In the process of crawling a website , Discover by pressing... Directly from the browser F12 The console of xpath You can't get an address , Output an empty list , Rechecked xpath There is no problem with path discovery .
Sample web site :https://so.gushiwen.cn/shiwenv_4ef2774ed20a.aspx
Demonstrate crawling content ( Get the appreciation text here ):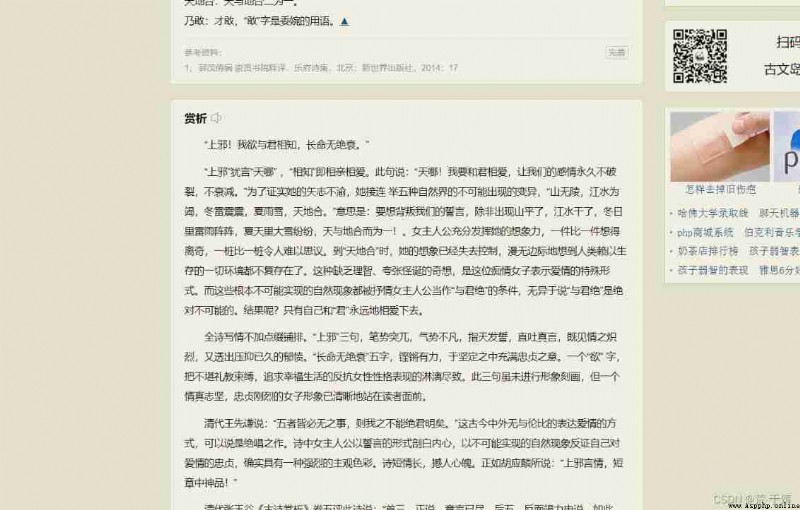
Initial code :
from lxml import etree
from requests import Session
url = 'https://so.gushiwen.cn/shiwenv_4ef2774ed20a.aspx'
session = Session()
pageContent = session.get(url).content.decode("utf-8")
xpath = etree.HTML(pageContent)
# complete xpath: /html/body/div[2]/div[1]/div[6]/div[1]/p[2]/text()
content = xpath.xpath('//*[@id="shangxiquan1274"]/div[1]/p[2]/text()')
print(" Browser copy xpath Get content :",content)
After the code runs, it is found that the output empty list has nothing .
Then I write the obtained page contents into a file , Reopen this file with your browser .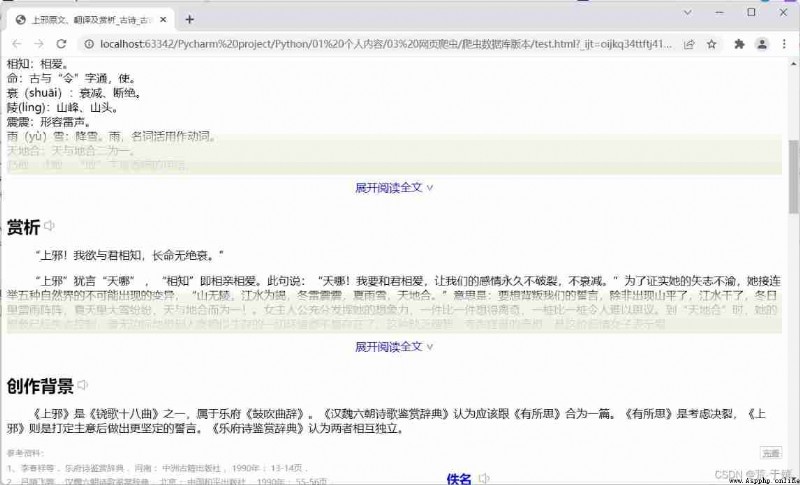
Although there is a problem with the page display , however " appreciation " The text content of this paragraph is still in , This indicates that this data exists on the page . And not through the interface .
Then I copied it here again xpath Address , Pasted into the code , Found and copied from the original website xpath The address is different
Rerun code , Successfully obtained the content
from lxml import etree
from requests import Session
url = 'https://so.gushiwen.cn/shiwenv_4ef2774ed20a.aspx'
session = Session()
# From original site F12 Console copy xpath Address fragment
pageContent = session.get(url).content.decode("utf-8")
xpath = etree.HTML(pageContent)
# complete xpath: /html/body/div[2]/div[1]/div[6]/div[1]/p[2]/text()
content = xpath.xpath('//*[@id="shangxiquan1274"]/div[1]/p[2]/text()')
print(" Browser copy xpath Get content :",content)
# write file
with open("test.html",mode="w",encoding="utf-8") as w:
w.write(pageContent)
# Copied from a page opened in a local file xpath Address generation fragment
xpath = etree.HTML(pageContent)
# complete xpath: /html/body/div[2]/div[1]/div[5]/div/p[2]/text()
content = xpath.xpath('//*[@id="shangxi1274"]/div/p[2]/text()')
print(" Revised xpath Get content :",content)
Running results

two xpath Address contrast :
# Problematic
The full path :/html/body/div[2]/div[1]/div[6]/div[1]/p[2]/text()
# Available for local replication xpath Address
The full path :/html/body/div[2]/div[1]/div[5]/div/p[2]/text()
# Relative paths
# Problematic
//*[@id="shangxiquan1274"]/div[1]/p[2]/text()
# Available for local replication xpath Address
//*[@id="shangxi1274"]/div/p[2]/text()
I don't know why , But if you find that you can't get content, most of the reasons are xpath The address is wrong , If there is no problem, you can First save the captured page to the local , Then use the browser to open the local file and copy again xpath Address .
 Computer graduation design Python+django online food ordering system (source code + system + mysql database + Lw document)
Computer graduation design Python+django online food ordering system (source code + system + mysql database + Lw document)
Project IntroductionThis paper