最近因需要用Excel電子表格處理數據,使用了其它一些方式處理Excel文件數據,這是學習筆記的整理。
Excel2003及以前版:列數最大256(2的8次方)列,行數最大65536(2的16次方)行;Excel2007及以後版:列數最大16384(2的14次方),行數最大1048576(2的20次方);
獲取Excel最大行和最大列的方法:
啟動Excel後通過快捷鍵Ctrl+方向鍵(←↑↓→),可以定位到最左、最上、最下、最右的單元格,從而可以看到行和列的最大值。
Python中有很多庫可以操作Excel,像pandas、xlrd、xlwt、xlutils、openpyxl 等。
xlrd 庫:讀取 Excel 文件
xlwt 庫:寫入 Excel 文件
xlutils 庫:操作 Excel 文件的實用工具,如復制、分割、篩選等
xlrd、xlwt、xlutils 庫可以讀寫操作後綴為xls的excel文件。
openpyxl庫 :操作xlsx後綴的excel文件,還要用到這個庫。
本文主要介紹pandas。特別提示:
Pandas 是基本NumPy 的軟件庫,因此安裝Pandas 之前需要先安裝NumPy。默認的pandas不能直接讀寫excel文件,需要安裝讀、寫庫即xlrd、xlwt才可以實現xls後綴的excel文件的讀寫,要想正常讀寫xlsx後綴的excel文件,還需要openpyxl 。
pandas官網 https://pandas.pydata.org/
pandas 中文教程 https://www.gairuo.com/p/pandas-tutorial
Pandas是一個Python的核心數據分析支持庫,它提供了強大的一維數組和二維數組處理能力,其非常擅長與處理二維表結構,帶行列標簽的矩陣數據,時間序列數據。Pandas提供的兩個主要數據結構一維數組(Series)和二維數組(DataFrame)強力的支撐著當今金融、統計、社會科學、工程等諸多領域的數據分析工作。通過Pandas我們可以方便的操作數據的增、查、改、刪、合並、重塑、分組、統計分析,此外Pandas還提供了非常成熟的I/O工具,用於讀取文本文件,excel文件,數據庫等不同來源數據,利用超快的HDF5格式保存/加載數據。
Pandas中的數據結構和Excel文檔屬性的對應關系
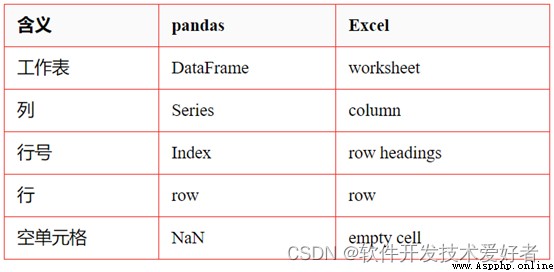
* pandas 中的 DataFrame 類似於 Excel 的工作表。但是Excel 工作簿可以包含多個工作表,而 pandas DataFrame 是獨立存在的。
* Series 表示 DataFrame 的一列數據結構,使用Series類似於引用電子表格的一列。
每個 DataFrame 和 Series 都有一個Index,它是數據行上的標簽。
* 在 pandas 中,如果未指定索引,則默認使用 RangeIndex(第一行 = 0,第二行 = 1,依此類推),類似於電子表格中的行號(數字)。
pandas 也可以將索引設置為一個(或多個)唯一值,這就像在工作表中擁有一個用作行標識符的列。
索引值是固定的,所以如果對 DataFrame 中的行重新排序,行的標簽也不會改變。
Python模塊(庫、包)安裝命令格式:
[py -X.Y -m] pip install [-i 鏡像網址] 模塊(庫、包)名
其中[]部分表示可先的
若安裝了多個python版本,為指定Python版本安裝模塊(庫、包),X.Y代表Python版本,多余的部分捨棄如3.8.1取3.8,3.10.5取3.10,即只取第二個點前的部分。僅安裝了一個python版本不需要。
常用的鏡像網址
清華:https://pypi.tuna.tsinghua.edu.cn/simple
阿裡雲:https://mirrors.aliyun.com/pypi/simple/
中國科技大學 https://pypi.mirrors.ustc.edu.cn/simple/
【詳見 :https://blog.csdn.net/cnds123/article/details/104393385】
安裝Pandas 之前需要先安裝NumPy,
在CMD中輸入
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ numpy
我已安裝過NumPy,在此跳過
【查看python第三方模塊(庫、包)是否安裝及其版本號
[py -X.Y -m] pip list
其中[]部分表示可選的,若安裝了多個python版本,指定Python版本,查看由X.Y指定python版本關聯的模塊(庫、包)情況】
Pandas 安裝,打開cmd窗口,輸入:
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ Pandas
參見下圖:
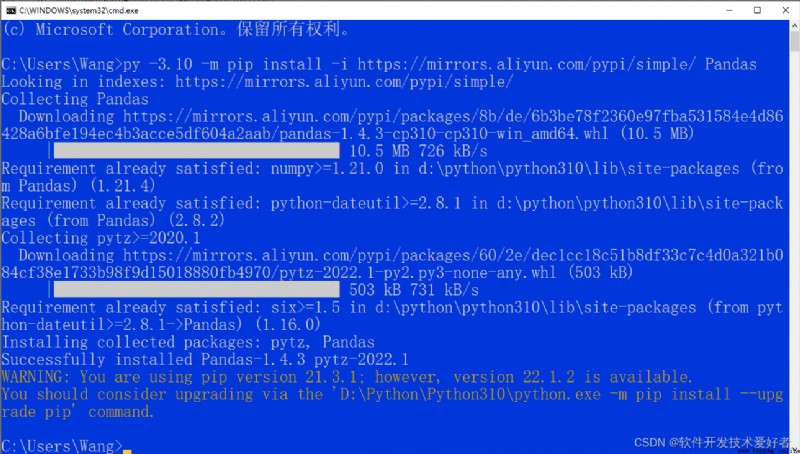
Successfully 表示成功了
WARNING部分大意是又可用的pip新的版本可以進行升級,可按提示中引號中的命令升級操作,也可不用管它
xlrd、xlwt、xlutils、openpyxl庫的安裝可參照上面的方法
安裝成功後,我們就可以導入 pandas使用了。
Pandas的基本操作
*數據讀取
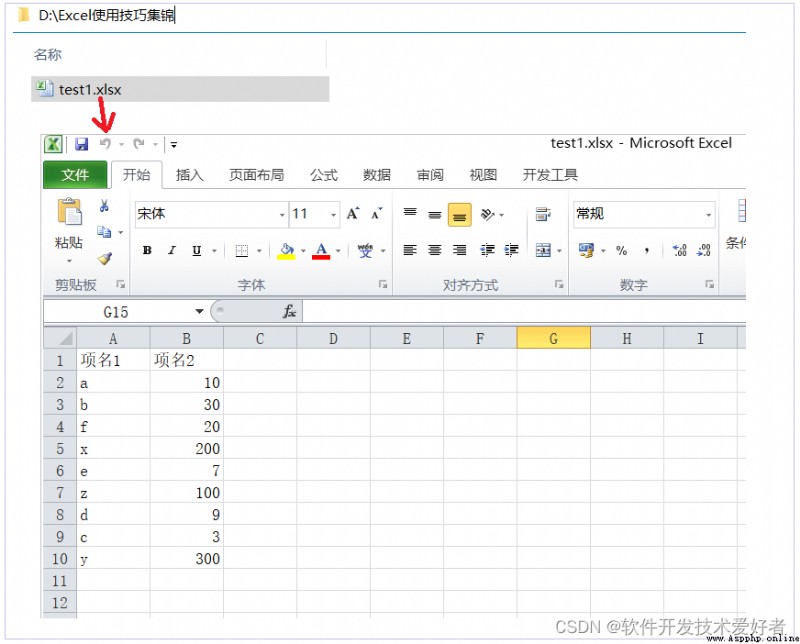
pandas讀取excel的例子
test1.xlsx的內容如下:
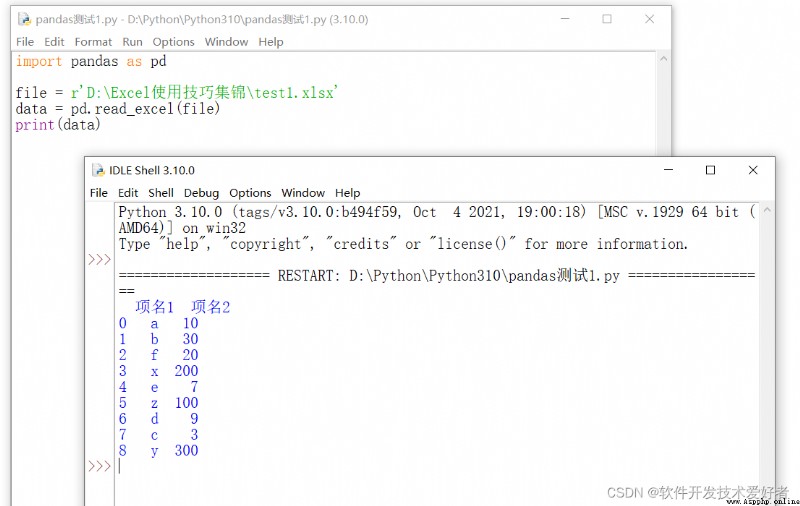
源碼如下:
import pandas as pd
file = r'D:\Excel使用技巧集錦\test1.xlsx'
data = pd.read_excel(file)
print(data)
運行結果:
提示:
引號中是excel表格的文件路徑和文件名,前面加“r”是為了防止python解釋器對字符串字符轉義處理。如果字符串中出現“\t”,不加“r”的話“\t”就會被轉義,代表指制表符,代表著四個空格,也就是一個tab鍵,而加了“r”之後“\t”就能保留原有的樣子。
file = r'D:\Excel使用技巧集錦\test1.xlsx' ,若直接寫為file ='D:\Excel使用技巧集錦\test1.xlsx'將報錯!但可改寫為 file = 'D:\\Excel使用技巧集錦\\test1.xlsx' 或file = 'D:/Excel使用技巧集錦/test1.xlsx'
read_excel()方法將Excel文件讀取到pandas DataFrame中
有很多的參數詳細介紹https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
常用的參數有
第一個參數指定帶路徑的文件名(如果需要打開的文件在當前路徑下,可以省略文件路徑只寫文件名)
sheet_name參數可以指定sheet頁名稱或位置,字符串用於工作表名稱。 整數用於零索引工作表位置,缺省默認0即第一個位置的sheet,如:
df= pd.read_excel(r'D:\Excel使用技巧集錦\test1.xlsx' [, sheet_name='sheet1'])
處理數據
#導入pandas庫
import pandas as pd
# 讀取excel 文件
df= pd.read_excel(r'D:\Excel使用技巧集錦\test1.xlsx' [, sheet_name='sheet1'])
# 獲取列數據
df['column_name']
#獲取多列 多列中,df[] 括號裡邊是一個列表
df[['columns_name1','columns_name2']]
# 獲取行數據
df.loc[Line_number [,'column_name']]
其中,Line_number是行號,column_name是列名,可缺省,列名缺省獲取整行
#整體數據排序
df.sort_values(by='columns_name',ascending = False)
#刪除重復數據
df.drop_duplicates()
to_excel()方法將DataFrame 的內容保存到excel文件
to_excel()方法參數很多 可參見https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html?highlight=to_excel
常用的參數是指定帶路徑的文件名(如果需要打開的文件在當前路徑下,可以省略文件路徑只寫文件名)
簡單示例如下: