「 This is my participation 2022 For the first time, the third challenge is 16 God , Check out the activity details :2022 For the first time, it's a challenge 」.
We talked about how to deal with duplicate values , Today, let's talk about missing values . The missing values are mainly divided into mechanical reasons and human reasons . The mechanical reason is that the memory is broken , Failure to collect data for a certain period of time due to machine failure, etc . There are more types of human causes , Such as deliberate concealment .
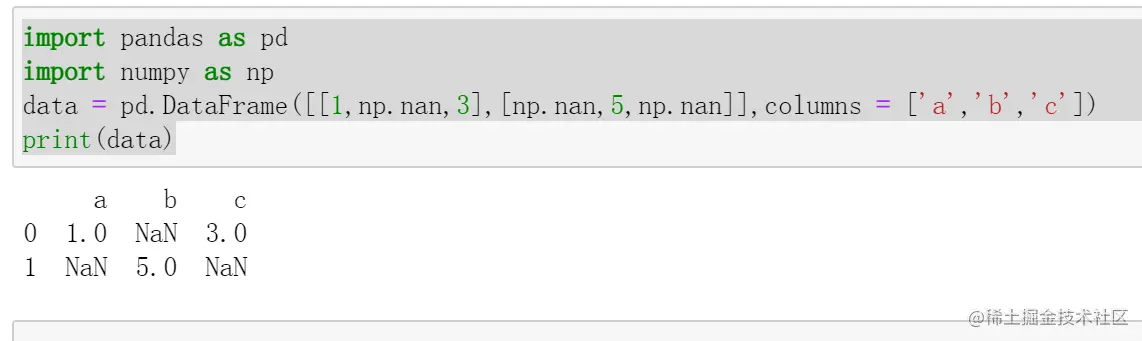
First build a with missing values DataFrame, as follows :
import pandas as pd
import numpy as np
data = pd.DataFrame([[1,np.nan,3],[np.nan,5,np.nan]],columns = ['a','b','c'])
print(data)
Copy code See that ?np.nan Namely NAN value , Meaning of null value .
stay numpy There is a function in to view null values , incorrect , Are the two ,isnull() and isna() These two functions . Let's try their effects separately :
import pandas as pd
import numpy as np
data = pd.DataFrame([[1,np.nan,3],[np.nan,5,np.nan]],columns = ['a','b','c'])
data.isnull()
data.isna()
Copy code It can be seen that , These two functions are used to judge whether the data is null , If it is , Just go back to true, No, it is. false.

Usually , There are two ways to handle null values , One is to delete null values , The other is to fill it in , Let's start with the first one , Delete null , We can dropna() This function deletes null values . it is to be noted that , It will delete the entire line with null values . for example :
import pandas as pd
import numpy as np
data = pd.DataFrame([[1,np.nan,3],[np.nan,5,np.nan]],columns = ['a','b','c'])
data.dropna()
Copy code The example above uses drop After the function , Nothing ! 
We can set when each line of blank value is redundant 2 Delete after ( lower than 2 A reservation ), It's time to use dropna() Parameters of thresh.
There are many ways to add null values , Useful mean complements , Median supplement, etc , We need to use fillna() This function . for example , We use the mean to fill in the above data, The code is as follows :
import pandas as pd
import numpy as np
data = pd.DataFrame([[1,np.nan,3],[np.nan,5,np.nan]],columns = ['a','b','c'])
data.fillna(data.mean())
Copy code The result of running the code is as follows , You can see that the null values are filled with the mean values of the corresponding columns .