about Redis The corresponding principles and knowledge points of java edition , But look at my previous article :( Their knowledge points are interconnected )
Redis Framework from introduction to learning ( whole )
For the above pre knowledge, if you know better , If you don't understand , Think of it as a database , It's quick to get started .
In itself Redis Is a kind of durable Key-Value The database of , Rich data structures, etc
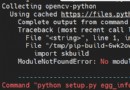
adopt pip install redis Perform installation import redis Module package of
If you encounter these problems during installation and use bug
But look at my previous article :
It is a kind of database , The first step in database operation is to connect Redis, There are two classes that can connect , The official provided Redis(StrictRedis Subclasses of ) as well as StrictRedis.
There are also two ways to connect :
The first way is to connect normally :
# Import redis My bag
import redis
# adopt redis Connection user name 、 port 、 Password and db database
redis_conn = redis.Redis(host='127.0.0.1', port= 6379, password= '?', db= 0,decode_responses=True)
redis_conn = redis.StrictRedis(host='127.0.0.1', port= 6379, password= '?', db= 0,decode_responses=True)
About the above connection parameters :
decode_responses=True When output, it becomes a string , The default output is bytes (decode_responses It's not necessary )
The second way to connect is :( Use connection pool )
The advantage of connection pooling is that it manages all its connections through connection pooling , Avoid the overhead of establishing and releasing connections
import redis
redis_pool = redis.ConnectionPool(host='127.0.0.1', port= 6379, password= '?', db= 0)
# By calling connection pool
redis_conn = redis.Redis(connection_pool= redis_pool)
Introduce the use of its methods in the basic types
After normal connection Most of them can be viewed as having something in common as follows :
adopt set Set key value pairs :redis.set('manong',18)
Get key value :redis.get('manong')
Determine whether the key value exists :redis.exists('manong')
View the type of key value :redis.type('manong')
Get the number of key value pairs in the current database :redis.dbsize()
And other functions , You can learn from the official website
Basic usage types and methods can be used
Actually Sting Class has been used in the above presentation
function :
String Another characteristic is : Auto increment type can be set ( Different types set different types of auto increment , Pay attention to distinguish between )
incr(name, amount=1)incrbyfloat(name, amount=1.0) The usage of the above functions is as follows :
Usage of single key value pairs
r.set("name", " Code farmer research monk ")
r.get("name")
r.append("name", " Big brother ") # key After adding , If it does not exist, it will not succeed
""" about set There are many parameters for , Different parameters and different delays """
r.setex("name", 10086, " Code farmer research monk ") # 10086 Seconds after expired
# similar
r.set("name", " Code farmer research monk ", ex = 10086)
r.psetex("name", 10086, " Code farmer research monk ") # 10086 Expired in milliseconds
# similar
r.set("name"," Code farmer research monk ",px = 10086)
r.setnx("name", " Code farmer research monk ") # key No, set successfully , That is to say newly build Key value
# similar
r.set("name", " Code farmer research monk ",nx=True)
r.setxx("name", " Code farmer research monk ") # key Existence set successfully , That is to say modify Key value
# similar
r.set("name", " Code farmer research monk ",xx=True)
Usage of multiple key value pairs :
r.mset({
'k1': 'v1', 'k2': 'v2'}) # Set multiple values , Pass in the dictionary
r.mget("k1", "k2") # Return a list , Take out multiple values at once
r.getset("name", " Pay attention to me ") # Set new value , And return the previous value
# similar
dict = {
'k1' : 'v1',
'k2' : 'v2'
}
r.mset(dict)
Scope and the use of autoincrement :
r.setrange("name", 2, " Development ") # From 2 Start the replacement at the next position (0 Starting number ), It turned out that it was the code farmer research monk , After the replacement, it is the code agriculture development
r.getrange("name", 2, 3) # Take the middle substring , For development
r.strlen("name") # length , There is no such thing as 0
r.incr("name", amount=3) # With 3 Is self increasing , If it doesn't exist, it will take 3 For the initial value , Don't specify amount The default is 1
r.incrbyfloat("name", amount=0.3) # With 0.3 Self increasing , Empathy
r.decr("name", amount=3) # The same goes for diminishing
r.delete("name1") # Delete
Insert the specific usage of the element :
r.lpush("list1", 1,2,3) # Insert... From the left , adopt r.lrange('list1',0,2) obtain 321.list1 Does not exist, will create
r.rpush("list2", 1,2,3) # Insert... From the right , adopt r.lrange('list2',0,2) obtain 123
r.lpushx("list1", 4,5) # Insert... From the left , adopt r.lrange('list1',0,5) obtain 45321
r.rpushx("list1", 4,5) # Insert... From the right , adopt r.lrange('list1',0,6) obtain 453216
Other indicators of addition, deletion, modification and query :( View the last value , adopt r.lrange('list4',0,-1) ).
python There are many output formats for : Through the following format Format print("list4:{}".format(r.lrange('list4',0,-1)))
r.lrange("list1",0,-1) # The default is to output all values , Return to all lists
r.llen("list1") # Number of return elements
r.lindex("list1", 1) # By subscript 1 The value of
r.linsert("list1", "before", 5,3) # 5 Insert before 3, The value itself is 453216, Finally 4353216
r.lset("list1", 2, 6) # Amendment No 2 Elements are 6, The final value is 456216
r.rpush("list4", 2,2,1,2,3,4,5,6,1,1) # Insert... From the right , adopt r.lrange('list4',0,-1) obtain 1212345611
r.lrem("list4", 1, 2) # Delete the first one on the left 2
r.lrem("list4", -1, 1) # Delete the first one on the right 1, Negative numbers are from back to front
r.lrem("list4", 0, 1) # Delete all 1
r.lpop("list4") # Delete the first value on the left and return the deleted value
r.rpop("list4") # Delete the first value on the right and return the deleted value
r.ltrim("list4", 2, 3) # Except subscript 2 To 3 The elements of , Everything else has been deleted
Self increasing and piecewise functions
Mainly to prevent multiple values , Burst memory
Specific ideas are passed through
It is commonly used in application scenarios , So put it in a separate table :
The specific operation is as follows :
r.hset("names", "manong", "yanjiuseng") # Set key value pairs
r.hmset("names", {
"manong": "yanjiuseng", ....}) # Set multiple key value pairs ,redis4.0 Before version
r.hset("names", mapping={
"manong": "yanjiuseng", ...}) # Set multiple key value pairs ,redis4.0 After version
r.hget("names", "manong") # Take out key Corresponding value value , Back to its value value
r.hmget("names", ["manong", "age"]) # Take out multiple key Corresponding value value , Back to its value value
r.hgetall("names") # Take out multiple key value pairs ( Dictionaries )
r.hkeys("names") # Remove all key( list )
r.hvals("names") # Remove all value( list )
hlen("names") # Get the number of key value pairs
r.hexists("names", "ma") # See if this... Exists key
r.hincrby("names", "age", amount=1)
# Self increasing 1,age This is not set , with amount For the initial , It can also be negative
Specific operation of fragment reading :
cursor1, data1 = r.hscan('names', cursor=0, match=None, count=None)
cursor2, data2 = r.hscan('names', cursor=cursor1, match=None, count=None)
r.hscan_iter("names", match=None, count=None) # Remove all key, Notice that we use traversal , Traverse its value
# As follows
for item in r.hscan_iter('xx'):
print item
set The element itself is unordered and unrepeatable
Add new elements and query :
r.sadd("names", "ma", "nong", "yan", "jiu", "seng") # Returns the number of set lengths 5
r.sismember("names", "ma") # Inquire about ma Whether elements exist , return false perhaps true operation
r.scard("names") # Get the number of set elements
# When supplementing the test output , It can be done by :
print(' Number of collection elements :{}'.format(r.scard("names")))
r.smembers("names") # Returns all collection elements
r.sscan('names') # Returns all elements of the collection ( Display in the form of Yuanzu )
r.scan_iter("names") # Returns all elements of the collection ( You need to output through traversal )
# for example
for i in r.sscan_iter("names"):
print(i)
Operation of difference set :
r.sdiff("names1", "names2") # Return existence names1 non-existent names2 Collection elements for
r.sdiffstore("names3", "names1", "names2") # There is names1 non-existent names2 Collection elements for , Store in names3 in , And output this set
The operation of intersection :
r.sinter("names1", "names2") # return names1 and names2 The intersection elements of
r.sinterstore("names3", "names", "names2") # hold names and names2 The intersection of is saved to names3, return names3 The elements of
Union operation :
r.sunion("names1", "names2") # return names1 and names2 Union element of
r.sunionstore("names3", "names1", "names2") # hold names and names2 Save union of to names3, return names3 The elements of
Operation of difference set :
r.spop("names") # Randomly delete an element , And return this element to the output
r.srem("names", "ma") # Deletes the specified element ma, Returns the number of deleted items
This zset And set The difference is that
zset For an orderly collection , Will sort the elements
Fetch element key And corresponding value, Specific operation :
r.zadd("names", {
"ma": 1, "nong": 2, "yan": 3}) # New elements , And set the corresponding key as well as value
r.zcard("names") # Returns the number and length of an ordered set
r.zrange("names", 0, -1) # Take out the assembly names Of all elements in key
r.zrange("names", 0, -1, withscores=True) # Take out the assembly names All elements in positive sequence Sort , Yes key as well as value
r.zrevrange("names", 0, -1, withscores=True) # ditto , Reverse order operation
r.zrangebyscore("names", 1, 3, withscores=True) # Extract from the set value The scope is 1-3 Between ,value Output the corresponding... From small to large key as well as value
r.zrevrangebyscore("names", 1, 3, withscores=True) # ditto , Output from large to small
r.zscan("names") # Take out all the elements of the ordered set
r.zscan_iter("names") # Get all the elements , This is an iterator
# The specific operation is as follows :
for i in r.zscan_iter("names"): # Ergodic iterator
print(i)
Count 、 Self increasing 、 Get the index and delete :
r.zcount("names", 1, 3) # Statistics value stay 1-3 The number of elements between , And back to
r.zincrby("names", 2, "ma") # take ma Of value Self increasing 2
r.zscore("names", "ma") # return key Corresponding value
r.zrank("names", "ma") # Returns the element ma The subscript ( Sort from small to large )
r.zrerank("names", "ma") # Returns the element ma The subscript ( Sort from large to small )
r.zrem("names", "ma") # Removing a single key
r.zremrangebyrank("names", 0, 2) # Delete subscript in 0 To 2 The elements between
r.zremrangebyscore("names", 1, 3) # Delete value stay 1-3 Between the elements
combination python web Development
Get through the form redis The data of
Connect through normal connection or connection pool
After the connection is successful, you can get the desired data and transfer it back to the form
Call the general redis function , Or encapsulate a connection function
def get_redis(config):
sentinels = config.get("sentinels", "")
cluster_tag = config.get("cluster_tag", "")
if all([sentinels, cluster_tag]):
sentinel = Sentinel(sentinels, socket_timeout=5)
REDIS = sentinel.master_for(cluster_tag, socket_timeout=5)
else:
REDIS = StrictRedis(host=config.get("host", "127.0.0.1"),
port=config.get("port", 6379))
return REDIS
General enterprises have very clear assembly lines
If divided dev And the production environment , Different redis The cluster configuration is different
This part is setting The public configuration of
REDIS_CACHES = {
'manongyanjiuseng': {
'type': 'sentinel',
'cluster_tag': 'manongyanjiuseng_test',
'host': [
("ip", Port number ),
("https://blog.csdn.net/weixin_47872288", Port number ),
("https://blog.csdn.net/weixin_47872288", Port number ),
],
'socket_timeout': 10,
'master': 1,
'db': 3
},
# In the same way, create as above
}
The functions of public classes are placed in common.py in
import redis
from redis.sentinel import Sentinel
from redis import StrictRedis
# Initialize a thread pool
CONNECTION_POOL = {
}
# Define the parameters of the connection
def get_redis_connection(server_name='default'):
# Variables inside the function can be changed outside the function , So define global
global CONNECTION_POOL
if not CONNECTION_POOL:
CONNECTION_POOL = _setup_redis()
pool = CONNECTION_POOL[server_name]
if settings.REDIS_CACHES[server_name].get("type") == "sentinel":
return pool
return redis.Redis(connection_pool=pool)
def _setup_redis():
for name, config in settings.REDIS_CACHES.items():
if config.get("type") == "sentinel":
sentinel = Sentinel(config['host'], socket_timeout=config['socket_timeout'])
if config.get('master'):
pool = sentinel.master_for(
config["cluster_tag"],
redis_class=redis.Redis,
socket_timeout=config['socket_timeout']
)
else:
pool = sentinel.slave_for(
config["cluster_tag"],
redis_class=redis.Redis,
socket_timeout=config['socket_timeout']
)
else:
pool = redis.ConnectionPool(
host=config['host'],
port=config['port'],
db=config['db'],
socket_timeout=1
)
CONNECTION_POOL[name] = pool
return CONNECTION_POOL
When calling the connection, you can use the following :
# manong This value is determined by form The form is passed in
redis = get_redis_connection(manong)