requests library 、re、html、xlwt
from bs4 import BeautifulSoup # Parse web pages
import re # Regular expressions , Text matching
import urllib.request,urllib.error # To develop url, Get web data
import xlwt # Conduct excel operation
import sqlite3 # Conduct SQLite Database operation
def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36"
} # Disguised as a web page , Request Web Information
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
url: The URL you want to crawl
User-Agent Access method :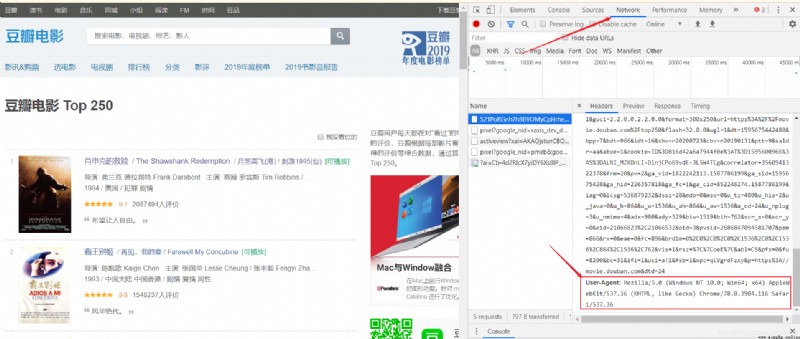
# Movie links
findLink = re.compile(r'<a href="(.*?)">')
# Cover picture
findImgSrc = re.compile(r'<img.*src="(.*?)".*>',re.S)
# The movie name
findTitle = re.compile(r'<span class="title">(.*)</span>')
# score
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# Number of evaluators
findJudge = re.compile(r'<span>(\d*) People comment on </span>')
# survey
findInq = re.compile(r'<span class="inq">(.*)</span>')
# Movie details
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
By checking the source code of the web page , Find out what you want to get “ Format ”, Use regular expressions to get data
(.*?) Is the data to be obtained , You cannot get without parentheses
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet(' Watercress movie Top250',cell_overwrite_ok=True)
book.save(' Watercress movie Top250.xls')
After creation , Import data into excel In the table
【 Complete code 】
from bs4 import BeautifulSoup # Parse web pages
import re # Regular expressions , Text matching
import urllib.request,urllib.error # To develop url, Get web data
import xlwt # Conduct excel operation
import sqlite3 # Conduct SQLite Database operation
def main():
baseurl = "https://movie.douban.com/top250?start="
# Crawl to the web
datalist = getData(baseurl)
# Save the data
savepath = " Watercress movie Top250.xls"
saveData(datalist,savepath)
# Movie links
findLink = re.compile(r'<a href="(.*?)">')
# Cover picture
findImgSrc = re.compile(r'<img.*src="(.*?)".*>',re.S)
# The movie name
findTitle = re.compile(r'<span class="title">(.*)</span>')
# score
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# Number of evaluators
findJudge = re.compile(r'<span>(\d*) People comment on </span>')
# survey
findInq = re.compile(r'<span class="inq">(.*)</span>')
# Movie details
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
# Crawl to the web
def getData(baseurl):
datalist = []
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
# Parse the data one by one
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data = []
item = str(item)
Link = re.findall(findLink,item)[0]
data.append(Link)
ImgSrc = re.findall(findImgSrc,item)[0]
data.append(ImgSrc)
Title = re.findall(findTitle,item)
if len(Title)==2:
ctitle = Title[0]
data.append(ctitle)
otitle = Title[1].replace("/","")
data.append(otitle)
else:
data.append(Title[0])
data.append(' ')
Rating = re.findall(findRating,item)[0]
data.append(Rating)
Judge = re.findall(findJudge,item)[0]
data.append(Judge)
Inq = re.findall(findInq,item)
if len(Inq) !=0:
Inq = Inq[0].replace(".","")
data.append(Inq)
else:
data.append(" ")
Bd = re.findall(findBd,item)[0]
Bd = re.sub('<br(\s+)?/>(\s+)?'," ",Bd)
data.append(Bd.strip())
datalist.append(data) # Store the processed movie information in datalist in
# Parse web pages
return datalist
# Get and specify a web page content
def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36"
} # Disguised as a web page , Request Web Information
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
# Save the data
def saveData(datalist,savepath):
print("save....")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet(' Watercress movie Top250',cell_overwrite_ok=True)
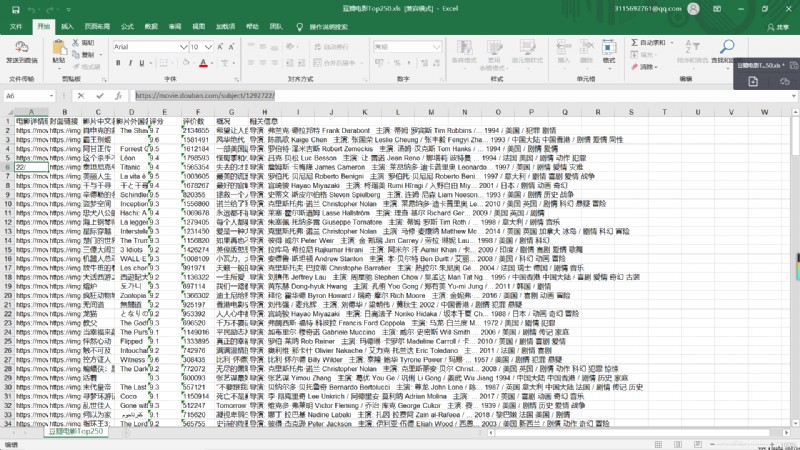
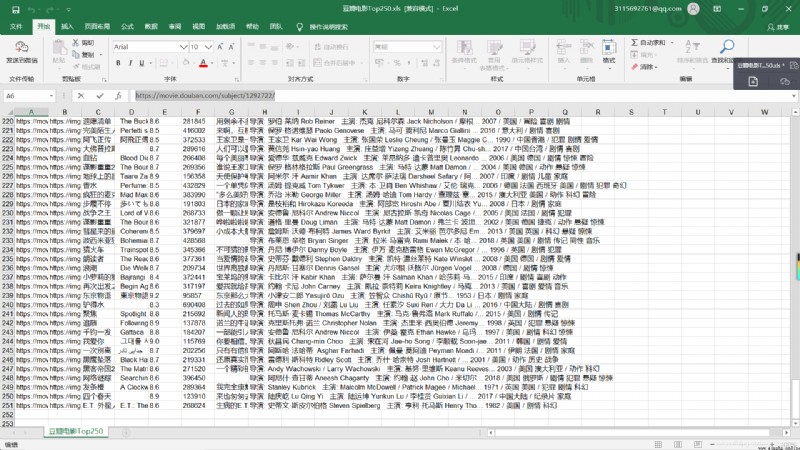
col = (" Movie details link "," Cover link "," The Chinese name of the film "," The foreign name of the film "," score "," Evaluation number "," survey "," Related information ","")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print(" The first %d strip "%(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(' Watercress movie Top250.xls')
main()
print(" Crawling over ")
【 Running results 】