pit DIE Once again, the housing and Urban Rural Development Bureau does not limit the rich to the just needed , The reference transaction price of second-hand housing in Shenzhen residential quarters was announced , It is more difficult to buy a house , The down payment is more difficult to collect ...
Data cleaning of data mining foundation : use python Reference price of second-hand housing in Shenzhen PDF Save as EXCEL, So that other analysis tools can be based on this excel Do statistical analysis and drawing , such as tableau.
The basic content of machine learning : Data cleaning . Combined with real life scenes , Improve the fun of learning .
Shenzhen housing and Urban Rural Development Bureau once again does not limit the rich to the just needed , The reference transaction price of second-hand housing in Shenzhen residential quarters was announced , The price is expressed in PDF Is published on the official website .
Many of our analysis and statistical tools cannot read pdf file , Most of them support reading excel. So this time we will put pdf Turn it into excel For subsequent analysis .
hold pdf Turn it into excel.
pdf The format is as follows :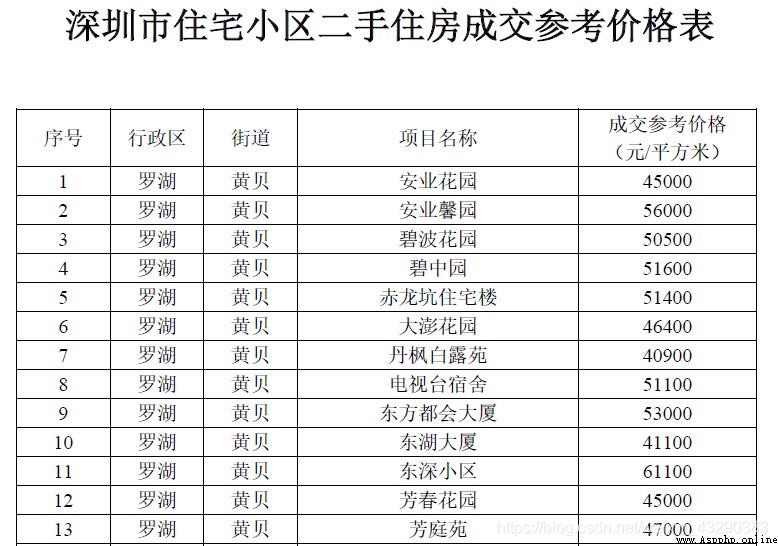
excel The format is as follows :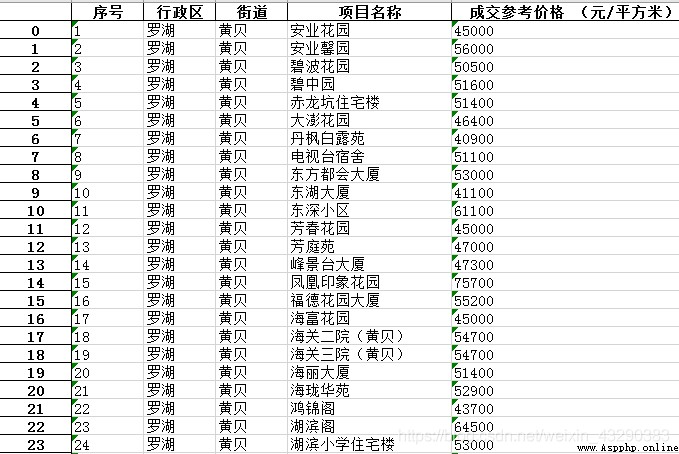
pandas Is based on NumPy A tool of , This tool is to solve the problem of data analysis .
pdf Certainly cannot be python Read ,python Can read txt, therefore , Let's open it first pdf file , Then use the shortcut key ctrl+A Future generations , And then copy it ctrl +C, Create a new one txt file , Paste ctrl+V, Just put pdf The file was pasted into txt in , At this time, the data has no fixed format , as follows :
We delete the header , The rest of the data is more regular , You can use it python Read and process . We save the edited txt by : Shenzhen reference price python Handle .txt. Download address and extraction code :1234
The code is as follows :
import pandas as pd
import numpy as np
import sys
import string
# First, the second-hand housing prices in Shenzhen PDF copy to TXT in , Remove the title
# read txt method
f = open("./ Shenzhen reference price python Handle .txt")
line = f.readline()
xuhao,quyu,jiedao,xiangmumingchen,danjia = [],[],[],[],[] # Definition : Serial number 、 Administrative region 、 The street 、 Project name 、 Unit price array
i = 0 # Number of lines recording valid items
while line:
i = i + 1
print(i, line)
if line.startswith('- '): # Skip pages of text , As the first 17 page :- 17 -
i = i - 1
line = f.readline()
continue
line = line.replace('\n', '') # Replace line breaks
if i % 5 == 1:
xuhao.append(line)
elif i % 5 == 2:
quyu.append(line)
elif i % 5 == 3:
jiedao.append(line)
elif i % 5 == 4:
xiangmumingchen.append(line)
elif i % 5 == 0:
danjia.append(line)
else:
print('culculate is wrong!')
line = f.readline()
f.close()
mydict = {
' Serial number ': xuhao, ' Administrative region ': quyu, ' The street ': jiedao, ' Project name ': xiangmumingchen, ' Transaction reference price ( element / Square meters )': danjia}
df = pd.DataFrame(mydict) # convert to datafreme, In order to output excel
print(df)
df.to_excel('./ Shenzhen residential district second-hand housing transaction reference price list .xlsx')
And then run , You can get the following excel 了 : Download address and extraction code :1234.
Data cleaning is the foundation of machine learning , This article only briefly introduces pandas Use of cleaning data , and pandas Provides a large number of functions and methods that enable us to process data quickly and conveniently .