坑DIE的住建局再一次不限富豪限剛需,公布了深圳市住宅小區二手住房成交參考價格,買房更難,首付更難湊。。。
數據挖掘基礎之數據清理:用python把深圳二手房參考價PDF保存為EXCEL,以便其他分析工具可以基於此excel做統計分析和畫圖,比如tableau。
機器學習的基礎內容:數據清洗。結合實際生活場景,提升學習樂趣。
深圳住建局再一次不限富豪限剛需,公布了深圳市住宅小區二手住房成交參考價格,該價格以PDF的形式發布於官網。
我們很多分析和統計工具無法讀取pdf文件,絕大部分支持讀取excel。因此我們本次就把pdf轉化成excel供後續分析使用。
把pdf轉化成excel。
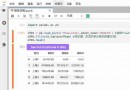
pdf的格式如下: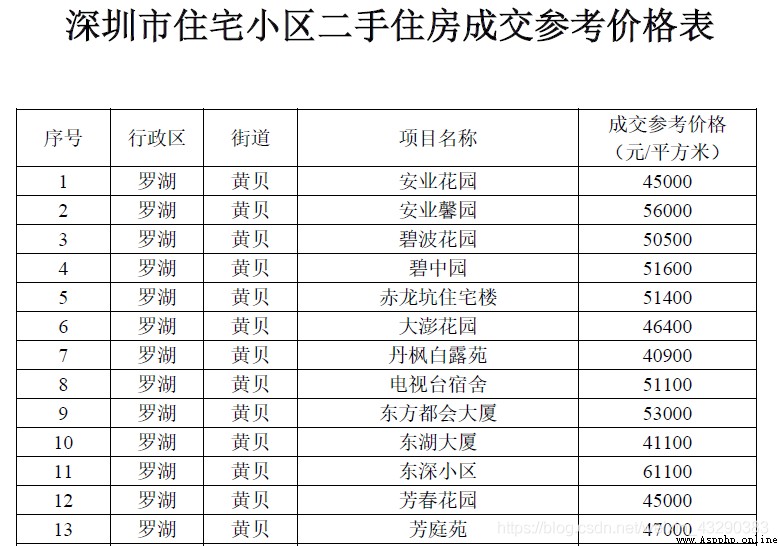
excel格式如下: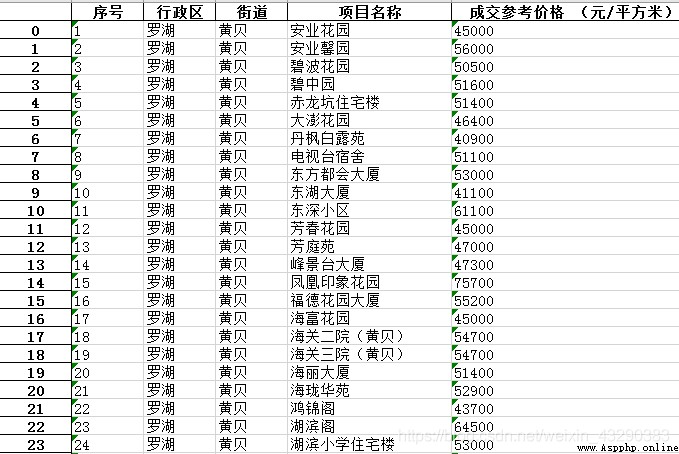
pandas 是基於NumPy 的一種工具,該工具是為了解決數據的分析問題。
pdf肯定無法被python讀取,python可以讀取txt,因此,我們先打開pdf文件,然後使用快捷鍵ctrl+A全選, 然後復制ctrl +C,新建一個txt文件,粘貼ctrl+V,就把pdf文件粘貼到了txt中,此時數據還沒有固定的格式,如下:
我們刪除表頭,剩下的數據就比較規整了,就可以用python進行讀取和處理了。我們保存編輯後的txt為:深圳參考價 python處理.txt。下載地址和提取碼:1234
代碼如下:
import pandas as pd
import numpy as np
import sys
import string
# 先把深圳二手房房價PDF拷貝到TXT中,去掉標題
# read txt method
f = open("./深圳參考價 python處理.txt")
line = f.readline()
xuhao,quyu,jiedao,xiangmumingchen,danjia = [],[],[],[],[] #定義:序號、行政區、街道、項目名稱、單價數組
i = 0 #記錄有效項目的行數
while line:
i = i + 1
print(i, line)
if line.startswith('- '): #跳過頁數的文字 ,如第17頁:- 17 -
i = i - 1
line = f.readline()
continue
line = line.replace('\n', '') #替換換行符
if i % 5 == 1:
xuhao.append(line)
elif i % 5 == 2:
quyu.append(line)
elif i % 5 == 3:
jiedao.append(line)
elif i % 5 == 4:
xiangmumingchen.append(line)
elif i % 5 == 0:
danjia.append(line)
else:
print('culculate is wrong!')
line = f.readline()
f.close()
mydict = {
'序號': xuhao, '行政區': quyu, '街道': jiedao, '項目名稱': xiangmumingchen, '成交參考價格 (元/平方米)': danjia}
df = pd.DataFrame(mydict) #轉換成datafreme,以便輸出excel
print(df)
df.to_excel('./深圳市住宅小區二手住房成交參考價格表.xlsx')
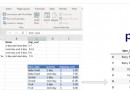
然後運行,就能得到如下的excel了:下載地址和提取碼:1234。
數據清洗是機器學習的基礎,本文僅僅簡單介紹了pandas清洗數據的使用,而pandas提供了大量能使我們快速便捷地處理數據的函數和方法。