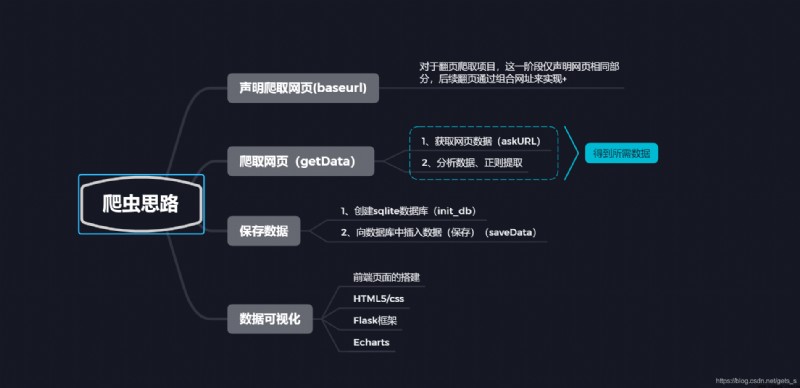
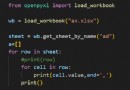
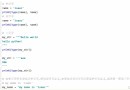
【 Code example 】
import re
from bs4 import BeautifulSoup
import urllib.request,urllib.error
import sqlite3
def main():
# Declare the blog URL you want to crawl
baseurl = "https://blog.csdn.net/gets_s/article/list/"
# get data
datalist = getData(baseurl)
# Save the data
dbpath = "blogs.db"
#print(datalist)
saveData(dbpath,datalist)
# Regular expressions
findtitle = re.compile(r'<a .*>.*</span>(.*?)</a>',re.S)
findlink = re.compile(r'<a.*href="(.*?)"')
findtime = re.compile(r'<span class="date">(.*?)</span>')
findnum = re.compile(r'<span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountBlack.png"/>(.*?)</span>')
def getData(baseurl):
datalist = []
for i in range(1,3):
url = baseurl + str(i)
html = askURL(url)
# Parse the obtained web page code
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="article-item-box csdn-tracking-statistics"):
item = str(item)
#print(item)
data = []
title = re.findall(findtitle,item)
title = title[0].replace("\n","")
#print(title)
data.append(title)
link = re.findall(findlink,item)[0]
#print(link)
data.append(link)
time = re.findall(findtime,item)[0]
#print(time)
data.append(time)
num = re.findall(findnum,item)[0]
#print(num)
data.append(num)
datalist.append(data)
return datalist
def askURL(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.163Safari / 537.36"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def saveData(dbpath,datalist):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
sql = ''' insert into blogs( title, blog_link, sigup_time, num) values('%s','%s','%s','%s') '''%(data[0],data[1],data[2],data[3])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = ''' create table blogs ( id integer primary key autoincrement, title text, blog_link text, sigup_time numeric, num numeric ) '''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ == "__main__":
main()
【 Running results 】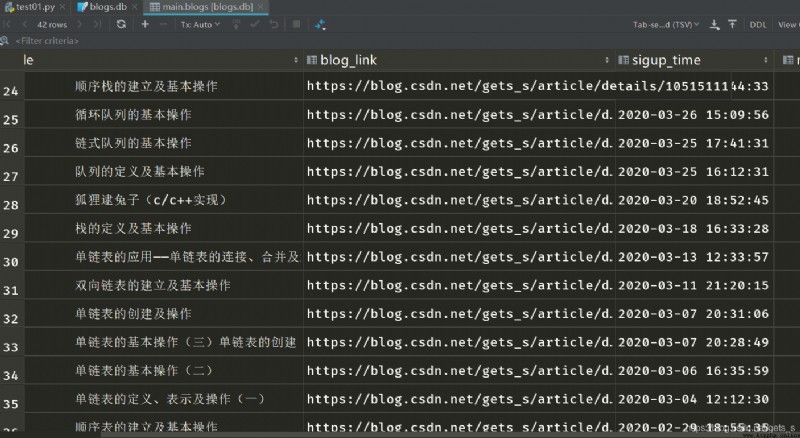
【 Thinking summary 】