Pre mainstream Tracking By Detecting Multi-target tracking by means of (Multi-Object Tracking, MOT) The algorithm consists of two parts :Detection+Embedding.Detection Part for video , Detect potential targets in each frame .Embedding The other part assigns and updates the detected targets to the existing corresponding tracks ( namely ReID Re identifying tasks ). According to the implementation of these two parts , And we can divide it into SDE Series and JDE Series algorithm .
For traditional multi-target tracking , The data set used is MOT16,MOT17 Such a data set format , The types are as follows :
dataset/mot
|——————image_lists
|——————caltech.10k.val
|——————caltech.all
|——————caltech.train
|——————caltech.val
|——————citypersons.train
|——————citypersons.val
|——————cuhksysu.train
|——————cuhksysu.val
|——————eth.train
|——————mot16.train
|——————mot17.train
|——————prw.train
|——————prw.val
|——————Caltech
|——————Cityscapes
|——————CUHKSYSU
|——————ETHZ
|——————MOT16
|——————MOT17
|——————PRW
The data format is as follows :
MOT17
|——————images
| └——————train
| └——————test
└——————labels_with_ids
└——————train
The annotation of all data sets is provided in a unified data format . Each picture in each data set has corresponding annotation text . Given an image path , You can use the string images Replace with labels_with_ids And will .jpg Replace with .txt To generate annotation text path . In dimension text , Each line describes a bounding box , The format is as follows :
[class] [identity] [x_center] [y_center] [width] [height]
Be careful :
class For the category id, Support single category and multi category , from 0 Starting meter , The single category is 0.identity It's from 1 To num_identities The integer of (num_identities Is the total number of different object instances of all video or picture sequences in the dataset ), If this box does not have identity mark , Then for -1.[x_center] [y_center] [width] [height] Are the coordinates of the center point and the width and height , Note that their values are determined by the width of the image / Highly standardized , So they are from 0 To 1 Floating point number .From the format of this data , Seems to be related to target detection yolov The format is similar , But the image , It's not a picture of a single scene , It's a continuous video frame , Capture consecutive frames of pictures .
Relative to custom datasets , The cost of data annotation for target tracking is much higher , Therefore, this paper introduces a two-stage multi-target tracking method ,
It is divided into two steps: target detection and target tracking
Complete multi-target tracking , The first is to train a target detection model , Target detection based on single frame , Usage algorithm , To determine whether the object detected in other frames is the same object , So as to realize continuous video tracking .
The target detection model uses cv2.dnn To load the model ,cv2.dnn You can load multiple types of models ( Format ), Specifically cv2.dnn Refer to the following link for module description :
Opencv.dnn Load model
Here we use PaddleDetection The model of is column , Turn the model into onnx
1. The first step is to download the necessary files and frameworks .
git clone https://github.com.cnpmjs.org/PaddlePaddle/PaddleDetection --depth 1
cd PaddleDetection
python setup.py install
pip install pycocotools paddle2onnx onnxruntime onnx
Fast target detection , These files are mainly used :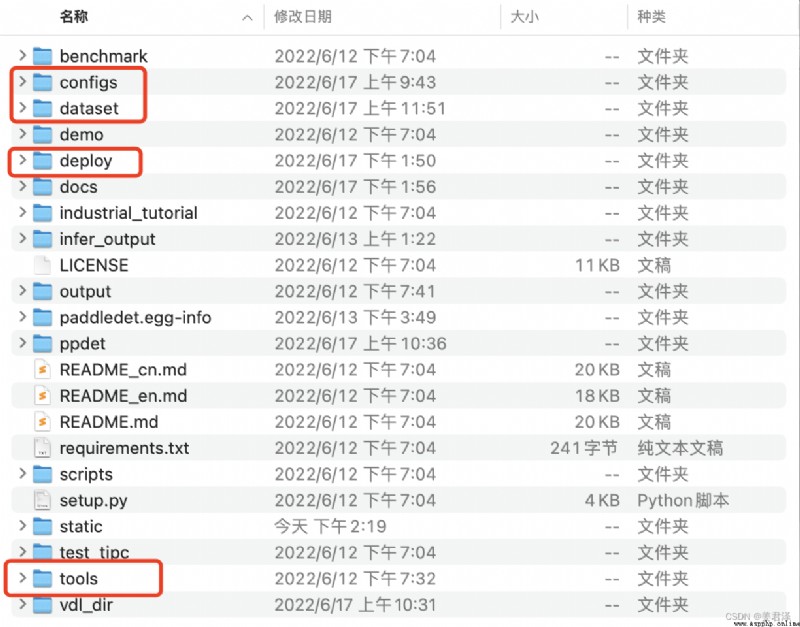
With yolov3_mobilenet_v3_large_270e_voc For example :
First of all to configs find 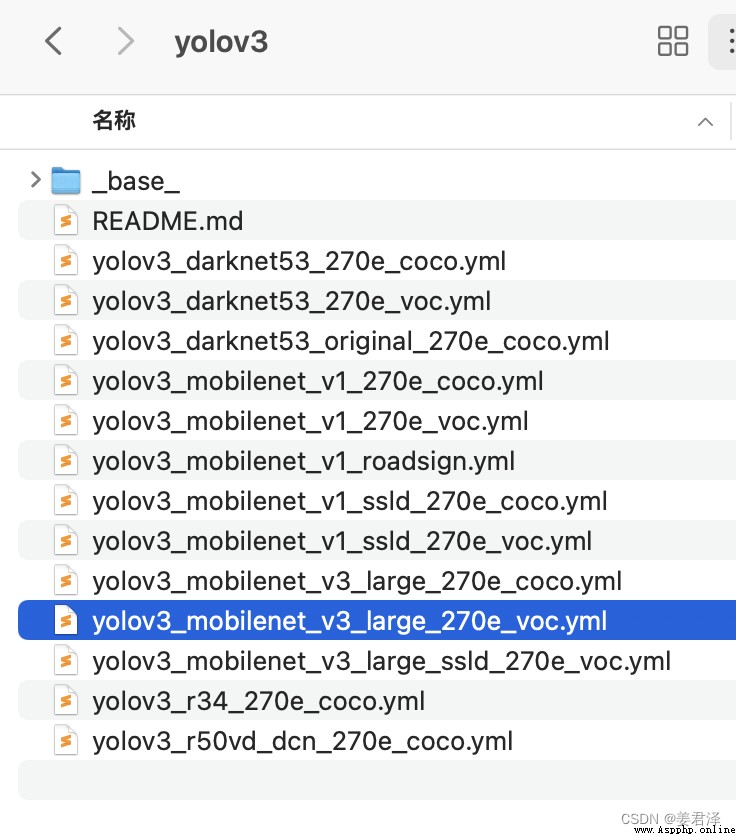
You only need to modify the data parameter of the red box :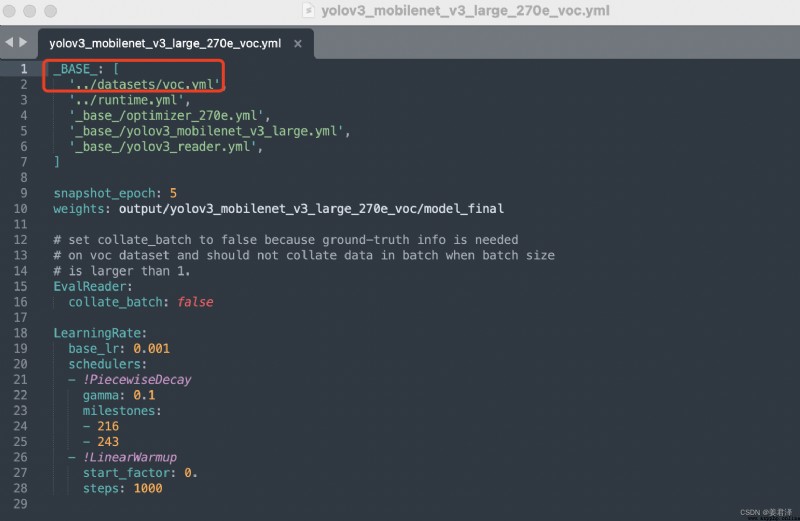 voc.yml The parameters to be modified are as follows ;
voc.yml The parameters to be modified are as follows ;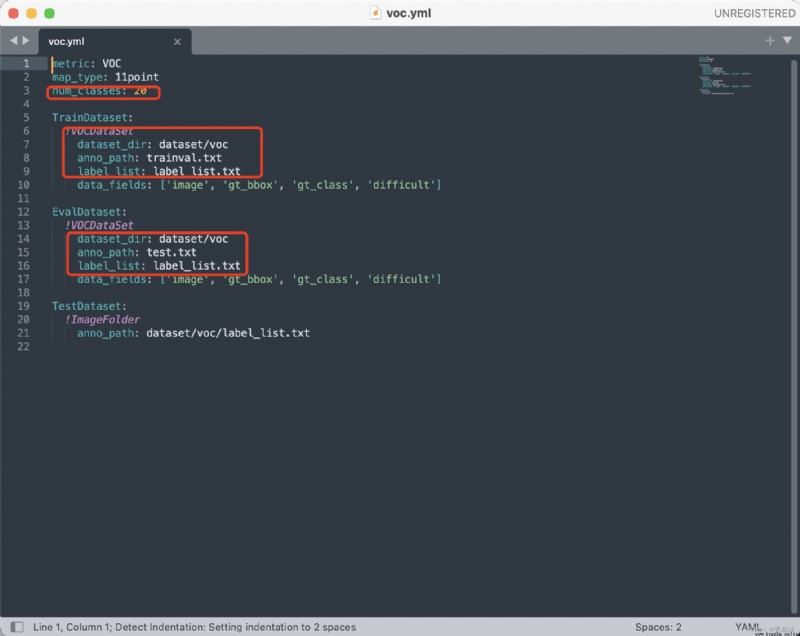
Number of your own categories , And the data set path , You need to convert your own defined data set into an appropriate format , Like here voc Format .
Training
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml --eval -o use_gpu=true --use_vdl=True --vdl_log_dir=vdl_dir/scalar
use_gpu: Whether to use GPU
vdl_log_dir: Training loss Visual configuration
If you need to switch GPU, stay tools/train.py Add two lines of code :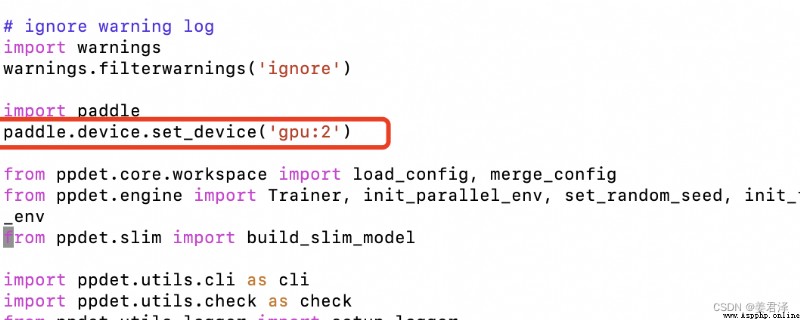
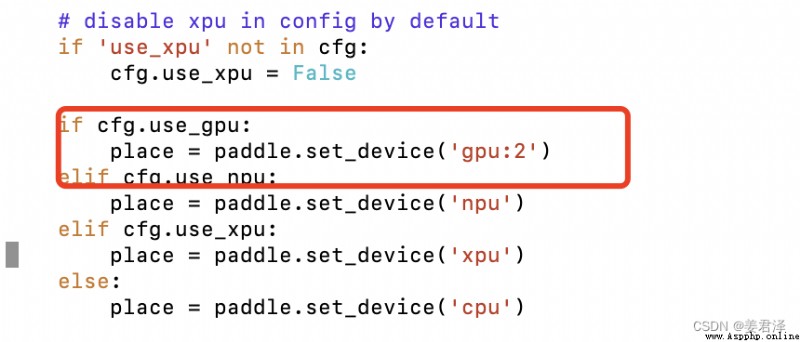
Enter the following command to view your training visualization results
visualdl --logdir ./log --port 8080
Get the model parameters and optimizer parameters in PaddleDetection/output in , Prefix model_final For the best model results
python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o use_gpu=true weights=output/yolov3_mobilenet_v3_large_270e_voc/model_final.pdparams
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_270e_voc/model_final.pdparams --infer_img=demo/1.jpg
python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
The exported model is in PaddleDetection/output_inference in 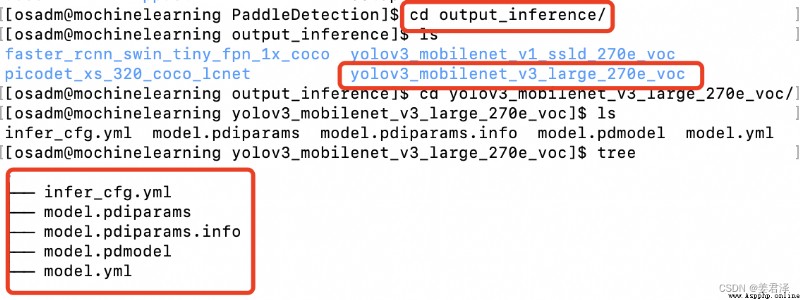
The first is to train a target detection model
use cv2.dnn Load this model , Need to know cv2.dnn You can load those types of models ( Format )
Here we use PaddleDetection Model as column , Turn the model into onnx
Detection Be careful : Because now upgrade to 2.0 after , Use export.py The exported will also be called model.pdmodel and model.pdiparams,
Only use export.py The exported model is the prediction model ( Only forward calculation is included ), Can be paddle2onnx export . Use training generated model.pdmodel and
model.pdiparams Can not be paddle2onnx Derived .
paddle2onnx --model_dir saved_inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file model.onnx \
--enable_dev_version True
# check by ONNX
import onnx
# onnx_file = save_path + '.onnx'
# onnx_file ='onnx-model/detectionmodel.onnx'
save_path = 'onnx-model/'
onnx_file = save_path + 'detectionmodel.onnx'
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)
print('The model is checked!')
def loadcv2dnnNetONNX(onnx_path):
net = cv2.dnn.readNetFromONNX(onnx_path)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
print('load successful')
return net