Recently, I used Excel Spreadsheets process data , There are other ways to deal with Excel File data , This is the arrangement of study notes .
Excel2003 And previous editions : Maximum number of columns 256(2 Of 8 Power ) Column , Maximum number of rows 65536(2 Of 16 Power ) That's ok ;Excel2007 And later versions : Maximum number of columns 16384(2 Of 14 Power ), Maximum number of rows 1048576(2 Of 20 Power );
obtain Excel Maximum row and maximum column methods :
start-up Excel Then press the shortcut key Ctrl+ Direction key (←↑↓→), Can be located to the leftmost 、 At the top 、 At the bottom 、 The rightmost cell , So you can see the maximum values of rows and columns .
Python There are many libraries to operate Excel, image pandas、xlrd、xlwt、xlutils、openpyxl etc. .
xlrd library : Read Excel file
xlwt library : write in Excel file
xlutils library : operation Excel File utility , Like copying 、 Division 、 Screening, etc
xlrd、xlwt、xlutils The library can be read and written with the suffix xls Of excel file .
openpyxl library : operation xlsx Suffix excel file , Also use this library .
This paper mainly introduces pandas. hot tip :
Pandas It's basic NumPy Software library , So the installation Pandas It needs to be installed before NumPy. default pandas Can't read or write directly excel file , Need to install read 、 Writing a library is xlrd、xlwt To achieve xls Suffix excel Reading and writing of documents , To read and write normally xlsx Suffix excel file , It also needs to be openpyxl .
pandas Official website https://pandas.pydata.org/
pandas Chinese Course https://www.gairuo.com/p/pandas-tutorial
Pandas It's a Python The core data analysis support library , It provides powerful one-dimensional array and two-dimensional array processing capabilities , It is very good at dealing with two-dimensional table structures , Matrix data with row and column labels , time series data .Pandas The two main data structures provided are one-dimensional arrays (Series) And two dimensional arrays (DataFrame) It strongly supports today's finance 、 Statistics 、 Social Sciences 、 Data analysis in engineering and many other fields . adopt Pandas We can easily operate the increase of data 、 check 、 Change 、 Delete 、 Merge 、 restore 、 grouping 、 Statistical analysis , Besides Pandas It also provides very mature I/O Tools , Used to read text files ,excel file , Database and other data from different sources , Use the super fast HDF5 Format preservation / Load data .
Pandas Data structure and Excel Correspondence of document attributes
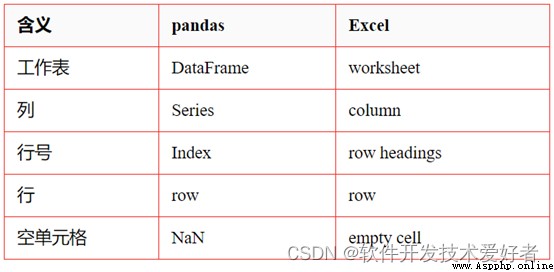
* pandas Medium DataFrame Be similar to Excel The worksheet for . however Excel A workbook can contain multiple worksheets , and pandas DataFrame It's independent .
* Series Express DataFrame A column of data structure , Use Series Similar to referencing a column in a spreadsheet .
Every DataFrame and Series There is one. Index, It is the label on the data row .
* stay pandas in , If the index is not specified , It is used by default RangeIndex( first line = 0, The second line = 1, And so on ), Similar to row numbers in spreadsheets ( Numbers ).
pandas You can also set the index to a ( Or more ) The only value , It's like having a column in a worksheet that acts as a row identifier .
The index value is fixed , So if you're right DataFrame Reorder rows in , The label of the row will not change .
Python modular ( library 、 package ) Install command format :
[py -X.Y -m] pip install [-i Image URL ] modular ( library 、 package ) name
among [] The partial expression can be first
If multiple... Are installed python edition , For a given Python Version installation module ( library 、 package ),X.Y representative Python edition , Discard the superfluous part, such as 3.8.1 take 3.8,3.10.5 take 3.10, That is, only the part before the second point . Only one... Is installed python The version does not need .
Common mirror URL
tsinghua :https://pypi.tuna.tsinghua.edu.cn/simple
Alibaba cloud :https://mirrors.aliyun.com/pypi/simple/
University of science and technology of China https://pypi.mirrors.ustc.edu.cn/simple/
【 See :https://blog.csdn.net/cnds123/article/details/104393385】
install Pandas It needs to be installed before NumPy,
stay CMD Input in
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ numpy
I have installed NumPy, Skip here
【 see python Third-party module ( library 、 package ) Whether to install and its version number
[py -X.Y -m] pip list
among [] Part means optional , If multiple... Are installed python edition , Appoint Python edition , View by X.Y Appoint python Module associated with version ( library 、 package ) situation 】
Pandas install , open cmd window , Input :
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ Pandas
See the figure below :
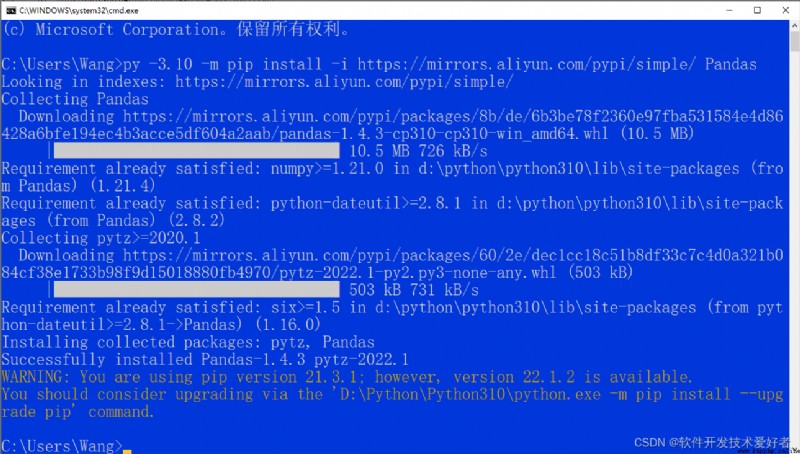
Successfully It means success
WARNING Part of the general idea is also available pip The new version can be upgraded , You can follow the command in quotation marks in the prompt to upgrade the operation , Don't worry about it
xlrd、xlwt、xlutils、openpyxl For the installation of the library, please refer to the above method
After successful installation , We can import pandas Used .
Pandas Basic operation
* data fetch
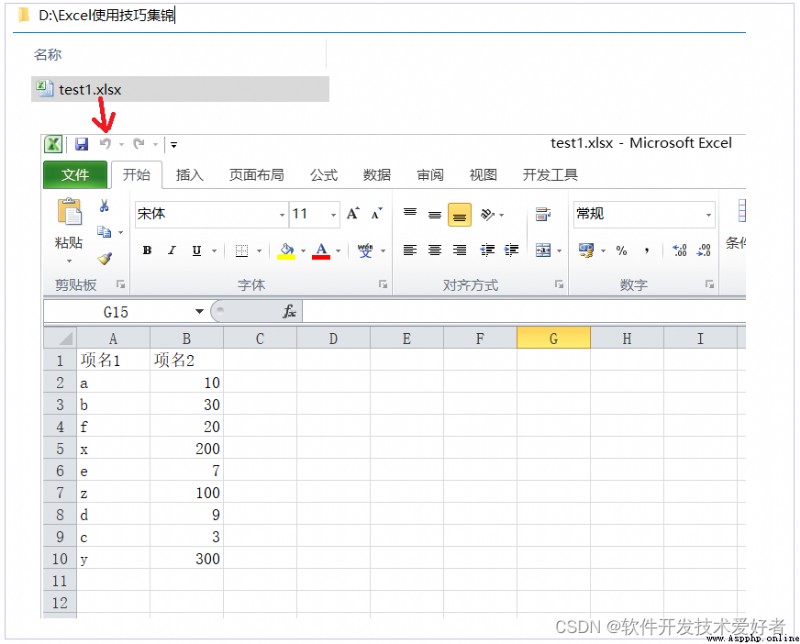
pandas Read excel Example
test1.xlsx Is as follows :
Source code is as follows :
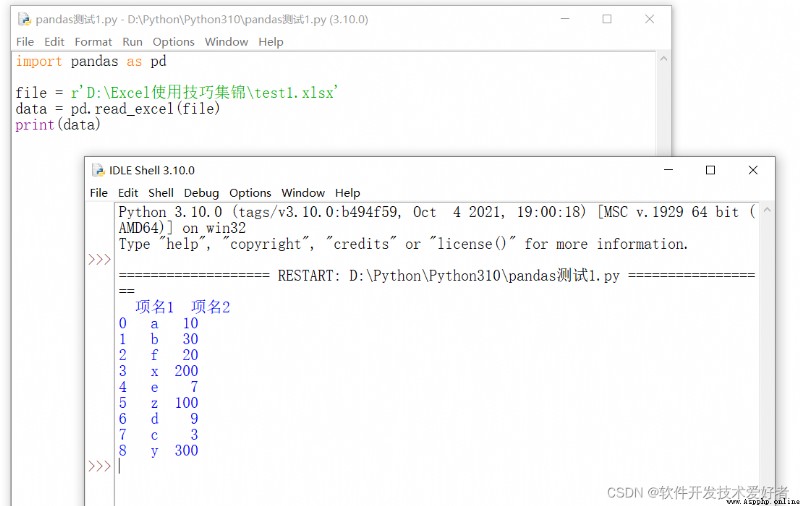
import pandas as pd
file = r'D:\Excel Tips for use \test1.xlsx'
data = pd.read_excel(file)
print(data)
Running results :
Tips :
In quotation marks is excel File path and file name of the table , Add in front “r” To prevent python The interpreter handles string character escape . If... Appears in the string “\t”, No addition “r” Words “\t” Will be transferred , Represents the tab character , Represents four spaces , That's one tab key , And added “r” after “\t” You can keep the original look .
file = r'D:\Excel Tips for use \test1.xlsx' , If it's written as file ='D:\Excel Tips for use \test1.xlsx' Will be an error ! But it can be rewritten as file = 'D:\\Excel Tips for use \\test1.xlsx' or file = 'D:/Excel Tips for use /test1.xlsx'
read_excel() Method take Excel File read to pandas DataFrame in
There are many parameters to describe in detail https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
Common parameters are
The first parameter specifies the file name with the path ( If the file to be opened is in the current path , You can omit the file path and write only the file name )
sheet_name Parameters can be specified sheet Page name or location , String is used for sheet name . Integers are used for zero index sheet locations , Default default 0 That is, in the first position sheet, Such as :
df= pd.read_excel(r'D:\Excel Tips for use \test1.xlsx' [, sheet_name='sheet1'])
Processing data
# Import pandas library
import pandas as pd
# Read excel file
df= pd.read_excel(r'D:\Excel Tips for use \test1.xlsx' [, sheet_name='sheet1'])
# Get column data
df['column_name']
# Get multiple columns In multiple columns ,df[] Inside the brackets is a list
df[['columns_name1','columns_name2']]
# Get row data
df.loc[Line_number [,'column_name']]
among ,Line_number Is the line number ,column_name Is the column name , It can be defaulted , Column name gets the whole row by default
# Overall data sorting
df.sort_values(by='columns_name',ascending = False)
# Delete duplicate data
df.drop_duplicates()
to_excel() Method take DataFrame Save the contents of to excel file
to_excel() There are many method parameters See also https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html?highlight=to_excel
A common parameter is to specify a file name with a path ( If the file to be opened is in the current path , You can omit the file path and write only the file name )
A simple example is as follows :