requests庫、re、html、xlwt
from bs4 import BeautifulSoup #解析網頁
import re #正則表達式,進行文字匹配
import urllib.request,urllib.error #制定url,獲取網頁數據
import xlwt #進行excel操作
import sqlite3 #進行SQLite數據庫操作
def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36"
} #偽裝成網頁的形式,請求網頁信息
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
url:想要爬取的網址
User-Agent獲取方法: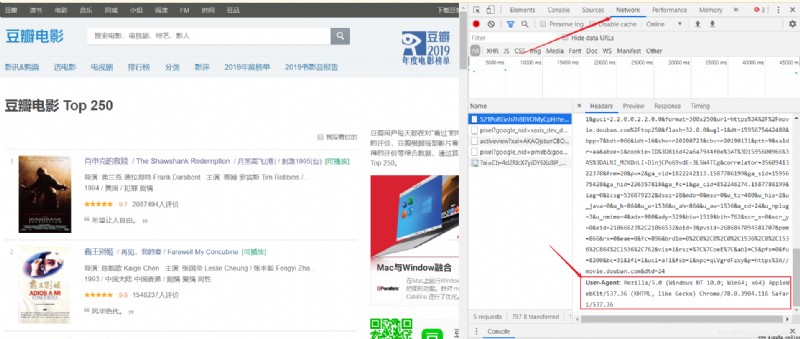
#電影鏈接
findLink = re.compile(r'<a href="(.*?)">')
#封面圖片
findImgSrc = re.compile(r'<img.*src="(.*?)".*>',re.S)
#電影名稱
findTitle = re.compile(r'<span class="title">(.*)</span>')
#評分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#評價人數
findJudge = re.compile(r'<span>(\d*)人評價</span>')
#概況
findInq = re.compile(r'<span class="inq">(.*)</span>')
#電影詳細內容
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
通過查看網頁源代碼,找出要獲取數據的“格式”,用正則表達式來獲取數據
(.*?)是要獲取的數據,不加括號則無法獲取
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet('豆瓣電影Top250',cell_overwrite_ok=True)
book.save('豆瓣電影Top250.xls')
創建完成後,將數據導入到excel表中
【完整代碼】
from bs4 import BeautifulSoup #解析網頁
import re #正則表達式,進行文字匹配
import urllib.request,urllib.error #制定url,獲取網頁數據
import xlwt #進行excel操作
import sqlite3 #進行SQLite數據庫操作
def main():
baseurl = "https://movie.douban.com/top250?start="
#爬取網頁
datalist = getData(baseurl)
#保存數據
savepath = "豆瓣電影Top250.xls"
saveData(datalist,savepath)
#電影鏈接
findLink = re.compile(r'<a href="(.*?)">')
#封面圖片
findImgSrc = re.compile(r'<img.*src="(.*?)".*>',re.S)
#電影名稱
findTitle = re.compile(r'<span class="title">(.*)</span>')
#評分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#評價人數
findJudge = re.compile(r'<span>(\d*)人評價</span>')
#概況
findInq = re.compile(r'<span class="inq">(.*)</span>')
#電影詳細內容
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
#爬取網頁
def getData(baseurl):
datalist = []
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
#逐一解析數據
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data = []
item = str(item)
Link = re.findall(findLink,item)[0]
data.append(Link)
ImgSrc = re.findall(findImgSrc,item)[0]
data.append(ImgSrc)
Title = re.findall(findTitle,item)
if len(Title)==2:
ctitle = Title[0]
data.append(ctitle)
otitle = Title[1].replace("/","")
data.append(otitle)
else:
data.append(Title[0])
data.append(' ')
Rating = re.findall(findRating,item)[0]
data.append(Rating)
Judge = re.findall(findJudge,item)[0]
data.append(Judge)
Inq = re.findall(findInq,item)
if len(Inq) !=0:
Inq = Inq[0].replace("。","")
data.append(Inq)
else:
data.append(" ")
Bd = re.findall(findBd,item)[0]
Bd = re.sub('<br(\s+)?/>(\s+)?'," ",Bd)
data.append(Bd.strip())
datalist.append(data) #把處理好的一個電影信息存儲到datalist中
#解析網頁
return datalist
#獲取指定一個網頁內容
def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36"
} #偽裝成網頁的形式,請求網頁信息
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#保存數據
def saveData(datalist,savepath):
print("save....")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet('豆瓣電影Top250',cell_overwrite_ok=True)
col = ("電影詳情鏈接","封面鏈接","影片中文名","影片外國名","評分","評價數","概況","相關信息","")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d條"%(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save('豆瓣電影Top250.xls')
main()
print("爬取完畢")
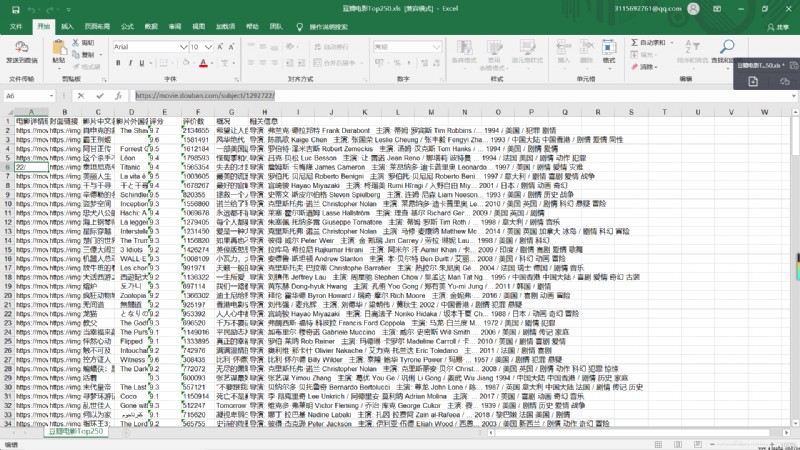
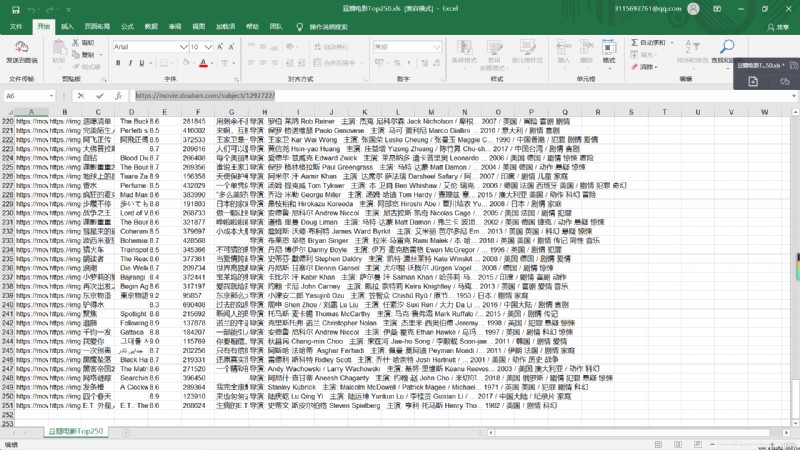
【運行結果】