在你學習爬蟲的知識過程中是否遇到下面的類型。如果有興趣學習一下或者了解相關知識的,且不嫌在下才疏學淺,可以參考一下。歡迎各位網友的指正。
你可能會在請求參數中看到如下亂碼的行為:
接著你會發現content-type數據類型為x-protobuf類型,那麼可能你可能需要學習一下protobuf協議才能繼續你的爬蟲。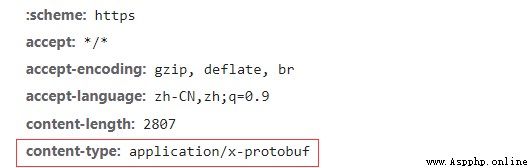
我不知道這樣說下是否正確,僅供參考吧,可以提供一種思路。先說一個正常數據的content-type數據類型為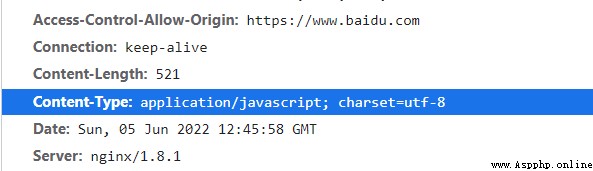
情況下。網頁根據utf-8編碼對數據進行解碼。但如果content-type數據類型為x-protobuf時,他不能根據protobuf協議去解析,所以會出現亂碼的行為。
接下來就進行到我們的正題吧。
首先本文會向你介紹protobuf協議的定義方式和解析方法,使你可以更深入的了解protobuf協議,在下節會介紹在爬蟲中遇到protobuf
協議如何解決的實踐操作。
protobuf (protocol buffer) 是谷歌內部的混合語言數據標准。通過將結構化的數據進行序列化(串行化),用於通訊協議、數據存儲等領域的語言無關、平台無關、可擴展的序列化結構數據格式。
如圖所示程序員編寫好proto文件的程序,然後編程成適應編程語言的包。這個過程可以通過下載下方鏈接。(後續會敘述這個過程)
https://github.com/protocolbuffers/protobuf/releases/
將proto文件編成你所需要的包。你需要做的是寫出proto文件的內容。
然後通過編譯成的包可以將數據和二進制之間進行轉換被稱為序列化和反序列化。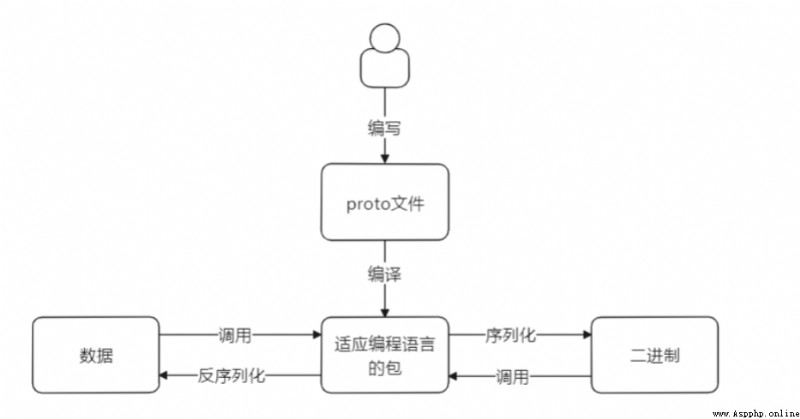
可能有人好奇,我們只是想把一個亂碼的轉換為我們能看懂的數據為什麼要學習編寫這個文件。那麼你可以先看再看一下上方的圖,如果你請求數據中攜帶參數是亂碼的,你要造出這種亂碼的數據那麼就需要去學習如何通過proto編譯出來的包(由於本文敘述是python語言那麼這個是py文件),來將數據轉換為二進制文件。以此來正常請求數據。
首先先寫一個簡單的proto文件
syntax = "proto3";
message Panda {
int32 id = 1;
string name = 2;
}
第一行確定proto使用的協議,現在大部分使用proto3而不是proto2
然後定義一個消息體裡面存放一些你需要的數據字段,
其中每個數據字段都有一種類型,一個名字和一個值構成。這個值不是你的數據中的值,而是查找定義這個數據字段的類型的識別符。我沒有嘗試過使用非數字的情況。具體的書寫格式可根據下方這個圖中proto的格式進行書寫。你可以根據自身的情況定義你需要的數據類型。
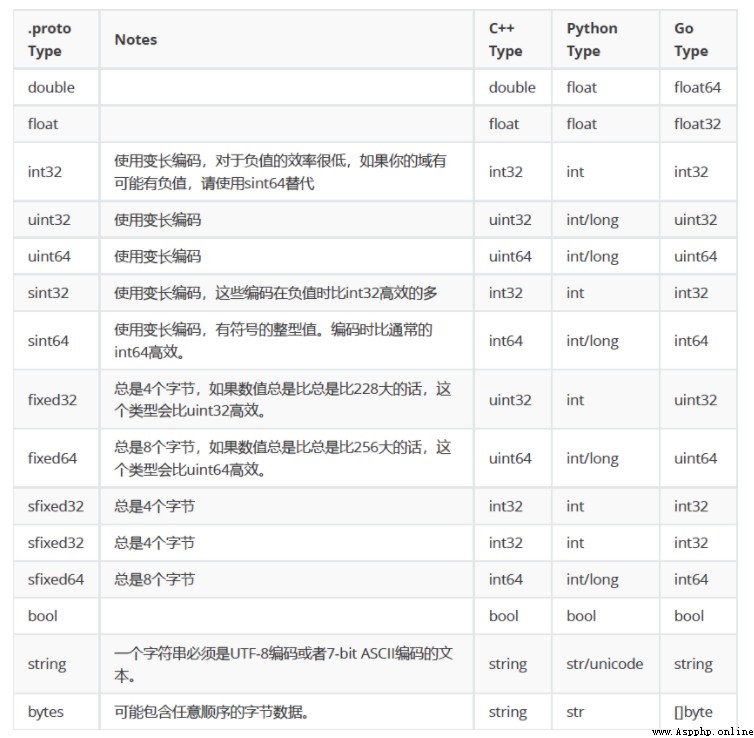
寫完成之後將文件名稱保存為xxx.proto文件。至此我們完成了編寫proto的過程,接下來我們需要將寫完的proto文件編譯成我們程序使用的包需要,下載https://github.com/protocolbuffers/protobuf/releases/
網址中的文件,下載windows版本
設置環境變量
運行cmd,找到proto文件處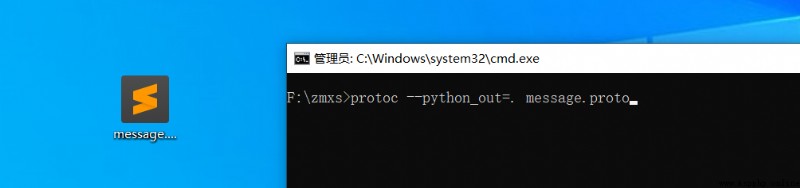
編譯成python文件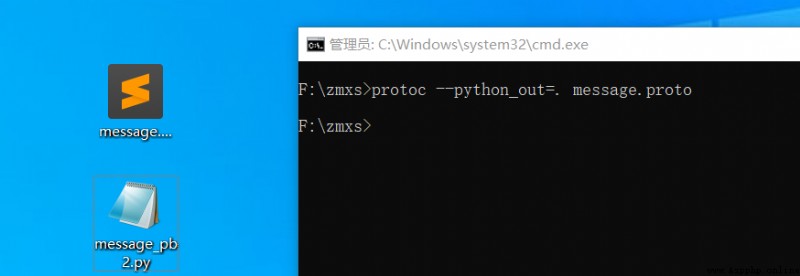
至此我們就已經完成proto文件的編譯了。
接下來我們開始將數據序列化為二進制
你需要安裝protobuf==3.20 google以及反序列化庫blackboxprotobuf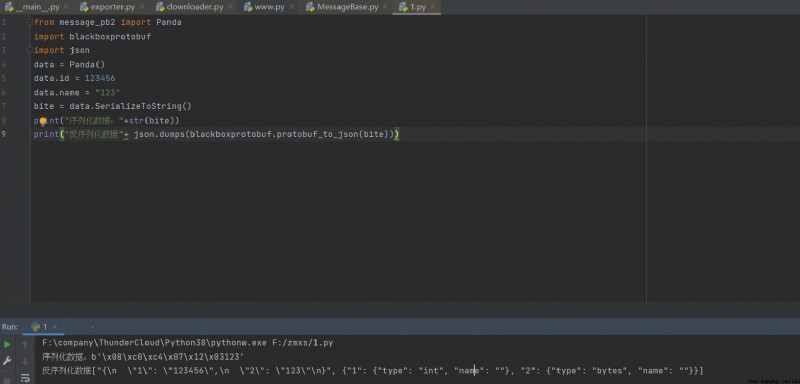
至此你已經可以完成proto文件的編寫,下面是一個稍微復雜一丟丟的代碼,你可以根據上方數據類型的表來看代碼。下方代碼可以很好的為你解析一些proto中嵌套數據的關系
syntax = "proto3";
message Message
{
int32 id_2 = 2;
int32 id_3 = 3;
Info id_5 = 5;
message Info
{
string id_1 = 1;
repeated int32 id_2 = 2 [packed=false];
int32 id_3 = 3;
Number id_5 = 5;
message Number
{
int32 id_2 = 2;
}
repeated int32 id_8 = 8 [packed=false];
int32 id_6 = 6;
int32 id_7 = 7;
int32 id_9 = 9;
int32 id_11 = 11;
}
string id_6 = 6;
}
調用結果展示
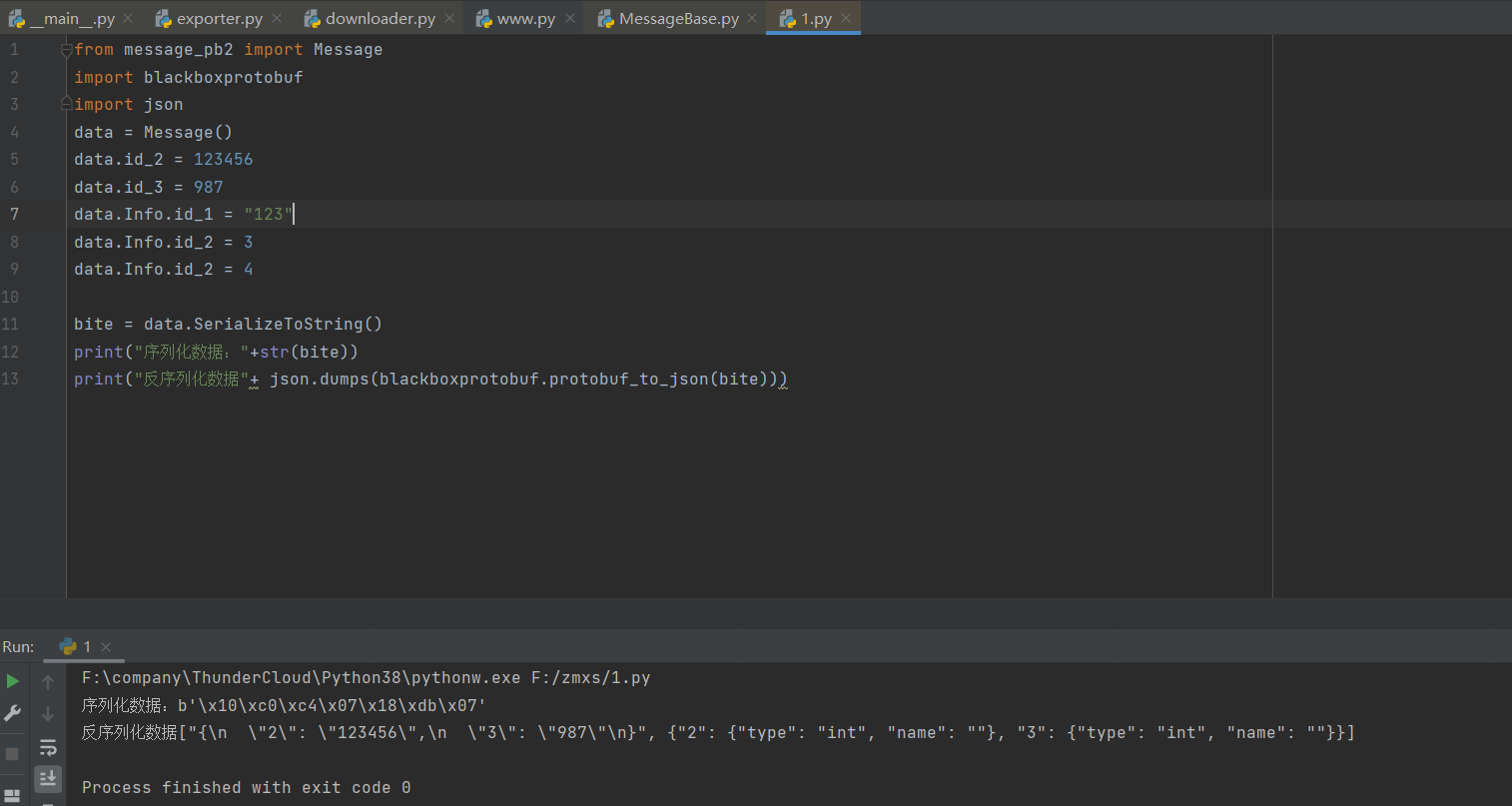
好了,上述描述為你解釋了如何編寫proto的過程,下面將會告訴你如何解析二進制proto的文件。先休息一下吧。
參考博客 https://www.cxymm.net/article/mine_song/76691817
首先我們要了解Varints編碼,然後通過Varints編碼了解protobuf的解碼過程
Varint 是一種緊湊的表示數字的方法。它用一個或多個字節來表示一個數字,值越小的數字使用越少的字節數。這能減少用來表示數字的字節數。
Varint 中的每個字節(最後一個字節除外)都設置了最高有效位(msb),這一位表示還會有更多字節出現。每個字節的低 7 位用於以 7 位組的形式存儲數字的二進制補碼表示,最低有效組首位。
如果用不到 1 個字節,那麼最高有效位設為 0 ,如下面這個例子,1 用一個字節就可以表示,所以 msb 為 0.
0000 0001
如果需要多個字節表示,msb 就應該設置為 1 。例如 300,如果用 Varint 表示的話:
1010 1100 0000 0010
如果按照正常的二進制計算的話,這個表示的是 88068 (65536 + 16384 + 4096 + 2048 + 4)。
但是如果按照 Varint 編碼的方式,首先看第一個字節:10101100,最高位是 1,剩下的是 0101100,msb 為 1,表示還有剩下的字節要讀取,第二個字節 00000010,最高位是 0,剩下的是 0000010,msb 為 0,表示後面沒有字節了。將兩個 7 為二進制數合在一起,就是目標值
0000010 0101100 => 4 + 8 + 32 + 256 = 300
這裡是小端模式,低位在前,先讀出來,高位在後,後讀出來。所以 0000010 要放在後面計算。
首先我們先寫一個簡單的protobuf編碼,如圖所示
然後將賦值
所以獲得二進制位
08 01 12 04 74 65 73 74
解析敘述我們解碼過程,在分析解碼的過程中,我們需要了解Wire Type,每一個消息項前面都會有對應的tag,才能解析對應的數據類型,表示tag的數據類型也是Varint。
tag的計算方式: (field_number << 3) | wire_type
每種數據類型都有對應的wire_type:
所以wire_type最多只能支持8種,目前有6種。
所以08 對應的二進制為 :
補位之後是
0 0001 000
為什麼這樣寫?
首先後三位是wire_type的類型 0 ,就代表是int32與我們上面定義的一致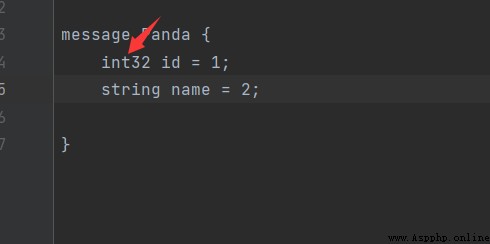
id 在protobuf中是不顯示的,只顯示後面標識符1
即如下圖所示: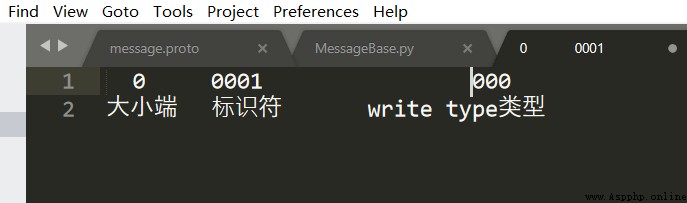
然後由於是int32類型所以我們直接取值為 01,這個是我們賦值的值,即
這樣開始分析字符串

分割0 0010 010
即標識符為2 類型Wire Type為Length-delimited string。
接下來跟著的值為字符串的長度為04那麼接下來的四個數據就是字符串的數據
即74 65 73 74 ASCII轉為為test至此編碼的過程就完成了。
你可以嘗試去學一下難度較高的解碼過程,下節,我們敘述如何在爬蟲中使用。
Spider-01-爬蟲介紹 Python 爬蟲的知識量不是特別大,但是需要不停和網頁打交道,每個網頁情況都有所差異,所以對應變能力有些要求 爬蟲准備工作 參考資料 精通Python爬蟲框架Scrap ...
爬蟲的實際例子: 搜索引擎(百度.谷歌.360搜索等). 伯樂在線. 惠惠購物助手. 數據分析與研究(數據冰山知乎專欄). 搶票軟件等. 什麼是網絡爬蟲: 通俗理解:爬蟲是一個模擬人類請求網站行為的程 ...
一.requests基於cookie操作 引言:有些時候,我們在使用爬蟲程序去爬取一些用戶相關信息的數據(爬取張三“人人網”個人主頁數據)時,如果使用之前requests模塊常規操作時,往往達不到我們 ...
一.urllib庫 urllib是Python自帶的一個用於爬蟲的庫,其主要作用就是可以通過代碼模擬浏覽器發送請求.其常被用到的子模塊在Python3中的為urllib.request和urllib. ...
HTTP協議: HTTP(Hypertext Transfer Protocol):即超文本傳輸協議.URL是通過HTTP協議存取資源的Internet路徑,一個URL對應一個數據資源. HTTP協議 ...
一.什麼是Scrapy? Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架,非常出名,非常強悍.所謂的框架就是一個已經被集成了各種功能(高性能異步下載,隊列,分布式,解析,持久化等) ...
深入淺出了解HTTP協議 HTTP(HyperText Transfer Protocol,超文本傳輸協議)是互聯網上應用最為廣泛的一種網絡協議.目前使用最普遍的一個版本是HTTP 1.1. HTTP ...
HTTP協議: HTTP(Hypertext Transfer Protocol):即超文本傳輸協議.URL是通過HTTP協議存取資源的Internet路徑,一個URL對應一個數據資源. HTTP協議 ...
一:Requests: 讓 HTTP 服務人類 雖然Python的標准庫中 urllib2 模塊已經包含了平常我們使用的大多數功能,但是它的 API 使用起來讓人感覺不太好,而 Requests 自稱 ...
介紹 #介紹:使用requests可以模擬浏覽器的請求,比起之前用到的urllib,requests模塊的api更加便捷(本質就是封裝了urllib3) #注意:requests庫發送請求將網頁內容下 ...
http://blog.csdn.net/akof1314/article/details/6968587 Delphi 完整的Bug決議工具EurekaLog的使用 標簽: delphi工具ftp ...
MySQL會出現中文亂碼的原因不外乎下列幾點: server本身設定問題,例如還停留在latin1 table的語系設定問題(包含character與collation) 客戶端程式(例如php)的連 ...
React-Native 入門指導系列教程目錄 一.准備工作 (已完成) 二.項目介紹與調試 三.CSS樣式與Flex布局 四.常用UI控件的使用 五.JSX在React-Native中的應用 六.事 ...
CREATE OR REPLACE PROCEDURE SCOTT.HTML_EMAIL( P_TO IN VARCHAR2, --收件人地址 P_SUBJECT IN VARCHAR2, --郵件主 ...
題目 解決代碼及點評 #include <stdio.h> #include <stdlib.h> #include <math.h> #i ...
沒用運用好式子...想想其實很簡單,首先應該分析,由於每次加一個LCM是大於等於其中任何一個數的,那麼我LCM加在哪個數上面,那個數就是會變成大的,這樣想,我們就知道,每個(x,y)對應就一種情況. ...
首先我們注意到ai<=50w 因為2*3*5*7*11*13*17=510510 所以其最多含有6個質因子 我們將每個數的貢獻分離, 添加就等於加上了跟這個數相關的互素對 刪除就等於減去了跟這個 ...
一.基本信息 標題:UML系統建模的分析和應用
 Python selenium combines with java script mouse and keyboard to control scroll bars
Python selenium combines with java script mouse and keyboard to control scroll bars
When browsing the web , Scroll
 Color black and white old photos based on OpenCV DNN module (with python/c++ source code)
Color black and white old photos based on OpenCV DNN module (with python/c++ source code)
Click below card , Focus on “