資源下載地址:https://download.csdn.net/download/sheziqiong/85787751
資源下載地址:https://download.csdn.net/download/sheziqiong/85787751
深度學習發展迅速,MNIST手寫數字數據集作為機器學習早期的數據集已經被公認為是機器學習界的果蠅實驗(Hinton某年),卷積神經網絡是識別圖像非常有效的一種架構,於是用CNN識別手寫數字也就成為了機器學習界的經典實驗。在這個repo中我會呈現最基本的CNN識別MNIST數據集過程。
主要步驟如下:
主要使用的語言和平台如下:
安裝包括Python語言和幾個必備的Pytorch包,使用Linux系統的安裝方式如下:
檢查一下Python語言:
$ python3 --version
Python 3.7.7
pip install torch
pip install torchvision
pip install matplotlib
完成了安裝,我們就可以開始訓練神經網絡識別數字了,第一步載入數據。
首先載入數據,全部MNIST手寫數字數據集來自於Yann LeCun網站,這裡我們使用torchvision.datasets裡已經有的MNIST數據集,與從網站下載效果相同:
from torchvision.datasets import MNIST
train_data = MNIST(root='./data', train=True, download=True, transform=transform)
test_data = MNIST(root='./data', train=False, download=True, transform=transform)
要想建立一個好的模型,首先我們要熟悉所處理的數據集是怎樣的,MNIST的數據集中每一張手寫數字圖片均是灰度的28*28的圖片,同上配有一個正確的0-9的label。先來一起看看訓練集和測試集:
print(train_data)
Dataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.5,), std=(0.5,))
)
print(test_data)
Dataset MNIST
Number of datapoints: 10000
Root location: ./data
Split: Test
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.5,), std=(0.5,))
)
訓練集中有60000個手寫數字及其label,測試集有10000個,接下來我們看看手寫數字長啥樣兒:
# 展示前40張手寫數字
import matplotlib.pyplot as plt
num_of_images = 40
for index in range(1, num_of_images + 1):
plt.subplot(4, 10, index)
plt.axis('off')
plt.imshow(train_data.data[index], cmap='gray_r')
plt.show()
這段code用matplotlib畫出前40張訓練集裡的手寫數字,在同一張圖裡呈現,圖如下:
我們的任務就是通過只看到手寫數字的圖片,建立一個CNN模型成功的識別出它是0-9的哪一個數字。
我們選擇的模型不算復雜,首先兩層卷積提取圖片的features,接下來兩層完全連接進行識別(注意最後一層的output是10個,對應數字0-9):
# 卷積網絡層
self.conv1 = nn.Conv2d(in_channels=1, out_channels=5, kernel_size=3, stride=1, padding=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=5, out_channels=10, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 完全連接網絡層
self.fc1 = nn.Linear(in_features=7*7*10, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=10)
有個卷積神經網絡的結構就可以定義forward函數了:
def forward(self, x):
"""forward."""
# 第一層卷積和取最大值
x = F.relu(self.conv1(x))
x = self.maxpool1(x)
# 第二層卷積和取最大值
x = F.relu(self.conv2(x))
x = self.maxpool2(x)
# 完全連接層
x = x.view(-1, 7*7*10)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return x
這樣就完成了CNN模型的建立。
先來看一下我們的模型有多少參數需要訓練(劇透:很多)
total_params = sum(p.numel() for p in model.parameters())
print(total_params)
64648
6萬多的參數等待訓練…首先定義Loss Function和optimizer,這裡使用CrossEntropy和Adam:
# 定義神經網絡和訓練參數
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=3e-4, weight_decay=0.001)
batch_size = 100
epoch_num = int(train_data.data.shape[0]) // batch_size
這裡的batch_size是100,也就意味著我們一共有60000個數據在訓練集裡,要訓練600個回合才能全部訓練完。訓練過程:
for epoch in range(1, epoch_num+1):
# 每個batch一起訓練,更新神經網絡weights
for idx, (img, label) in enumerate(train_loader):
optimizer.zero_grad()
output = model(img)
loss = criterion(output, label)
loss.backward()
optimizer.step()
print("Training Epoch {} Completed".format(epoch))
訓練的時間比較長,建議使用Amazon Web Service或者其他計算能力比較強的機器。
由於我的機器實在太弱了,我訓練了兩輪就掐掉了,也就意味著只用了200個訓練集的數字,估計表現會比較差(此處留下懸疑)

完成了訓練後我們的主要任務就已經完成了,接下來就要看看我們的CNN訓練的究竟好不好,測試集的10000個手寫數字對於我們的CNN模型而言是全新的數據,因此我們用測試集看看效果:
total = 0
correct = 0
for i, (test_img, test_label) in enumerate(test_loader):
# 正向通過神經網絡得到預測結果
outputs = model(test_img)
predicted = torch.max(outputs.data, 1)[1]
print("Correct label is", test_label)
print("Prediction is", predicted)
# 總數和正確數
total += len(test_label)
correct += (predicted == test_label).sum()
accuracy = correct / total
print('Testing Results:\n Loss: {} \nAccuracy: {} %'.format(loss.data, accuracy*100))
一起來看看測試結果: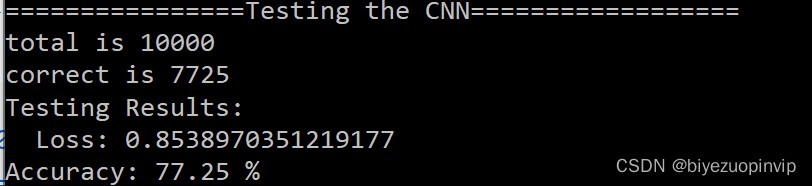
竟然高達77%……我才只用了200個訓練集。
資源下載地址:https://download.csdn.net/download/sheziqiong/85787751
資源下載地址:https://download.csdn.net/download/sheziqiong/85787751