對於Redis的相應原理以及知識點對應的java版本,可看我之前的文章:(其知識點都是互通的)
Redis框架從入門到學精(全)
對於以上的前置知識如果了解了更好,如果不了解,就當是一種數據庫,上手也很快。
本身Redis就是一種可持久的Key-Value的數據庫,有豐富的數據結構等
通過pip install redis進行安裝導入redis的模塊包即可
如果在安裝以及使用的過程中遇到這些bug
可看我之前的文章:
本身就是一種數據庫,操作數據庫第一就是連接Redis,本身有兩個類可以連接,官方提供了Redis(StrictRedis的子類)以及StrictRedis。
連接也有兩種方式:
第一種方式是正常連接:
# 導入redis的包
import redis
# 通過redis連接用戶名、端口、密碼以及db數據庫
redis_conn = redis.Redis(host='127.0.0.1', port= 6379, password= '?', db= 0,decode_responses=True)
redis_conn = redis.StrictRedis(host='127.0.0.1', port= 6379, password= '?', db= 0,decode_responses=True)
關於以上的連接參數中:
decode_responses=True輸出的時候變為字符串,默認輸出是字節(decode_responses可不用)
連接方式的第二種是:(使用連接池)
連接池的好處是通過連接池來管理其所有的連接,避免對建立釋放連接等開銷
import redis
redis_pool = redis.ConnectionPool(host='127.0.0.1', port= 6379, password= '?', db= 0)
# 通過調用連接池
redis_conn = redis.Redis(connection_pool= redis_pool)
在基本類型中介紹其方法的使用
正常連接之後 大部分都可通過如下查看其共性的東西:
通過set設置鍵值對:redis.set('manong',18)
獲取鍵值:redis.get('manong')
判斷鍵值是否存在:redis.exists('manong')
查看鍵值的類型:redis.type('manong')
獲取當前數據庫中鍵值對數目:redis.dbsize()
以及其他的函數,可參照官網進行學習
基本的使用類型以及方法會用即可
其實Sting類在上面的展示中已經有使用到
函數:
String還有一個特點是:可以設置自增類型(不同類型設置不同類型的自增,注意區分)
incr(name, amount=1)incrbyfloat(name, amount=1.0)對於上面各個函數的用法如下:
單個鍵值對的用法
r.set("name", "碼農研究僧")
r.get("name")
r.append("name", "大帥哥") # key後追加,不存在則不成功
""" 對於set的參數比較多,不同參數不同的延遲 """
r.setex("name", 10086, "碼農研究僧") # 10086秒後過期
# 類似
r.set("name", "碼農研究僧", ex = 10086)
r.psetex("name", 10086, "碼農研究僧") # 10086毫秒後過期
# 類似
r.set("name","碼農研究僧",px = 10086)
r.setnx("name", "碼農研究僧") # key不存在設置成功,也就是 新建 鍵值
# 類似
r.set("name", "碼農研究僧",nx=True)
r.setxx("name", "碼農研究僧") # key存在設置成功,也就是 修改 鍵值
# 類似
r.set("name", "碼農研究僧",xx=True)
多個鍵值對的用法:
r.mset({
'k1': 'v1', 'k2': 'v2'}) # 設置多個值,傳入字典
r.mget("k1", "k2") # 返回一個列表,一次取出多個值
r.getset("name", "關注我") # 設置新值,並返回之前的值
# 類似
dict = {
'k1' : 'v1',
'k2' : 'v2'
}
r.mset(dict)
范圍以及自增的用法:
r.setrange("name", 2, "開發") # 從第2個位置開始替換(0開始數),原來是碼農研究僧,替換後是碼農開發
r.getrange("name", 2, 3) # 取中間子串,為開發
r.strlen("name") # 長度,不存在為0
r.incr("name", amount=3) # 以3為自增,不存在則以3為初值,不指定amount則默認為1
r.incrbyfloat("name", amount=0.3) # 以0.3自增, 同理
r.decr("name", amount=3) # 遞減同理
r.delete("name1") # 刪除
插入元素具體的使用用法:
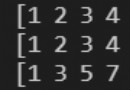
r.lpush("list1", 1,2,3) # 從左插入,通過r.lrange('list1',0,2)得到321。list1不存在會創建
r.rpush("list2", 1,2,3) # 從右插入,通過r.lrange('list2',0,2)得到123
r.lpushx("list1", 4,5) # 從左插入,通過r.lrange('list1',0,5)得到45321
r.rpushx("list1", 4,5) # 從右插入,通過r.lrange('list1',0,6)得到453216
其他的增刪改查的一些指標:(查看最後的值,通過r.lrange('list4',0,-1) ).
python的輸出格式有多種:可通過如下format格式print("list4:{}".format(r.lrange('list4',0,-1)))
r.lrange("list1",0,-1) # 默認是輸出全部值,返回所有列表
r.llen("list1") # 返回元素個數
r.lindex("list1", 1) # 通過下標1的取值
r.linsert("list1", "before", 5,3) # 5之前插入3,本身值為453216,最後為4353216
r.lset("list1", 2, 6) # 修改第2個元素為6,最後值為456216
r.rpush("list4", 2,2,1,2,3,4,5,6,1,1) # 從右插入,通過r.lrange('list4',0,-1)得到1212345611
r.lrem("list4", 1, 2) # 刪除左邊的第一個2
r.lrem("list4", -1, 1) # 刪除右邊的第一個1,負數為從後往前
r.lrem("list4", 0, 1) # 刪除所有的1
r.lpop("list4") # 刪除左邊第一個值並返回刪除值
r.rpop("list4") # 刪除右邊第一個值並返回刪除值
r.ltrim("list4", 2, 3) # 除了下標2到3的元素,其他都被刪除
自增以及分片的函數
主要為了防止多次取值,撐爆內存
具體的思想通過
在應用場景中比較常用,所以單獨放在一個表格中:
具體操作如下:
r.hset("names", "manong", "yanjiuseng") # 設置鍵值對
r.hmset("names", {
"manong": "yanjiuseng", ....}) # 設置多個鍵值對,redis4.0版本前
r.hset("names", mapping={
"manong": "yanjiuseng", ...}) # 設置多個鍵值對,redis4.0版本後
r.hget("names", "manong") # 取出key中對應的value值,返回其value值
r.hmget("names", ["manong", "age"]) # 取出多個key中對應的value值,返回其value值
r.hgetall("names") # 取出多有的鍵值對(字典)
r.hkeys("names") # 取出所有key(列表)
r.hvals("names") # 取出所有value(列表)
hlen("names") # 獲取鍵值對個數
r.hexists("names", "ma") # 查看是否存在這個key
r.hincrby("names", "age", amount=1)
# 自增1,age本身這個就沒設置,則以amount為初始,也可為負數
分片讀取的具體操作:
cursor1, data1 = r.hscan('names', cursor=0, match=None, count=None)
cursor2, data2 = r.hscan('names', cursor=cursor1, match=None, count=None)
r.hscan_iter("names", match=None, count=None) # 取出所有key,注意這裡要用遍歷,將其值進行遍歷出來
# 具體如下
for item in r.hscan_iter('xx'):
print item
set元素本身是無序不可重復
新增元素以及查詢等操作:
r.sadd("names", "ma", "nong", "yan", "jiu", "seng") # 返回集合長度個數5
r.sismember("names", "ma") # 查詢 ma 元素是否存在,返回false或者true操作
r.scard("names") # 獲取集合元素個數
# 補充測試輸出的時候,可以通過如下:
print('集合元素個數:{}'.format(r.scard("names")))
r.smembers("names") # 返回所有集合元素
r.sscan('names') #返回集合的所有元素(以元祖形式展示)
r.scan_iter("names") # 返回集合所有元素(需要通過遍歷的形式輸出)
# 例如
for i in r.sscan_iter("names"):
print(i)
差集的操作:
r.sdiff("names1", "names2") # 返回存在names1不存在names2的集合元素
r.sdiffstore("names3", "names1", "names2") # 存在names1不存在names2的集合元素,存放在names3中,並且輸出這個集合
交集的操作:
r.sinter("names1", "names2") # 返回names1和names2的交集元素
r.sinterstore("names3", "names", "names2") # 把names和names2的交集存到names3,返回names3的元素
並集的操作:
r.sunion("names1", "names2") # 返回names1和names2的並集元素
r.sunionstore("names3", "names1", "names2") # 把names和names2的並集存到names3,返回names3的元素
差集的操作:
r.spop("names") # 隨機刪除一個元素,並且將這個元素返回輸出
r.srem("names", "ma") # 刪除指定元素ma,返回已經刪除的個數
這個zset與set的區別在於
zset為有序集合,會為元素進行排序
獲取元素的key以及對應value,具體操作:
r.zadd("names", {
"ma": 1, "nong": 2, "yan": 3}) # 新增元素,而且設置對應的key以及value
r.zcard("names") # 返回有序集合個數長度
r.zrange("names", 0, -1) # 取出集合names中所有元素的key
r.zrange("names", 0, -1, withscores=True) # 取出集合names中所有元素 正序 排序,有key以及value
r.zrevrange("names", 0, -1, withscores=True) # 同上,倒序操作
r.zrangebyscore("names", 1, 3, withscores=True) # 取出集合中的value范圍在1-3之間的,value按照從小到大輸出對應的key以及value
r.zrevrangebyscore("names", 1, 3, withscores=True) # 同上,從大到小的輸出
r.zscan("names") # 取出所有有序集合的元素
r.zscan_iter("names") # 獲取所有元素,這是一個迭代器
#具體操作如下:
for i in r.zscan_iter("names"): # 遍歷迭代器
print(i)
計數、自增、獲取索引以及刪除等具體操作:
r.zcount("names", 1, 3) # 統計value在1-3之間的元素個數,並且返回
r.zincrby("names", 2, "ma") # 將ma的value自增2
r.zscore("names", "ma") # 返回key對應的value
r.zrank("names", "ma") # 返回元素ma的下標(從小到大排序)
r.zrerank("names", "ma") # 返回元素ma的下標(從大到小排序)
r.zrem("names", "ma") # 刪除單個key
r.zremrangebyrank("names", 0, 2) # 刪除下標在0到2間的元素
r.zremrangebyscore("names", 1, 3) # 刪除value在1-3之間的元素
結合python web開發
通過表單獲取redis的數據
通過普通連接或者連接池連接
連接成功之後獲取想要的數據傳回到表單即可
調用一般的redis函數,或者自已封裝一個連接函數
def get_redis(config):
sentinels = config.get("sentinels", "")
cluster_tag = config.get("cluster_tag", "")
if all([sentinels, cluster_tag]):
sentinel = Sentinel(sentinels, socket_timeout=5)
REDIS = sentinel.master_for(cluster_tag, socket_timeout=5)
else:
REDIS = StrictRedis(host=config.get("host", "127.0.0.1"),
port=config.get("port", 6379))
return REDIS
一般企業都會有很清晰的流水線
如果劃分了dev以及生產環境,不同的redis集群配置放不同配置
這部分是setting的公共配置
REDIS_CACHES = {
'manongyanjiuseng': {
'type': 'sentinel',
'cluster_tag': 'manongyanjiuseng_test',
'host': [
("ip", 端口號),
("https://blog.csdn.net/weixin_47872288", 端口號),
("https://blog.csdn.net/weixin_47872288", 端口號),
],
'socket_timeout': 10,
'master': 1,
'db': 3
},
# 同理如上創建
}
公共類的函數都放在common.py中
import redis
from redis.sentinel import Sentinel
from redis import StrictRedis
# 初始化一個線程池
CONNECTION_POOL = {
}
# 定義連接的參數
def get_redis_connection(server_name='default'):
# 函數內部可改變函數外部的變量,所以定義global
global CONNECTION_POOL
if not CONNECTION_POOL:
CONNECTION_POOL = _setup_redis()
pool = CONNECTION_POOL[server_name]
if settings.REDIS_CACHES[server_name].get("type") == "sentinel":
return pool
return redis.Redis(connection_pool=pool)
def _setup_redis():
for name, config in settings.REDIS_CACHES.items():
if config.get("type") == "sentinel":
sentinel = Sentinel(config['host'], socket_timeout=config['socket_timeout'])
if config.get('master'):
pool = sentinel.master_for(
config["cluster_tag"],
redis_class=redis.Redis,
socket_timeout=config['socket_timeout']
)
else:
pool = sentinel.slave_for(
config["cluster_tag"],
redis_class=redis.Redis,
socket_timeout=config['socket_timeout']
)
else:
pool = redis.ConnectionPool(
host=config['host'],
port=config['port'],
db=config['db'],
socket_timeout=1
)
CONNECTION_POOL[name] = pool
return CONNECTION_POOL
在調用連接的時候通過如下:
# manong這個值是通過form表單傳入進去的
redis = get_redis_connection(manong)