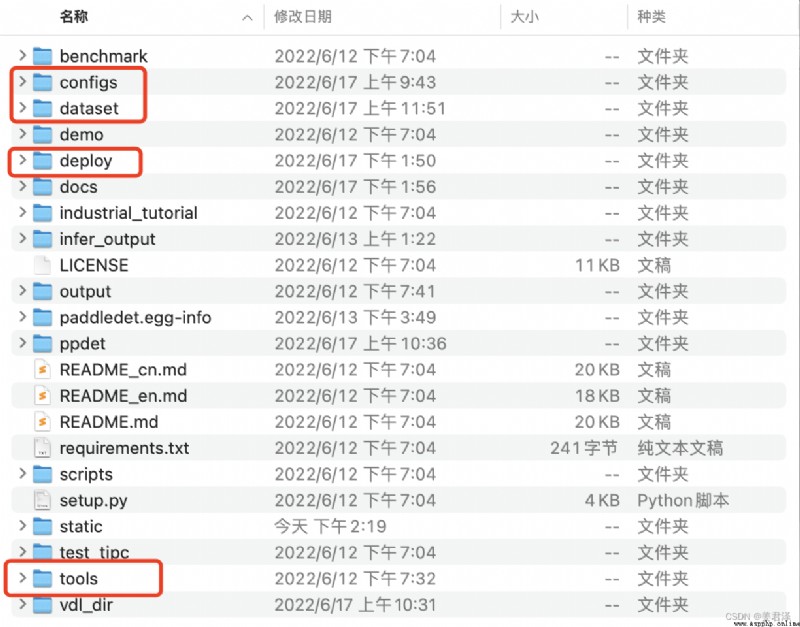
以yolov3_mobilenet_v3_large_270e_voc為例:
首先到configs找到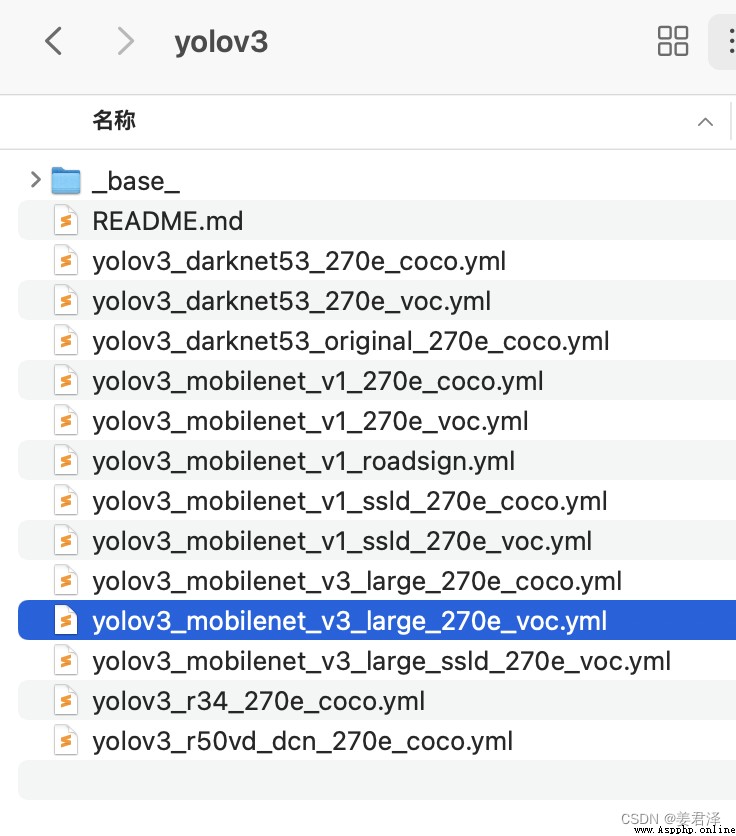
只需要修改紅色框這個數據參數: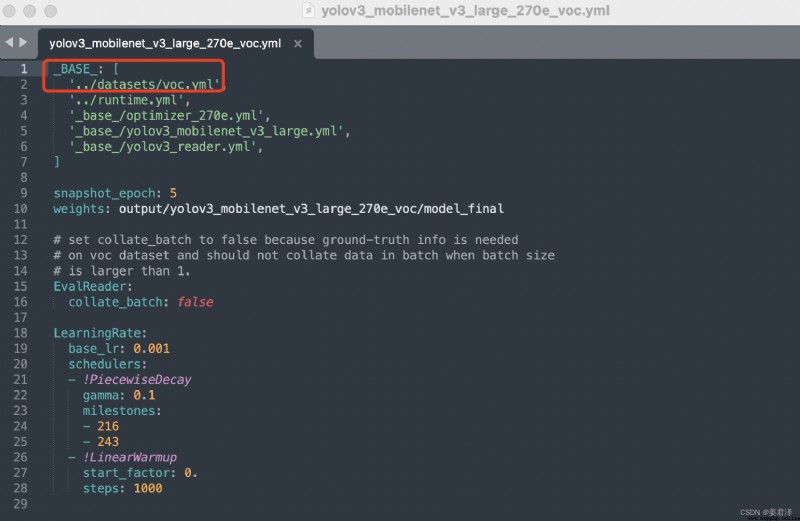 voc.yml參數需要修改的部分如下;
voc.yml參數需要修改的部分如下;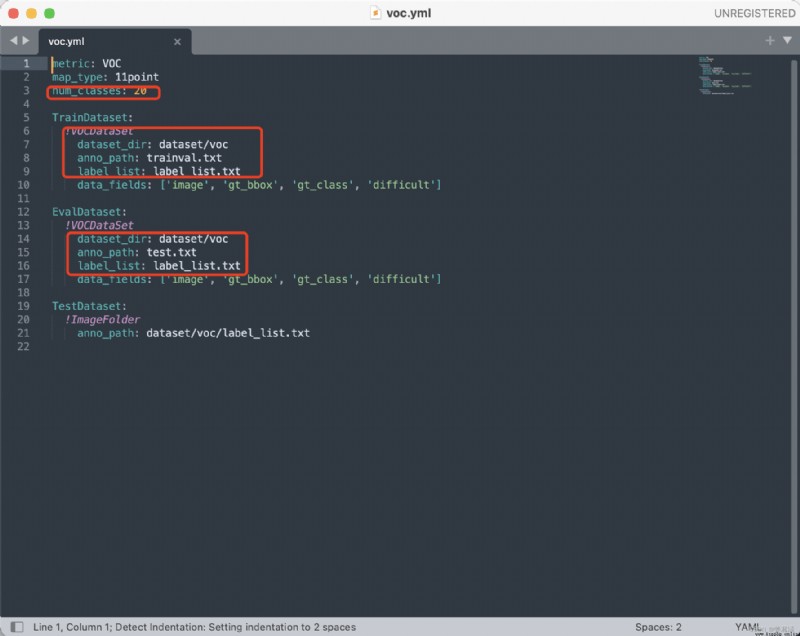
自己的分類類別數,以及數據集路徑,需要將自己定義的數據集轉換成合適的格式,比如這裡的voc格式。
訓練
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml --eval -o use_gpu=true --use_vdl=True --vdl_log_dir=vdl_dir/scalar
use_gpu:是否使用GPU
vdl_log_dir:訓練loss可視化配置
如果需要切換GPU,在tools/train.py增加二行代碼: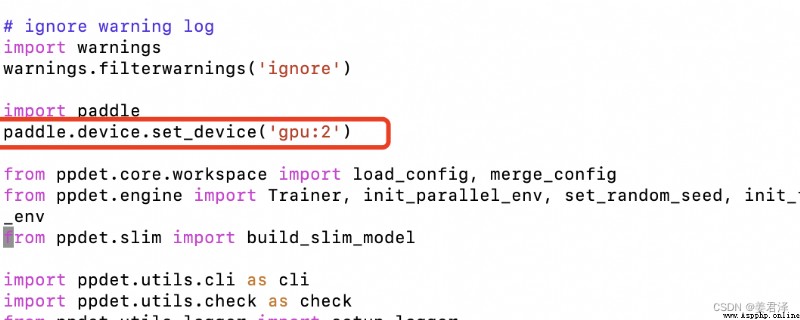
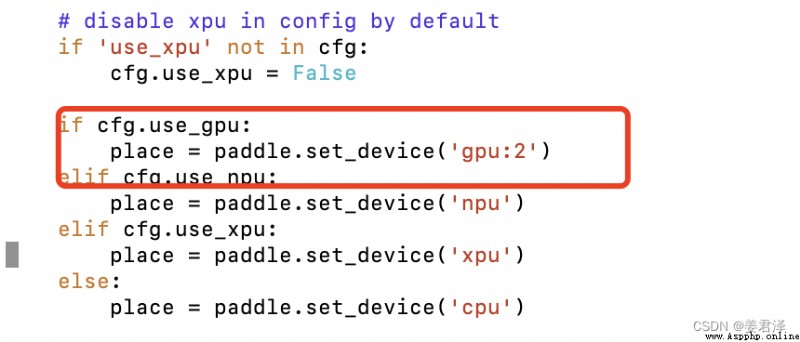
輸入下面這個命令就可以查看自己訓練可視化結果了
visualdl --logdir ./log --port 8080
得到模型參數與優化器參數在PaddleDetection/output裡,前綴model_final為最好的模型結果
python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o use_gpu=true weights=output/yolov3_mobilenet_v3_large_270e_voc/model_final.pdparams
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_270e_voc/model_final.pdparams --infer_img=demo/1.jpg
python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
導出的模型在PaddleDetection/output_inference裡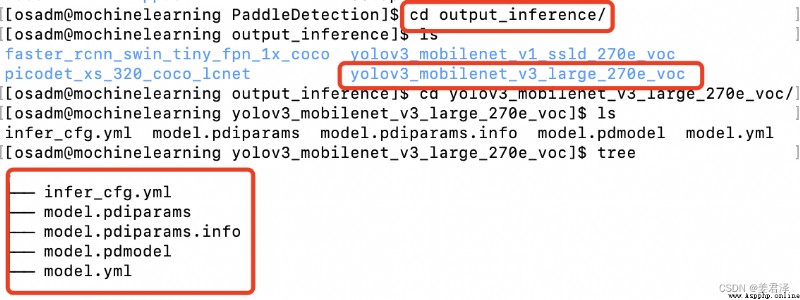
首先就是訓練一個目標檢測的模型
用cv2.dnn加載這個模型,要知道cv2.dnn可以加載那些類型的模型(格式)
這裡以PaddleDetection模型為列,將模型轉為onnx
Detection注意:因為現在升級到2.0後,使用export.py導出的也會是叫model.pdmodel和model.pdiparams,
只有使用export.py導出的模型才是預測模型(只包含前向計算),可以被paddle2onnx導出。使用訓練生成的model.pdmodel和
model.pdiparams是不可以被paddle2onnx導出的。
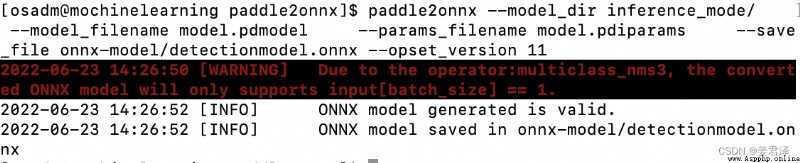
paddle2onnx --model_dir saved_inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file model.onnx \
--enable_dev_version True
# check by ONNX
import onnx
# onnx_file = save_path + '.onnx'
# onnx_file ='onnx-model/detectionmodel.onnx'
save_path = 'onnx-model/'
onnx_file = save_path + 'detectionmodel.onnx'
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)
print('The model is checked!')
def loadcv2dnnNetONNX(onnx_path):
net = cv2.dnn.readNetFromONNX(onnx_path)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
print('load successful')
return net